MLOps Team Tech Lead の西原です。以前のTech Blogで Pants を使った Python モノレポ移行への取り組みについて紹介しました。日々の業務で得た知見を Python コミュニティに共有できるといいなと思い、PyCon APAC 2023に「Pants ではじめる Python モノレポ」というタイトルで CfP を提出し採択されました。この記事では、PyCon APAC 発表に向けての整理も兼ねて、Pants を使ったモノレポの管理・運用を効率的に行うための取り組みを一部紹介します。
- TL;DR
- CI の待ち時間を短縮する
- モノレポ内の依存を集約管理
- pex による Python 環境のパッケージング
- プロジェクトの依存関係を制御する:Pants の visibility 機能の活用
- まとめ
- link
TL;DR
- リモートキャッシュでテスト時間を 1/12 に短縮
- テストの分割実行で CI の待ち時間短縮
- 依存の集約管理でビルドの堅牢性向上
- pex を使った Python コードのパッケージング
- シンプルなビルドプロセス
- コンテナイメージの軽量化
- 依存禁止ルールを設け、意図しない依存関係形成の防止
CI の待ち時間を短縮する
リポジトリのサイズが大きくなると、依存が増え CI の待ち時間が長くなります。CI の待ち時間が長くなれば開発業務のボトルネックになり、開発スピードが低下します。この状況は開発体験を損ないますが、リモートキャッシュの活用やテストの分割実行をすることで CI の待ち時間を短縮できます。
リモートキャッシュの活用
Pants は Remote Execution API(REAPI)による リモートキャッシュをサポートしています。これにより、個々の開発マシンのローカルキャッシュだけでなく、異なる開発マシン間でキャッシュを共有できます。リモートキャッシュを参照することで一度実行済みのコードやテストの結果を再利用できるため、CI の待ち時間を短縮できます。REAPI をサポートした self-hosted の OSS やマネージドサービスがいくつかありますが、私たちのモノレポではbazel-remote-cacheを使って検証を進めています。Bazel Remote Cache は、ローカル ディスク、S3、GCS、Azure Blob ストレージ をサポートしています。REAPI 用のサーバを建てる必要がなく、Docker コンテナ 1 つだけで動作するため簡単に導入できます。Pants の公式リポジトリには、S3 を用いて リモートキャッシュを有効にする例が存在します。これを参考に、GCS 用の setup を行い、検証を進めました。
リモートキャッシュを有効にするためには、pants.toml または.pants.rc ファイルに以下のような設定を追加します。
[GLOBAL] remote_cache_read = true remote_cache_write = true remote_store_address = "grpc://localhost:9092"
GCS を使った リモートキャッシュ setup の例が次になります。リモートキャッシュを格納する GCS のバケットを事前に作成し、作成済みの bucket を--gcs_proxy.bucketオプションで指定します。
mkdir -p ~/bazel-remote docker run -u 1000:1000 -v ~/bazel-remote:/data -p 9092:9092 buchgr/bazel-remote-cache -d --max_size 10 --gcs_proxy.bucket=foo_bar_remote_cache_example_bucket --gcs_proxy.use_default_credentials=true
上記の setup を行った状態で、2 万行のコードに対してテストを実行し、キャッシュの有無で処理時間に差が出るかを確認しました。結果として、キャッシュがない状態で12分50秒かかっていたテストが、リモートキャッシュに full hit すると59秒で終了することが確認できました。
私たちのモノレポでは pre-commit hook などを活用し、コードが GitHub に push される前に個々の開発環境でテストが実行されるように努めています。これらのテストは CI でも実行されているので、ほとんどの場合で同じテストが 2 度実行されることになります。リモートキャッシュを使うと開発環境でのテスト結果を CI での実行時に参照できるので、CI の待ち時間を大幅に短縮できます。
テストの分散実行による効率化
Pants では、テストを複数の shard(分割単位)に分けて実行できます。CI 環境でこの機能を活用すると複数のマシンで分散してテストを実行でき、CI の待ち時間を短縮できます。以下に、テストを 2 つの shard に分割して実行するコード例を示します。
pants test --shard=0/2 :: pants test --shard=1/2 ::
Pants の公式リポジトリでは、GitHub Actions を使用して shard に分割したテストを複数のマシンで実行しています。こちらの例では、10 台のマシンでテストを並列実行し、1 つのジョブが 10 分程度で完了しています。
リモートキャッシュの実験でも使った 2 万行のコードに対してpants test --shard=1/10を実行してみました。キャッシュヒットがない状態でも 58 秒でテストを終了することが確認できました。開発規模が拡大し、依存するテストが増えた場合でも shard 数を増やして複数のマシンで並列分散することで CI の待ち時間を短縮できます。
モノレポ内の依存を集約管理
依存管理を集約する背景
以前のTech Blogでは、私たちがリポジトリ内の各プロジェクトごとで依存ライブラリを管理していることを紹介しました。しかし、そのアプローチを続けるうえで 2 つの問題がありました。これらの問題に対処するために、リポジトリ内の依存管理を集約することにしました。
最初の問題は Diamond Dependencies です。これは下の図のようにlibaとlibbがlibbaseに依存している場合、libaが使うlibbaseのバージョンとlibbが使うlibbaseのバージョンが異なると、ビルドに失敗する場合があるというものです。私たちが使ってるライブラリの例だとPyTorchやpydantic、Kubeflow pipeline、pandasなどで最近メジャーアップデートがありました。モノレポではコードの参照が容易にできますが、それぞれのコードで依存しているライブラリのバージョンが異なるとビルドに失敗することがあります。任意のライブラリに対して 1 つのバージョンを使用することでビルドの堅牢性を高め、失敗することを防ぐことができます。これは書籍『Software Engineering at Google』のBuild Systems and Build Philosophyの章で"One-Version Rule"として紹介されています。
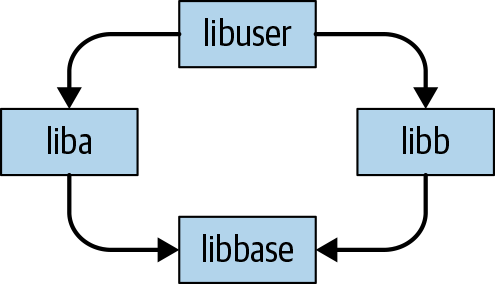 図 : Diamond Dependencies の例。引用:Diamond Dependencies
図 : Diamond Dependencies の例。引用:Diamond Dependencies
2 つ目の問題は、依存関係のバージョン更新にかかる工数が増えてきたことです。モノレポを運用する上で、次の理由から依存関係の更新をなるべく高頻度で行うようにしています。
- 開発が落ち着いてるから何もいじらないという選択肢もあるが、そのまま塩漬けになり久しぶりに触ってみた時に動かない可能性がある
- 頻繁に更新することで CI やビルドが動くのである程度動作確認できる
- 依存してるライブラリが更新されると互換性がなくて動かないということが起こり得るが、どのバージョンまでなら動くのかを把握するために高頻度に更新したい
- 更新サイクルが長く、1 回の更新で多くを変更して問題が起きた場合に何が原因なのか問題の特定に時間がかかる
- セキュリティ的にハイリスクな問題は放置できない
- 通常新しいバージョンは新機能の追加やバグ修正がされてるので私たちにとってプラス
これまで、各プロジェクトごとに poetry を使って依存関係を管理していました。poetry を使っている場合は、poetry lockコマンドを実行すると依存が壊れない範囲で最新バージョンを poetry.lock ファイルに記述してくれます。しかし、私たちの環境では poetry.lock ファイルを使って依存管理をしないため別の方法で依存関係の管理をする必要があります(後述)。poetry で管理しているライブラリバージョンをまとめて更新するためにpoetry upのプラグインを使っていました。poetry にはpoetry update <lib>コマンドで個別のライブラリを更新する機能がありますが poetry up を使うことでライブラリ個別にではなく、一括で依存関係を更新できます。依存関係の更新を行う際は、都度プロジェクトで使う Python バージョンに切り替えてpoetry upコマンドを実行して依存関係の更新を行っていました。Diamond Dependencies の問題になりそうなところは個別にバージョンを揃えていました。リポジトリで管理するプロジェクトが増えてくると、それぞれのプロジェクトで依存しているライブラリのバージョンを揃えつつ更新する作業が大変になってきました。
これらの問題を解決し、依存管理の工数を下げるためにリポジトリ内の依存管理を集約することにしました。
依存関係の更新
依存関係を集約する上で考慮するした点は、集約した依存関係のバージョンをどう更新していくかです。Pants で Python ライブラリの依存関係を管理するにあたって、次の4 つの形式がサポートされています。
requirements.txtファイルpoetry形式のpyproject.tomlファイルPEP621形式のpyproject.tomlファイルpipenv形式のPipfile.lockファイル
Pants にも lock ファイル生成の機能があり、上記の形式に従って管理すれば、依存が壊れない範囲の最新バージョンで依存関係の管理をしてくれます。しかし、この lock ファイルは人が読んで理解しやすい形式ではありません。デバッグ時など、使用しているバージョンを特定する場面を考えると人から見ても分かりやすい形式で管理するのが望ましいと考えました。
そこで、人からも読める形式であり、"One-Version Rule"を実現できるようにpoetry upを使う方法とpip-compileを使う 2 つの方法を検討しました。
poetry up
poetry up は先にも紹介した通り、poetry 管理の依存関係を一括で更新するためのプラグインです。poetry up を使って更新する手順は次のように考えました。
- モノレポで使うライブラリをバージョン指定せずに pyproject.toml に記述。バージョンを指定しない理由は、新規追加した際と
poetry upを実行した際に既存のライブラリとバージョンが競合することがあるため。依存が多いモノレポでは競合が起きやすく、都度解決するのは大変。 poetry up --no-installを実行して poetry.lock を更新。私たちのモノレポでは 3 桁の サードパーティライブラリに依存しており、毎回インストールを行うと時間がかかるため、--no-installをつけることで依存関係の更新だけ行い、意図しないインストールは行わない。- pyproject.toml にはバージョンを記述していないため、
poetry export --without-hashes -f requirements.txt --output requirements.txtを実行してバージョンが記載された requirements.txt を生成 - requirements.txt を Pants の依存関係に追加
pip-compile
pip-compileは requirements.txt 形式、または PEP621 形式の pyproject.toml の依存関係を更新して requirements.txt に出力するツールです。pip-compileを使って更新する手順は次のように考えました。
- バージョンを指定せずに requirements.in にライブラリを記述。バージョンを指定しない理由は、poetry up の時と同様に新規追加時のバージョンの競合を避けるため。
pip-compile --output-file requirements.txt requirements.inを実行してライブラリのバージョンが記載された requirements.txt を生成- requirements.txt を Pants の依存関係に追加
これら 2 つの方法を検討した結果、依存関係のライブラリバージョンを管理するだけであればpip-compileを使う方がシンプルにできそうだったためこちらを採用しました。
requirements.in にバージョンを指定せずにライブラリを記述することで、pip-compile 時に依存関係が衝突しない範囲で最新のバージョンに更新されます。一部、バージョンが更新されるとテストや静的解析が失敗する場合においては、明示的にバージョンを指定して固定するようにしています。
余談:依存関係を集約した当初だと rye がまだリリースされてませんでしたが、この記事を書きながら rye を使う方法も考えてみました。大まかな手順は poetry の時と同様になりますが、--no-installのようなオプションをつけなくてもデフォルトの挙動として依存関係をインストールしないのが良い点だと思います。rye の裏側で pip-compile を使っており、rye lockコマンドを使うと、他の手法と同様に requirements.txt 形式でバージョンが記載されたファイルが出力できます。このファイルを Pants の依存に加えれば依存の集約管理ができそうです。ただ、rye で pip-tools を消す動きがあるので rye の機能を直接使わずに、pip-compile などを間に入れるのが良いのではないかと思います。私たちのモノレポではすでに requirements.in と pip-compile でうまくいってるためリポジトリ内で rye を使う場面がありませんが Python 環境構築を pyenv から rye に切り替えたりと他の場面で活用しています。
依存関係の集約
依存関係を集約した後の更新方法が決まったので、次はリポジトリ内の依存関係を集約していきます。pants peek --filter-target-type=python_requirement ::コマンドを実行するとリポジトリ内の Python ライブラリの依存関係を確認できます。json で出力されるので、次のように jq コマンドを使って整形し、requirements.inに記述します。
pants peek --filter-target-type=python_requirement :: | jq '[ .[].requirements ] | flatten | unique | .[]' -r > requirements.in
集約した requirements.in にライブラリのバージョンが記載されていますが、先にも記載した通り新規追加時に依存のコンフリクトを避けるためにバージョンを削除します。その後、上記の pip-compile の手順を実行して依存関係の集約は完了です。
依存管理を集約する前は手作業も多く、依存関係の更新作業に数時間かかることもありました。集約後はコマンド 1 つ実行すると数分で依存関係の更新ができ、Diamond Dependencies の問題を解決するための"One-Version Rule"も実現できました。今後は原則としてリポジトリ内で使われているライブラリは集約管理していきます。リポジトリ全体で使ってるバージョンと異なるバージョンを使う必要がある場合は、これまでのように個別で管理もできるのでそのように対応する予定です。
pex による Python 環境のパッケージング
pex とは
Pants は、pex 形式の Python 仮想環境を構築できます。pex ファイルは、サードパーティのパッケージを含めた Python 仮想環境を zip 形式でパッケージングした実行ファイルです。これにより、必要なライブラリや依存関係を含んだ環境を 1 つのファイルにまとめることが可能となります。Python インタープリタが存在する環境であれば、pex ファイルを実行することで、それぞれ独立した仮想環境上でコードが実行されます。また、pex の仮想環境内のパッケージのみを使用するか、システムの Python 環境に存在するパッケージも利用するかは pex の設定で選ぶことができます。
以下に pex の使用例を示します。まず、pex コマンドを実行する際に必要なパッケージを指定します。すると、指定したパッケージとその依存関係を含む pex ファイルが生成されます。生成された pex ファイルを実行すると、Python インタープリタが起動し、ファイルに含まれるパッケージを使ってコードを実行できます。
$ pip install pex # pex をインストール $ pex pydantic pip -o demo.pex # pydantic と pip を含む pex ファイルを作成 $ ./demo.pex -m pip list # pex ファイル内のパッケージを確認 Package Version ----------------- ------- annotated-types 0.5.0 pip 23.2.1 pydantic 2.3.0 pydantic_core 2.6.3 typing_extensions 4.7.1 $ ./demo.pex # pex ファイル内の Python インタプリタを実行 Python 3.11.3 (main, Apr 7 2023, 20:13:31) [Clang 14.0.0 (clang-1400.0.29.202)] on darwin Type "help", "copyright", "credits" or "license" for more information. (InteractiveConsole) >>> import pydantic >>> pydantic.VERSION '2.3.0' $ unzip -l ./demo.pex # pex ファイルの中身を確認 # 省略
Pants による pex の構築
Pants を使って pex ファイルを構築すると、Pants が必要なサードパーティのパッケージと自作のコードの依存関係を自動的に検知し pex ファイルを構築してくれます。どのサードパーティパッケージと自作のコードを含めるかを、ほとんどの場合において明示的に指定する必要がありません。特定の場合には明示的な指定が必要になるかもしれませんが、基本的に Pants が最適な依存関係を推測してくれるので、開発者はシンプルで効率的なビルドプロセスを実現できます。
Pants を使って pex を構築する例が次になります。main.py を実行すると、pydantic のバージョンが表示されます。
# dir構成
.
├── BUILD
├── lib
│ ├── BUILD
│ └── foo.py
├── main.py
└── pants.toml
# lib/foo.py import pydantic def get_pydantic_version(): return pydantic.VERSION
# main.py from lib.foo import get_pydantic_version if __name__ == '__main__': print(f"pydantic {get_pydantic_version()}")
# lib/BUILD python_requirement( name="pydantic", requirements=["pydantic"] ) python_sources()
# BUILD python_sources() pex_binary( name="pex-demo", entry_point="main.py", )
# pants.toml
[GLOBAL]
pants_version = "2.17.0"
backend_packages = [
"pants.backend.python",
]
$ pants run main.py # pex ファイルを作成せずに実行 pydantic 2.3.0 $ pants package :pex-demo # pex ファイルを作成 05:07:12.53 [INFO] Completed: Building pex-demo.pex with 1 requirement: pydantic 05:07:12.53 [INFO] Wrote dist/pex-demo.pex $ ./dist/pex-demo.pex # pex ファイルの実行 pydantic 2.3.0
このように Pants を使って pex ファイルを構築することで、Pants が依存関係を自動的に検知して pex ファイルにパッケージングしてくれます。パッケージングの際に開発者は自作のコードとサードパーティのパッケージの依存を意識する必要がありません。上記の例では、main.py から lib/foo.py をインポートしています。lib/foo.py からインポートされている pydantic が自動的に検知され、これらが pex ファイルに含まれています。
pex を用いたコンテナイメージの構築
pex を使うとポータビリティが高まり、コンテナイメージの構築もシンプルになります。pex を使わない場合、コードを参照するために Dockerfile 内で各ファイルやディレクトリを都度 COPY する必要があります。依存するファイルが増えるほど、Dockerfile の記述が大変になります。以下にその例を示します。
FROM python:3.11-slim COPY requirements.txt . RUN pip install pydantic==2.3.0 COPY lib/foo.py lib/foo.py # 依存するファイルが増えるほど COPY の記述が大変になる COPY main.py main.py CMD ["python", "main.py"]
一方、pex ファイルを使用する場合はそのファイルを COPY するだけでアプリケーションを実行できます。これにより、リポジトリ内の様々な場所から関連するコードを集める作業が不要となり、Dockerfile の記述をシンプルにできます。
FROM python:3.11-slim COPY pex-demo.pex pex-demo.pex CMD ["./pex-demo.pex"]
pex をコンテナ環境で使用することで、ポータビリティを向上させるだけでなく、コンテナイメージのサイズの削減がしやすくなります。イメージサイズを小さくすることで、コールドスタートの時間を短縮したり、スケールアウトの速度を改善できます。コンテナイメージを構築する際にイメージサイズを小さくする tips は様々あります。Python では、依存ライブラリのインストールのキャッシュを無効化・削除したり、multi-stage build で venv を COPY するなどしてイメージサイズを小さくできます。pex を使うと、これらの知識を必要とせずにイメージサイズを小さくできます。こちらの記事では venv を使った multi-stage build 時のイメージサイズと pex を使った時のイメージサイズが比較しており、pex の利用でコンテナイメージを小さく保てることがわかります。
| image size | |
|---|---|
| multi-stage build なし・キャッシュ削除なし | 1.29GB |
| venv を使った multi-stage build | 66MB |
| pex | 47.2MB |
実際にチームでは、pex を用いたコンテナイメージをVertex AI Pipelineで構築した機械学習パイプラインやVertex AI Endpointのサービングの場面で積極的に活用しています。
プロジェクトの依存関係を制御する:Pants の visibility 機能の活用
コードベース内で不適切な依存関係が形成されるとコードの修正や追加が難しくなったり、バグの原因になります。この章では依存関係を適切に管理するために役立つ、Pants の visibility 機能についてご紹介します。
Pants の visibilityは、API やモジュールの依存許可や禁止をコントロールする機能です。これを活用することで、特定の API やモジュールを他のコードから隠蔽したり、公開範囲を制限することが可能となります。これにより、意図しない依存関係の形成を防止できます。
開発プロセスの中には、一時的な実装のためのコード(以下「sandbox コード」と呼びます)を作成する場面があります。これらの sandbox コードが参照されると、そのコードの改変や廃止が困難になったり、バグの原因になることがあります。
このような問題を未然に防ぐため、私たちのモノレポでは「他からの依存禁止ルール」を適用した sandbox ディレクトリを設け、一時的なコードや試験的な実装をそこに配置しています。これにより、sandbox ディレクトリ内のコードは他のコードから切り離され、安全に共有・開発することが可能となります。
依存禁止ルールが適用されたディレクトリのコードを参照しようとすると、次のようなエラーメッセージが表示され、ルールが適用されてることが確認できます。
$ pants test projects/foo/:: 10:57:00.07 [INFO] Initialization options changed: reinitializing scheduler... 10:57:15.32 [INFO] Scheduler initialized. 10:57:19.34 [ERROR] 1 Exception encountered: Engine traceback: in `test` goal DependencyRuleActionDeniedError: projects/foo/tests/test_main.py has 1 dependency violation: * BUILD[!projects/sandbox/**] -> projects/sandbox : DENY python_tests projects/foo/tests/test_main.py -> python_sources projects/sandbox:src
コードベースで何でもかんでも公開して参照できる状態すると、知らぬ間に複雑な依存関係が形成されてメンテナンスが大変になることが想定できます。『Software Engineering at Google』の書籍にも書かれているように公開するターゲットを最小限に止め、依存関係が複雑にならないように心がけています。
まとめ
ここまでモノレポのメリットを活かしながら、開発効率を高めるための様々な取り組みについて紹介しました。Pants による依存関係管理、pex ファイルの活用、CI の待ち時間の短縮、依存関係の集約管理による効率化を行いました。これらの取り組みによって、モノレポでの開発効率を高めることができました。今後もモノレポの改善を続けながら、事業に素早く貢献できるようにしていきます。
link
YOUTRUST(9/25 まで) CADDi Tech 機械学習エンジニア求人