この記事は CADDi Tech/Product Advent Calendar 2025 14日目の記事です。
Executive Summary
- 生成 AI アプリで評価プロセス改善 PoC をした
- 評価制度をアセット化し、生成 AI ツールを組み合わせることによって、評価プロセスを支援した
- 「メンバーの思考の整理」「メンバーからマネージャーへのコミュニケーションの改善」というポジティブな効果が得られた
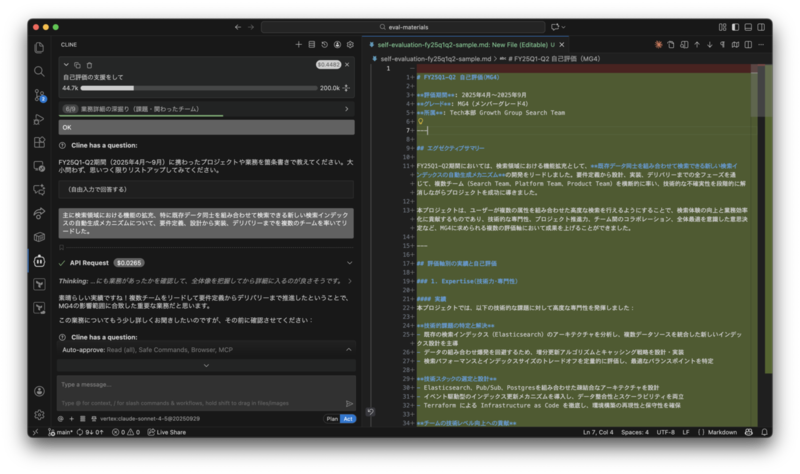
(画像は実際のシステム、入力されているテキストは架空の人物・チーム・業務)
はじめに
キャディのエンジニアリングマネージャーの橋本です。
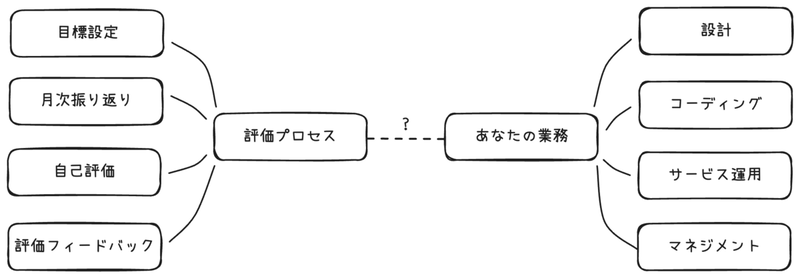
突然ですが、この記事を読んでくださっている皆さんにひとつ聞きたいことがあります。あなたの会社にある評価プロセス、たとえば目標設定、月次振り返り、期末の自己評価、評価フィードバックなどは、あなたの仕事にとってポジティブに働いているでしょうか?
この質問に対する回答は、人によってグラデーションが出やすいものだと思います。「もちろん Yes さ、目標を設定することで集中できるし、フィードバックによって最高の成長機会を得られているよ!」という人もいれば、「うーん、どちらかといえば No かな。評価って時間を取られるけど、あんまり業務に対してポジティブに働いている実感はないんだよね」という人もいると思います。
私自身、エンジニアリングマネージャーになる前は典型的な後者のタイプで、正直に白状すると「評価って面倒だな」と思いながら、会社の評価プロセスに従って毎期の評価を受けていました。
そんな中、ここ1~2年は生成 AI の登場によって、エンジニアリングにおける設計やコーディング、サービス運用における働き方は大きく変化してきました。
今や生成 AI は設計の頼もしい相棒ですし、コーディングに関しては業務のあり方そのものが変わりつつあります。サービスの運用においても、生成 AI のポテンシャルはすでに広く知られているところであります。

エンジニアリングマネージャーになった私にとっては、生成 AI のマネジメント領域への適用については非常に興味深いものでした。特に評価の領域については、前述のとおり、エンジニアリングマネージャーに就任する前からぼんやりとした課題感を持っており、取り組んでみるのにちょうどよい題材だと考えました。
この記事では、エンジニアリングマネージャーというエンジニアでありかつマネージャーである私が、マネジメントの課題を生成 AI とエンジニアリングの力で解消しようとした、そんな試みを紹介します。
課題領域
どうして評価プロセスがしばしばエンジニアにとって自分の仕事を支援してくれるものと感じられないのでしょうか?

すなわち、エンジニアリングの業務は実行される行為を思い浮かべることが容易であるのに対し、評価プロセスにおける記述は実際の行動を想像することが難しいという特徴があり、エンジニアリングの業務と結びつけられていないのではないか、という仮説です。
実際、上の画像にキャディの評価基準からの抜粋と、実際の業務でありがちなタスクを並べてみましたが、実際の業務タスクと比べ、評価基準が抽象的で手触り感がないことが確認できると思います。
では、なぜ評価プロセスはこんなにも手触り感がないのでしょうか?私はその原因を、会社の外と中のそれぞれに分けて考えてみました。

たとえば、キャディ Tech では、「5軸に沿ったコンピテンシー評価」を導入しています。評価制度のプロであれば、この説明文からこの評価制度がどういう設計なのか、すなわち
- コンピテンシー評価とは何か
- 他の評価手法、例えば成果評価とは何が違うのか
- どのような課題を解決する評価制度なのか
- メンバー、マネージャーがそれぞれ注意するべきことがなにか
ということが想像できることでしょう。(まるでソフトウェアエンジニアがマイクロサービスアーキテクチャについて生き生きと語るときのように!)
しかし、実際にはエンジニアは評価制度のプロではないので、これらの知識を必ずしも有しているわけではありません。
また、会社の内側にある理由として、評価制度はその会社固有の価値観や信念を取り扱うものであるから、というものがあります。評価制度は、その会社にどのような人が集まるか、どのような行動が促進されるかに強い影響力を持ちます。そのため、より良い評価制度を設計すればするほど、評価制度にはその会社の個性が出やすいという特徴があります。別の言い方をすれば、同じ「ソフトウェアエンジニア」という職種であっても、ある会社と別の会社では評価体系が全然違うということすらありえるのです。
結果的に、評価制度はしばしばハイコンテキストなものになり、過去の経験による知識による解釈を難しくします。その会社に新しく入社したメンバーにとって解釈することが難しいのはもちろん、ずっとその会社にいたメンバーにとっても、事業の特性やフェーズが変わることによって評価制度はしばしば影響を受けるため、正しく評価制度を理解しつづけることは難しいという特徴があります。
解決領域
既存のアプローチ

課題領域に対する従来のアプローチでは、業務を深く理解しているマネージャーが、メンバー一人ひとりに合わせたコーチングを通じて会社全体に理解と納得を作り上げていくというアプローチが取られてきました。
この方法は、うまくいくケースがある一方で、以下のような課題があります
- 効率性の課題:マネージャーがメンバーのことをよく知る必要があり、メンバー・マネジメント双方のリソースを使う
- 実効性の課題:マネージャーに高い対人スキルと業務理解を要求するため、実効性にばらつきがある

- 評価って時間を取られる → 効率性が低い
- あんまり業務に対してポジティブに働いている実感はない → 実効性が低い
という実感とも繋がってきます。
生成 AI を統合したアプローチ - 概要

既存のソリューションの課題に対し、私は生成 AI を活用することで「一人ひとりの状態に合わせたコーチング」を実現し、評価制度に関する一般知識、およびメンバーごとの理解度の差分を埋められるのではないかと考えました。
ただし、生成 AI では会社固有の知識を取り入れることができないため、合わせて生成 AI がアクセス可能なアセットを作ることを実施しました。
「生成 AI がアクセス可能なアセット」とは
生成 AI がアクセス可能なアセットとはなんでしょうか?これはただの社内ドキュメントとは違うのでしょうか?
生成 AI の活用を考える際に、最も重要な制約のひとつがコンテキストウィンドウです。LLM(Large Language Model; 生成 AI の基盤となる機構)には、特定の長さの文章までしか文脈を正しく捉えられないという課題があります [1]。コンテキストウィンドウとはあるモデルが捉えられる経験上の文脈の長さを示しており、例えば ChatGPT 4o では約13万トークンまでは妥当に取り扱えるとされています [2]。コンテキストウィンドウの制約は、LLM への入力を無制限に大きくできるわけではないということを示唆しています。
コンテキストウィンドウの制約を回避する方法は今までに多く研究されており、その代表的なもののひとつが AI エージェントです [3]。AI エージェントはデータ取得と推論を交互に繰り返すことによって、必要な情報を必要な分だけ取得し、必要な分だけ覚えておくことを実現し、アセットを効果的に利用することができます。

AI エージェントの選定
では AI エージェントにとって優しいアセットはどのようなものでしょうか?
実際に PoC (proof of concept; 不確実性が高い部分を切り出してクイックに検証をすること)アプリケーションを作る際には、まず利用する AI エージェントを選定し、その AI エージェントにとって優しいアセットを作ることにしました。
今回は AI エージェントとして、すでに開発業務で使っていた Cline を使用することにしました。Cline はテキストエディタである VSCode の拡張機能で、通常コーディングの AI 支援として使われます。
今回 Cline を AI エージェントとして採用したのは、今回の取り組みがうまくいくかどうか不確実性が高く、クイックにユーザーを巻き込んだ検証を行うため
- すでに活発に開発・検証されたコンテキストエンジニアリング技術を利用する
- ユーザーとの対話インターフェースをすでに提供してくれているアプリケーションを利用する
- ユーザーもエンジニアなので開発業務で使っていた Cline を活用することに障壁がない
という観点で利点が大きいと考えたためです。
評価制度アセットの構築
Cline は標準でディレクトリ内部のテキストファイルを解析し、検索してくれます [4]。既存の社内のアセットは
- Confluence 上に記載されたドキュメント
- Google Docs 上に記載されたドキュメント
- Google Spreadsheet 上に記載されたドキュメント
があったため、これらをすべてマークダウンに変換し、Git レポジトリとして管理をすることにしました。Confluence、および Google Spreadsheet 上のドキュメントは Google Docs に貼り付けることができ、Google Docs はそのままマークダウンに変換できるため、マークダウンへの変換は容易に行うことができました
また、元ファイルに対してコピー操作を行うため、新たに作成されたアセットについては、
- インポート日
- インポート作業者
- 元資料の URL
を YAML フロントマターを利用して付与しました。この操作によって、アプリケーションの利用者がアセットが古くなっていた場合に自動的に最新の情報を確認し、必要に応じて更新できるようにしました。

具体的には以下のような YAML フロントマターがすべての資料の冒頭に書き込まれています。
--- title: "評価軸定義" import_date: "2025-06-24" source_url: "https://docs.google.com/spreadsheets/d/..." imported_by: "システム管理者" version: "1.0" --- # 評価軸定義 ...
また、より AI エージェントが関連するドキュメントを探索できるように、アセットの追加時には関連資料を末尾に追加するようにしました。

例えば評価制度の FAQ アセットについては、以下のように評価制度の概要や、評価軸の定義に対するドキュメントへのリンクを記載しました。
--- title: "評価制度FAQ(よくある質問と回答)" import_date: "2025-06-24" source_url: "https://docs.google.com/spreadsheets/d/..." imported_by: "システム管理者" version: "1.0" --- # 評価制度FAQ(よくある質問と回答) ... ## 関連資料 - [HELIX制度概要](helix-system-overview-2025.md) - [Career Track別の期待活躍イメージ](career-track-expectations-2025.md) - [評価軸定義](evaluation-axis-definitions-2025.md) - [Track別・Grade別期待活躍レベル一覧](track-grade-expectations-matrix-2025.md) - [Helix目標設定ガイド](helix-goal-setting-guide-2025.md)
アセットの構築上の工夫
上記の YAML フロントマターの設定や、メタデータの更新を人力で行うと必ず抜け漏れが発生します。
特に、今回はアセットを作成したり、管理したりするために、エンジニアリングマネージャーである私だけでなく、Tech HR(Human Resource; 人事のこと)にも協力してもらいました。
そこで今回アセットを構築する際には、コミット前に AI エージェントにレビューを行わせ、自動で付け加えられる場合には AI エージェント自ら追記し、そうでないメタデータについては修正を要求するような工夫を行いました。
すなわち、AI エージェントを利用者だけが使うのではなく、アセット開発者も活用できるようにすることで、アセットの品質を保つようにしました。
AI エージェントに対する指示
AI エージェントをさらに有効に働かせるために、初期プロンプトを自動で与える Cline rules [5] も活用しました。
Cline では初期プロンプトをカスタマイズでき、またその組み合わせも変えることができます。
今回はアセットを作る人と使う人、それぞれで注目するべきポイントが違うため、Cline rules を複数作成し、Cline rules の切り替え機能を活用することで、アセットを作る人も使う人も使いやすい環境を整えました。

特にメンバー向けの Cline rules には以下のような指示を記載したことによって、AI エージェントに期待していることを明示し、また AI エージェントが回答できる限度を超えている場合には、適切にエスカレーションされるように配慮しました。
### 評価アシスタントとしての心構え - 中立性の維持: 特定の評価結果に偏らない客観的なアドバイス - 継続的な学習: 評価制度の変更や更新に対応 - 実用性の重視: 理論だけでなく実践的なアドバイスを提供 ## サポートが必要な場合 - 評価制度の詳細: 人事担当者に確認を依頼 - 複雑な目標設定: 上司やメンターとの相談を推奨
結果
実際の PoC アプリケーションの挙動
以下は私が架空のエンジニアを想定し、自己評価の支援を依頼したときの実際のシステムの挙動です。
ユーザーが「自己評価の支援をして」と入力する

AI エージェントがエントリーポイントとなるドキュメントを読み込む

AI エージェントが関連するドキュメントを辿ってさらに読み込む

AI エージェントがユーザーを対話的にコーチングしながら実務に連動した評価プロセスを提供する

どのような支援が必要かをヒアリング 
評価対象期間を特定する 
役職・職位を確認する 
ユーザーの現状に合わせて対話を続ける。この後に複数の自由記述を含むステップが入る 最終的に自己評価として以下のような markdown が出力される
評価期間: 2025年4月~2025年9月 グレード: xxx 所属: Tech本部 xxx Team --- ## エグゼクティブサマリー FY25Q1-Q2期間においては、検索領域における機能拡充として、xxx の開発をリードしました。要件定義から設計、実装、デリバリーまでの全フェーズを通じて、複数チーム(xxx Team、xxx Team、xxx Team)を横断的に率い、技術的な不確実性を段階的に解消しながらプロジェクトを成功に導きました。 ... --- ## 評価軸別の実績と自己評価 ### 1. Expertise(技術力・専門性) #### 実績 本プロジェクトでは、以下の技術的な課題に対して高度な専門性を発揮しました: 技術的課題の特定と解決 - 既存の検索インデックス(Elasticsearch)のアーキテクチャを分析し、複数データソースを統合した新しいインデックス設計を主導 - ... ... #### 自己評価(ノッチ: x2) MG4 の評価基準である「大きなチームや他チームも関係するプロダクトに対して、全体的な構想を描き、設計することができる」 、... の要件を満たしていると考えます。 一方で、 ... については今後の課題と認識しています。 --- ### 2. Delivery(価値創造・提供) ... --- ## 総合評価と今後の成長課題 ### 強みとして発揮できた点 1. 技術的専門性とリーダーシップの両立: 検索技術の専門性を活かしながら、複数チームをリードする役割を果たせました ... ### さらに伸ばせる可能性がある点 1. 定量的な評価指標の活用: プロセス改善において、より定量的な指標(DORA metrics等)を活用した継続的改善サイクルの確立 ... ### 次期(FY25Q3-Q4)に向けた改善アクション 1. 本部戦略への貢献: 本部全体の技術戦略策定プロセスに積極的に参加し、検索領域以外の知見も獲得 ... --- ## 証跡・参考資料 - プロジェクト計画書: [Confluence](https://example.com) ...
メンバーからの定性的なフィードバック
今回、実験的に半期の評価サイクルにあわせて、実際の評価プロセスで PoC アプリケーションを利用可能にしユーザーのフィードバックを収集しました。
対象はエンジニアリング組織全体で、利用は任意とする形式で運用しました。最終的に、全体の約3割のメンバーが実際に利用しました。
利用したメンバーから、ポジティブなフィードバックとして以下のようなものがありました
- 自己評価を書くときの初動ハードルが下がった
- 自分では気づいていなかった観点(協働や影響範囲など)を指摘してくれるのがありがたい
全体的に、文章の整形よりも思考の整理についてポジティブなフィードバックが多かったことが特徴的でした。AI が自分の行動を、評価の考え方に沿って構造化してくれるため、「何を書けばいいか」が明確になり、記述の負荷が軽減されたという声が多くありました。
一方で、以下のようなフィードバックも多く見られました。
- AIが出してくれた文章をたたき台として修正する形がちょうどいい
実際、生成結果をそのまま使う人はほとんどおらず、多くの利用者が「AI の出力を土台にして、自分の言葉にリライトする」スタイルをとっていました。これは、生成 AI が解決できる課題として、文書化そのものよりも、知識へのアクセスを補助する部分が大きいという当初の仮説を支持する結果だと考えられます。
マネージャーからのフィードバック
また、メンバーが PoC アプリケーションを利用したマネージャーからもフィードバックを得ることができました。
全体的にポジティブな内容が多く、
- 各評価軸に沿った構造的な書き方をされていて読みやすかった
- 行動と成果のつながりが明確でわかりやすかった
- トーンや文体が統一されており、比較しやすかった
というフィードバックが得られました。これまでは文章表現の違いによって、評価プロセスのアウトプットの解釈が割れることがありましたが、一定のフォーマットでアウトプットが整理されることで、よりコンテンツの議論に集中できるようになったものだと考えられます。
今後の課題
PoC アプリケーションの実験的な導入によって見えてきた課題もありました。
- 利用者は全体の約3割にとどまり、まだ十分に浸透していない
- 評価制度そのものの記述や記載が曖昧な場合、AI エージェントの出力もぶれる
つまり、AI が整理してくれるのは「構造化」と「言語化」の部分であって、評価の根幹にある制度設計やマネジメントの解像度については、アセットの継続的な改善を要するということがわかりました。
また、浸透課題については、体験の改善が必要だと考えられます。現状ではエディタと拡張機能のインストール、さらには Git レポジトリからのアセットダウンロードをすべてメンバー自身が実行する必要があるため、利用開始のハードルが高いという課題が見られました。PoC によって利用をすることによって得られるベネフィットが明らかになったため、踏み込んで社内サーバにホスティングし、環境構築を不要にしていき、より多くのメンバーが活用できる環境を作っていこうと考えています。
まとめ
今回の記事では、私たちが取り組んだ評価 x 生成 AI PoC、すなわち評価制度を AI が利用可能なアセットとして整備し、それらを適切に連携させることが、評価プロセスの効率化と質的向上に効果的であったことをご紹介しました。
実は、今回ご紹介した、AI の力で「ハイコンテキストな情報を構造化し、活用する」アプローチは、キャディの製造業領域におけるビジネスやプロダクトにおいても核となる考え方です。
AI と情報資産の連携は、まだまだこれからどんどん発展していく領域です。もし今回のブログでキャディってどんな会社なんだろう?と興味を持っていただいた方は、ぜひカジュアル面談で一緒にお話ししましょう!
https://open.talentio.com/r/1/c/caddi-jp-recruit/pages/78398
参考文献
[1] Hahn, M. (2020). Theoretical Limitations of Self-Attention in neural sequence models. Transactions of the Association for Computational Linguistics, 8, 156–171.
[2] OpenAI Platform. Available at: https://platform.openai.com/docs/models/gpt-4o (Accessed: 09 December 2025).
[3] Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., & Cao, Y. (2022). ReAct: Synergizing Reasoning and Acting in Language Models. arXiv preprint arXiv:2210.03629
[4] Cline-tool guide. Available at: https://docs.cline.bot/exploring-clines-tools/cline-tools-guide (Accessed: 09 December 2025).
[5] Cline Rules. Available at: https://docs.cline.bot/features/cline-rules (Accessed: 09 December 2025).