こんにちは。キャディ株式会社の Analysis Platform Group で MLOpsエンジニアを務めているAmaniです。 普段はキャディの各サービスの裏側で稼働する機械学習基盤やバックエンドの開発、およびアプリケーションとの連携部分を担当しています。
前半期は、社内の機械学習ワークロードを既存のマネージドサービスから Google Kubernetes Engine (GKE) に移行するプロジェクトを進めていました。
その過程で、shadow deploy / mirroringの重要性を改めて強く認識する出来事がありましたので、本記事では、その背景と学びについて書きます。
- 背景:機械学習ワークロードのGKE移行
- Shadow deploy導入までの経緯
- とはいえ、本番データでは簡単にテストできない
- 解決策としての shadow deploy / mirroring
- コストとの向き合い方
- まとめ
背景:機械学習ワークロードのGKE移行
前半期は、社内の機械学習ワークロードを Google Kubernetes Engine (GKE) に集約するプロジェクトを進めていました。
従来の構成では、ワークロードは大きく同期推論と非同期推論の2種類に分かれており、Google Cloud の Vertex AI、Compute Engine、Cloud Run を組み合わせて構築されていました。 これらを運用・開発の両面で扱いやすくするため、ワークロードをGKEへ統合しています。
移行の背景や全体的なメリットについては、同じAnalysis Platform GroupのHirokaが以下の記事で詳しくまとめているので、興味がある方はそちらもぜひ参照してください。
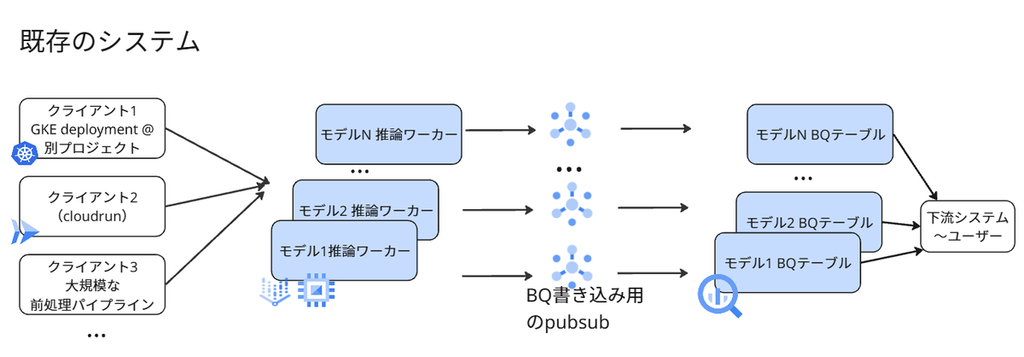
移行対象となるモデルは合計で15個あり、それぞれが異なる特性(パフォーマンス要件やリソース消費)を持っています。 例えば、CADDi にアップロードされる図面に含まれる製造業特有の記号を検知するモデルや、それらを分類するモデル、文字を抽出するモデルなど、多様な役割のモデルが含まれています。
さらに、これらのモデルを呼び出す経路も一様ではなく、APIや大規模な前処理パイプラインなど、合計で5種類以上のクライアントが存在していました。 クライアントの多くは別チームによって開発・運用されているため、移行にあたっては各チームとの調整も重要なポイントでした。
これだけのモデル数・クライアント数を対象に、Claude CodeやDevinといったツールも活用しながら、グローバルなメンバーで短期間に移行を完了させた点については、それ自体で一つの記事になる規模の取り組みですが、本記事ではその中でも、shadow deployによって得られたMLシステムの信頼性に焦点を当てます。
Shadow deploy導入までの経緯
MLモデル移行作業は、まず同期推論モデルから開始しました。影響範囲が比較的小さいモデルを選定し、パイロットとして移行を進めました。
信頼性を担保するため、不具合が発生する前提でロールバックしやすい設計とし、あらかじめロールバックプランも用意しました。 移行後の構成に対しては、関係チームと連携しながら負荷試験・動作確認・精度検証を実施し、必要なチューニングを行ったうえで、クライアントの接続先を新しいシステムへ切り替えました。
切り替え直後は大きな問題もなく、安定して稼働しているように見えましたが、切り替えから2日後、一部のリクエストで以下のようなエラーがバースト的に発生しました。
{"error":{"code":400,"message":"Invalid request: Input should be a valid dictionary or object to extract fields from","status":"INVALID_ARGUMENT"}}
影響範囲は限定的でしたが、原因を即座に特定できなかったため、SLO内ではあったものの、リスク回避を優先して移行前の推論システムへロールバックを実施しました。
後続の調査により、原因は上流システムから送られてくる一部リクエストに含まれる例外的なヘッダーであることが判明しました。 移行前のVertex AI ベースのシステムではこのヘッダーを許容していた一方で、移行後のシステムではエラーとして扱われていました。
さらに、このヘッダーは本番環境のごく一部のリクエストにのみ含まれており、サンプリングされたテストデータでは再現されないパターンでした。 このようなケースは、オフラインテストだけで事前にカバーすることが難しい典型例といえます。
結果として、ロールバックしやすい設計と事前に準備していたプランにより、障害に発展する前に旧システムへ切り戻すことができて、その後、該当のケースに対応する形で新システムの修正を行いました。
今回の事例はヒヤリハットにとどまりましたが、ここで改めて感じたのは、
複数チームが関与する複雑なシステムほど、本番データに基づく検証が不可欠になる
という点です。
とはいえ、本番データでは簡単にテストできない
一方で、本番データには顧客データが含まれますので、セキュリティやガバナンスの観点から、自由にテストに使えるものではありません。
この「必要だけど使えない」というギャップは、特にMLシステムにおける推論結果の品質や安定性の検証において大きな課題となります。
たとえば、
- データ分布の偏り
- 想定外の入力パターン
- 上流システムの揺らぎ
といった要素は、オフラインのテストデータではどうしても再現しきれません。
セキュリティやガバナンスの制約もあり、実質的には本番相当の環境で検証を進める必要がありました。ここでいう「本番でテスト」は直接本番システムに影響を与えるものではなく、本番と同じ入力を用いて裏側で挙動を観測する、いわゆるshadow deployを指しています。
解決策としての shadow deploy / mirroring
上記のヒヤリハットを踏まえ、移行プロジェクトの残りの対象モデルでは、簡易的なshadow deploy / mirroringを導入することにしました。
Shadow deployとは、短く言うと「新しいバージョンを旧バージョンと並行で動かし、本番と同じ入力を受けさせながら、その出力はシステムやユーザーには影響を与えない形で比較対象として扱うデプロイ手法の一つ」です。
今回の移行プロジェクトでは、移行後のモデルを「セキュリティが担保されている本番環境で本番と同じ入力」で裏側で動かし続け、既存モデルと並行して挙動を観察しました。もちろん、CIテストやstaging環境での負荷試験・精度試験など、デプロイ前の一通りの検証を終えたうえで、最終確認として実施しています。
移行対象の既存システム図(イメージ)は以下の通りです。
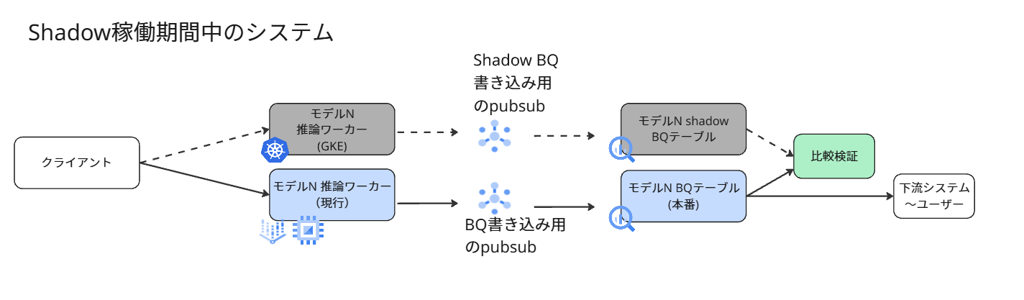
スケジュール制約を踏まえ、まずは「検知と差分把握」にフォーカスした最小構成で進め、以下の図のようなシステムを構築しました。なお、図が複雑にならないように、クライアントおよびモデルはそれぞれ1つに簡略化して示しています。
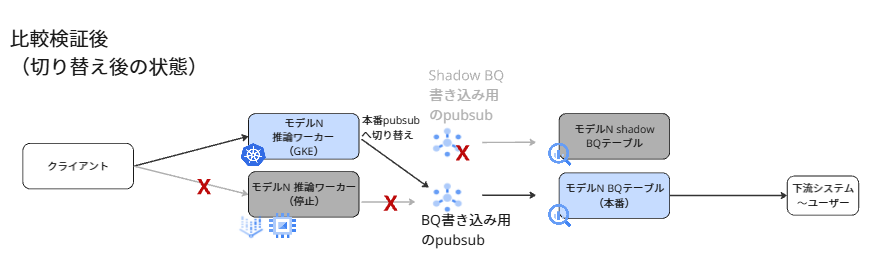
推論結果の比較検証に加えて、裏側で両システムのログやパフォーマンスを継続的に監視していました。その結果、いくつかの例外的なケースもユーザー影響を出さずに本番環境で発見することができ、調整後に本番切り替えを行うことができました。本番切り替え後のシステム図は以下の通りです。
比較検証期間中に検知・修正できた例外的なケースとしては、以下のようなものがありました。
新旧システム間のパフォーマンス・リソース差分
従来は Vertex AI や Compute Engine 上で実装されていた推論基盤を、GKE上のLitServeへ移行したことで、実行基盤およびフレームワークの両面に変更が入りました。そのため、既存システムと同等以上のパフォーマンスが得られるかを改めて検証する必要がありました。
その検証にあたっては、テストデータでは本番トラフィックの分布や特性(検出対象の数など)を正確に再現することが難しいという課題がありましたが、shadow deploy を用いることで、本番データを活用した確実な検証が可能になりました。
またこの過程では、timeout設計の重要性も再認識しました。特にバッチ処理や長時間実行されるリクエストでは、旧システムとの前提の違いによりタイムアウトの発生条件が変わり、設定値の見直しが必要になりました。あわせて、timeoutを長く設定しすぎるとリソース占有時間が増え、結果としてコストが増加するため、性能だけでなくコストとのバランスを踏まえた設計が重要になります。
実データでのみ発生するエラー
検知対象が例外的に多い図面において、システムリソースが圧迫されるケースがありました。元システムでは問題なく処理できていたものの、移行後のシステムではエラーが発生しました。 この問題は、LitServe、Kubernetes、Google Cloud Pub/Sub のパラメータチューニング(同時メッセージ数、batch size など)によって解決しました。
精度のギャップ
一部のモデルでは、新システム側で前処理が正しく適用されていないケースがあり、旧システムとの差分として推論結果の精度ギャップが発生しました。 これは shadow deploy によって初めて検知できた問題であり、前処理の実装漏れに起因するものでした。
上記の経験を踏まえ、特に複雑なMLシステムにおいては、shadow deployの仕組みを使って継続的にデータの性質や分布を把握することが、より信頼性の高いシステムにつながると強く実感しました。 この考え方自体はセオリーとして理解していたものの、今回の経験を通じてその重要性を改めて認識しました。
こうしたメリットを得られることが前提となる一方で、次に論点となるのはコスト面です。特にMLのワークロードではGPUリソースの利用も伴うため、無視できない要素になります。
この点についてはトレードオフもあるため、次の章で整理します。
コストとの向き合い方
Shadow deployは、トラフィックの複製と追加の推論実行が発生するため、インフラコスト(特にGPUによる推論コスト)の面でオーバーヘッドが生じます。
ただし、用途に応じて設計することで、無駄なコストは抑えられます。
例えば:
機能確認が目的の場合
フルスケールである必要はなく、縮小構成で数日間動かすことで、挙動や例外ケースの検知には十分なケースが多いです。
負荷耐性の確認が目的の場合
フルスケールで短時間(数時間〜1日)実施する方が効率的です。
さらに、すべてのリクエストを対象とするのではなく、トラフィックの一部のみをshadow側に流すといった制御を行うことで、コストと検証精度のバランスを取ることも可能です。
このように目的と検証対象を明確にすることで、「必要十分なshadow環境」を設計できます。
まとめ
今回の移行を通して、特にMLシステムにおいては「本番環境でしか見えない挙動」が一定割合で存在するという前提に立つ必要があると感じました。
オフラインテストやstaging環境での検証だけでは、データ分布や上流システムの揺らぎまではカバーしきれません。 そのギャップを埋める手段として、shadow deployは有効です。特に複雑なMLシステムにおいては実質的に必須の仕組みだと考えています。
一方で、コストや運用負荷とのトレードオフがあるため、目的を明確にした設計が重要になります。
さらに技術面以外の学びとして、プロジェクト管理の観点では、MLモデル(そしてAPI全般)の移行は単純にモデル数に比例するものではなく、各モデルに紐づく呼び出し元クライアントとの関係性に依存して工数が増えるという点があります。特に1つのモデルに複数のクライアントが存在する場合、その調整や影響確認の分だけ工数は増加します。
今回の移行プロジェクトでは最小構成でshadow deployを導入しましたが、今後は Istio のトラフィックミラーリングなど、より標準化された仕組みの活用も検討しています。