みなさんはじめまして。CADDiで図面解析チームのテックリードをしている稲葉です。今日は、我々のチームがどういった図面解析の機械学習モデルをどのように開発しているのか、それをどのように改善しようとしているかを紹介したいと思います。
目次
どういう図面解析が必要なのか
CADDiでは図面活用SaaSであるCADDi DRAWERを提供しています(DRAWERの詳細に関してはこちら)。図面はどういうものが作りたいかを示した設計図なわけですが、PNG画像やPDFなど2次元図面画像で保管されており、構造化されていないデータである事が多いです。作りたいものが何を素材としているか、どのように加工すべきかなどが画像になっているため、人の目では分かってもコンピュータ上では管理し易い状態になっていません。そのため特定の図面を自動で探し出すのは難しく、ベテランの記憶や勘に頼っていたりします。そこで、DRAWERでは検索・活用し易くするため図面画像から重要な項目を認識して構造化する解析処理が行われています。また、認識する対象範囲もさらに広げることが望まれています。
現状では、どういう認識モデルを開発しているかというと、
- 類似特徴抽出
- 形状など
- OCR
- 全文字列
- 表題欄(図面番号や名称など)
- 寸法
- 記号検出
- 溶接記号など
などといったものです(図1)。図面解析だけでもかなり多いですね。さらに、図1に示した例のような図面ばかりではなく、一度紙に印刷されたものをスキャンして画像として取り込まれた図面もありますし、手書きの図面もあります。また、図面の描き方やフォーマットはお客様に依っても様々です。もちろん画像処理・アルゴリズムで解ける部分もあるのですが、機械学習の方が向いているタスクや機械学習に頼らざるを得ないタスクも多いです。
 図1. 図面解析の例
図1. 図面解析の例
CADDiの機械学習モデル開発の流れ
CADDiでの機械学習モデル開発の流れの話を紹介したいと思います。みなさんにとっては釈迦に説法の部分もあると思いますし、これが一番良い開発フローだ!と思っているわけでもないのですが、CADDiならではの部分もあると思いますのでお付き合いください。
世の中で機械学習モデル開発の流れは色々なところで語られているのですが、自分はUberさんの機械学習開発プロセスの概念図(図2)がしっくり来ているのでこれをベースに各工程でどういうアウトプットを定義しているかを紹介していきます。全体の大きな改善ループに加え、PoCフェーズの試行錯誤が表されています。
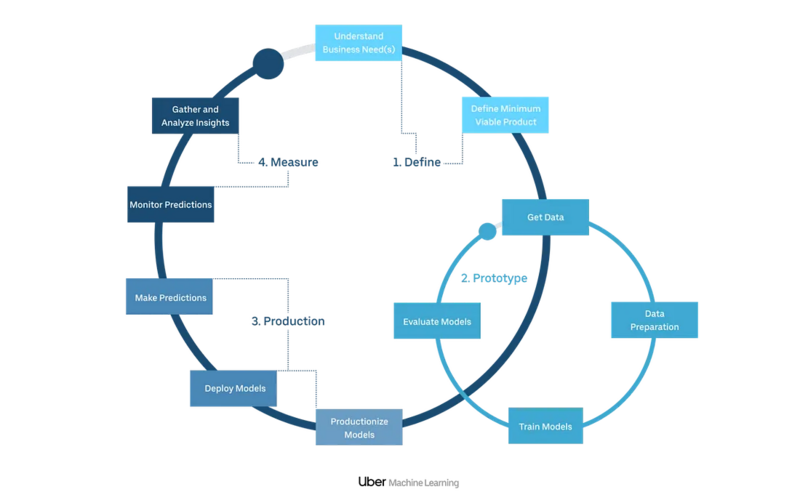 図2. 機械学習モデル開発の流れの例
(ML Engineering Lessons Uber Learned from Running ML at Scaleより引用)
図2. 機械学習モデル開発の流れの例
(ML Engineering Lessons Uber Learned from Running ML at Scaleより引用)
1. Define
1-1. 問題設定
このステップでのアウトプットはPRD: Product Requirements DocumentとDesign Docです。プロジェクトを始める際は、主にプロダクトマネージャらが下記に示す項目を含んだPRDを書いてくれています。
- 背景
- スコープ(やること、やらないこと)
- ターゲットユーザ
- ユースケース
- 機能要件
- 非機能要件
- リリーススケジュール
そして、このPRDを叩き台として関係する開発チームが合同で読み合わせを行い、詳細を具体化したり、懸念点を洗い出したり、機械学習でやるべきなのかどうかも含めて議論します。また、機械学習に限らないですが認識モデルを作る際は、入出力の定義・評価方法・目標値も大事になります。図面特有の記号などはJIS規格で種類や補助記号(図3に記号例を示します)が定められているのですが、いきなり全ての記号に対応しようとするとアノテーション工数が増大しリリースに時間がかかってしまうため、今必要とされているスコープに合わせて調節することもあります。機械学習はやってみないと・実際にデータを見てみないと性能がどれくらい出るかを見積もるのは難しいですが、評価方法や目標値もユースケースに合わせて仮置きではありますが決めています。 ここで話し合った内容を基に、こちらのml-design-docフォーマットから必要な部分を抜粋し、Design Docを書いています。後のステップを進める中で、ここで決定した内容に追加・修正をすることはもちろんあります。
 図3. 表面粗さJIS記号の例(表面粗さと溶接を図面で指示するJIS記号より引用)
図3. 表面粗さJIS記号の例(表面粗さと溶接を図面で指示するJIS記号より引用)
1-2. アノテーション定義
このステップでのアウトプットはアノテーション定義書・作業マニュアルです。図面という特殊ドメインの画像タスクですので、オープンデータセットをそのまま活用できることは少なく(もちろん事前学習に使うことはできます)、人間による正解値(アノテーション)が必要なことがほとんどです。実際に図面を見つつ決まったスコープに従ってアノテーションの実例や例外ケースなどをまとめていきます。このようなアノテーション定義はドメイン知識がかなり必要なところなので、実際に図面からモノを作るCADDi MANUFACTURING事業で培った経験を持つ方のお力を借りています。最近では、ドメイン知識をカバーし、アノテーションのQuality, Cost, and Delivery: QCDを高める役割を持ってくれるAnnotation Opsチームが発足したため、とても進め易くなりました。
2. Prototype
2-1. データセット作成
このステップでのアウトプットは入力データと出力したいアノテーションのセットから成るデータセットです。お客様から預かっている大量の図面データをサンプリングして、アノテーション定義に従ってアノテーションしていきます。Annotation OpsにアノテーションのQCDを管理してもらっていると先ほど述べましたが、それぞれで実施している取り組みを紹介します。
まず、Qualityに関してはオンボーディング、Q&A、二段階承認フロー、抜き取り検査を実施しています。オンボーディングでは、実際にアノテータさんにアノテーションタスクの例題をいくつか実施してもらい、想定するアノテーションができるようになるまで練習していただいています。Q&Aでは、アノテータさんからアノテーションの判断に困った際の質問・回答をアノテーション定義書・作業マニュアルとして更新し、できる限りアノテータさん毎にブレが生じないように、アノテーションに迷いが生じないようにしています。質問は基本的にAnnotation Opsのメンバーが対応していますが、認識モデルの学習で問題になりそうなところは機械学習エンジニアと相談して決めています。二段階承認フローは、最初にアノテーションするアノテータさんとは別のアノテータさんがアノテーションをチェックし、修正が必要であればコメントを残し再度アノテーションプロセスに戻すようにしています。抜き取り検査は全て承認が通ったデータをいくつかサンプリングし、Annotation Opsのメンバーが評価しています。この際の良品率をKPIとして追っています。
次に、Costに関してですが、基本的にアノテーション速度を上げるために、プレアノテーションとショートカットキーの利用促進を実施しています。プレアノテーションは、皆さんご存じの通り、既に認識モデルがある場合はその認識モデルの結果を初期アノテーションとして登録することです。ショートカットキーの利用促進は、アノテーションツールにデフォルトで”クラスの切替”や”アノテーション削除”などのショートカットキーが設定されているため、それらをアノテータさんに共有しています。キーボードだけでなく、マウスのボタンにもキーを設定することもできるため試行錯誤しています。
最後に、Deliveryの部分ですが、予実管理を毎日行っています。データセット作成の期日に間に合いそうに無ければ、期日を調整するかアノテータさんのアノテーションと他の作業の工数割合を調整しています。
これらの取り組みはアノテーションツールの選定も重要になります。以前はオープンソースを活用していたこともありましたが、セキュリティ面や上記で示したようなことがプロセスとして組めるかどうかを考慮した結果、FastLabelさんのツールを利用させていただいています。
2-2. 学習・評価
このステップでのアウトプットは学習・評価コードと評価レポートです。図面解析チームにはkaggle含め経験豊富な機械学習エンジニアが居ますので、バリバリ開発してくれています。実際どういう技術を使っているかや技術スタックは、また別の機会にメンバーから紹介する予定ですのでここでは割愛します。
3. Production
3-1. デプロイ
このステップでのアウトプットはAPIサーバとドキュメント類(モデルカード、テスト結果)です。ML API基盤に関しては既にTech Blogに書かれていますので、ぜひ読んでみてください!テストは、PoCの性能が再現できているかの性能テストと想定リクエストでどれくらいのレイテンシ・スループットで処理できるかを見積もる負荷テストを実施しています。PRD作成時に要件を決めていますので、満たせているかどうかを確認しています。
4. Measure
4-1. 監視
デプロイしたWeb APIのレイテンシ・スループットなどは日々監視・ロギングしており、サービス提供に問題が無いかを確認しています。次項で示す機械学習モデルの改善にも関連するのですが、性能面での監視やフィードバックの貰い方の仕組み化も進めているところです。
継続的な機械学習モデルの改善に向けて
ご存じの通り、機械学習モデルは一度作って終わりではありません。新しいお客様に契約いただくことで図面のバリエーションも増えますし、中々現れないレアケースの認識対象もあります。なので、継続的な改善が必要なのですが、そのために”重要なデータを集める仕組み”と”機械学習パイプライン”の構築を考えています。改善ループのイメージを図4に示します。
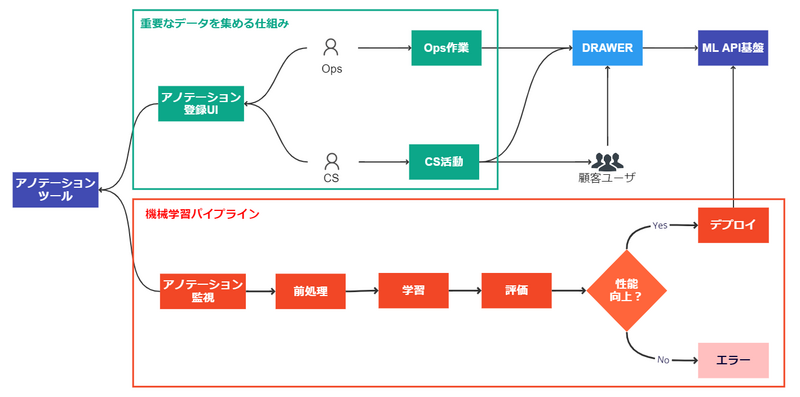 図4. 機械学習モデルの改善ループ
図4. 機械学習モデルの改善ループ
重要なデータというのは、性能向上に寄与するデータや顧客価値を毀損しているデータのことを指しています。集め方としては下記が考えられます。
- 能動学習: 不確実性が高いデータを現状のモデルを使ってマイニングする
- お客様とやりとりがあるCustomer Successチームや実際にデータを処理するOpsチームなど社内全員で課題データを挙げて収集する
- ユーザであるお客様にDRAWERアプリ内から直接課題データを挙げてもらう
これらの内、まずは2の仕組みを作り社内の人間であれば誰でもアノテーションタスクとして登録できるようにして試験運用を開始しました(図5)。DRAWERで登録してある図面画像は一意に定まるIDで管理されていますので、ID群とタスク名と登録した理由を入力して実行するだけでアノテーションツールに登録され、リンク先から実際にアノテーションすることができます。アノテーションツールはFastLabelさんのツールを利用していますが、アノテーションタスクを管理するWebAPIやFastLabel Python SDKが揃っているため、容易にこのようなフローを作ることができました。多くの人間でアノテーション登録をするとノイズになるようなデータが含まれるのでは?という懸念もありますが、データセット化されるためには他のアノテータの承認が必要となるため、アノテーションの品質は担保できると考えています。
 図5. アノテーション登録UI
図5. アノテーション登録UI
機械学習パイプラインは上記のようにして収集したデータを活用し、定期的に”前処理-学習-評価-デプロイ”を自動実行する仕組みですが、絶賛開発中です。MLOpsチームのメンバーがまた紹介してくれますのでここでは詳細を割愛しますが、機械学習モデルの更新サイクルを高速化するため、また機械学習エンジニアが新しいモデルの開発など得意な領域に注力できるようにするため、開発を進めています。
これらの仕組みを組み合わせることで、お客様などからいただいた課題に迅速に対応してサービス品質を向上させ、より良い顧客体験が産み出せるようにしていきたいと思っています。この辺りの話は今井がData-centric AI勉強会で話した資料もありますので、ぜひ目を通していただけると嬉しいです。
おわりに
CADDiの機械学習モデル開発の流れと継続的な機械学習モデルの改善に向けてどのようなことに取り組んでいるかを紹介しました。図面解析は新機能の開発も進んでおり、DRAWERの機能としても増えつつあるのですが、まだまだ必要な機能がありますし、各認識モデルの改善も必要です。また、今回は2次元図面画像解析の話をしたのですが、2次元図面だけでなくもちろん3次元図面(3DCAD)も今後扱えるようにしていきたいと思っています。やりたいことは沢山あるので、ぜひ一緒に開発を推進してくださるメンバーを募集しています。興味のある方、是非気軽にご連絡ください!
エンジニア向けサイト https://recruit.caddi.tech
カジュアル面談 https://youtrust.jp/recruitment_posts/980e714200110ad87604cb5c9e517027
機械学習エンジニアの求人 https://open.talentio.com/r/1/c/caddi-jp-recruit/pages/79797