こんにちは。ソフトウェアエンジニアの江良です。
普段は Web アプリケーションのコードをせっせと書いて暮らしているのですが、AI Lab の誕生に伴い、機械学習を専門とするエンジニアと協業する機会も増えてきました。 今回は、機械学習の研究開発プロジェクトで導入した Streamlit というフレームワークについて紹介しようと思います。
Streamlit とは
Streamlit は Python で Web アプリケーションを作成するためのフレームワークです。 機械学習エンジニアやデータサイエンティスト向けに設計されており、Python のコードを数行書くだけで、可視化のためのカスタムアプリケーションを簡単に構築することができます。
「機械学習のモデルを評価するためのデモ用のアプリケーションを作りたい」「あくまでデモ用なので、労力はできるだけかけずに済ませたい」という今回のユースケースにぴったりのツールだったため、導入してみることになりました。
Streamlit を触ってみよう
Streamlit は pip でインストールすることで使えます。
pip install streamlit
詳細は 公式ドキュメント に譲りますが、ほんの数行のコードを書くだけで簡単にグラフィカルなアプリケーションが実装できます。
import streamlit as st
x = st.slider('Select a value')
st.write(x, 'squared is', x * x)
作成したアプリケーションは以下のコマンドで起動できます。
streamlit run main.py

チュートリアル に載っている 30 行ほどのコードを書くだけでこんなアプリケーションも作れます。

Streamlit の威力をなんとなく感じていただけたでしょうか?
Streamlit アプリケーションを公開しよう
Streamlit Cloud の紹介
Streamlit で書いたアプリケーションは Streamlit Cloud というサービスを使うことで簡単にホスティングできます。 作成したアプリケーションを全世界に公開することもできますし、有料の Teams プランに加入すれば社内だけに限定して公開することもできます。
公式ドキュメント を参考に Streamlit Cloud にサインアップし、GitHub リポジトリ、デプロイしたいブランチ名、main ファイルのファイルパスを入力して少し待つだけで、簡単に Streamlit アプリケーションをデプロイできます。


アプリケーション、インフラ構成の紹介
次に、今回作成したアプリケーションの構成について触れていきます。
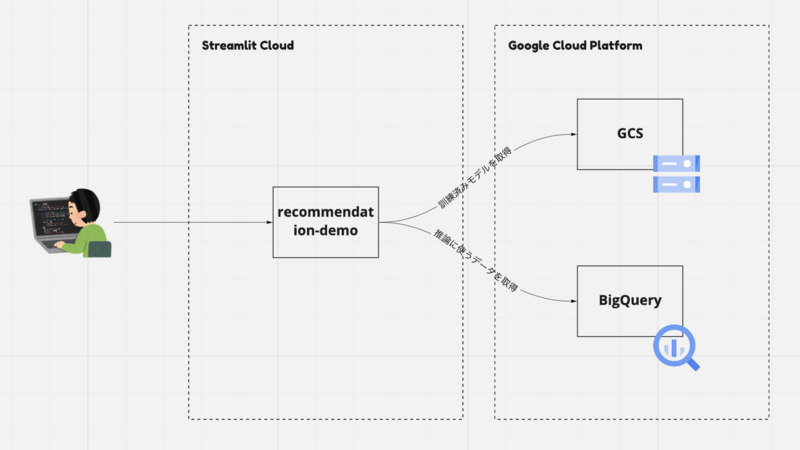
構成については、ざっくり以下の通りです。
- 訓練済みのモデルは GCS に配置し、推論時に取ってくる
- 推論に使うデータセットは BigQuery から取ってくる
- GCP の各サービスにアクセスできるよう Service Account を作成し、credential を参照させる
Streamlit の Secrets Management という機能を使うと、credential のようなセンシティブな情報を安全に保存し、Streamlit のアプリケーションから環境変数越しにアクセスさせることができます。
st.secrets を参照するようにアプリケーションのコードを書き換え、
def get_credentials():
if "gcp_service_account" in st.secrets:
return service_account.Credentials.from_service_account_info(
st.secrets["gcp_service_account"]
)
else:
return None
Streamlit Cloud の「Advanced settings」に指定することで Secrets を使用できるようになります。

Streamlit Cloud のハマりどころ
ここまで Streamlit、Streamlit Cloud の良いところを紹介してきました。 この勢いのまま Cloud 上にさくっと持っていけると良いのですが、 Streamlit は2018 年に公開されたばかりの比較的新しいフレームワークのため、実務で利用するにあたってはいくつか落とし穴も存在します。
メモリが足りない
Streamlit Cloud は使用可能なメモリに制限があります。 (2022/02/14 現在で、Free プランなら 1G、Teams プランなら 3G が上限となります。)
この制限を超えてしまうと、 Oh no. のメッセージとともに Streamlit アプリがクラッシュしてしまいます。

この問題を解決するには、Streamlit のキャッシュ機能を正しく活用することが鍵になります。
キャッシュ機能は、キャッシュしたい処理の関数に @st.cache を指定することで設定できます。
@st.cache
def load_data(nrows):
data = pd.read_csv(DATA_URL, nrows=nrows)
data[DATE_COLUMN] = pd.to_datetime(data[DATE_COLUMN])
return data
キャッシュが効かない
ところが、この @st.cache を使用するだけでは問題が解決しないケースがあります(つらい)。
Experimental cache primitives - Streamlit Docs によると、 @st.cache の単一 API であまりにも多くのユースケースをカバーしようとした結果、処理が遅く複雑になってしまったとのこと。
この問題を解決するために、streamlit v1.0 から @st.experimental_singleton と @st.experimental_memo という API が追加されました。
クレデンシャルオブジェクトなど、一回だけ初期化したいもの(かつセッション間で共有されて問題ないもの)については @st.experimental_singleton が使用できます。
@st.experimental_singleton
def get_credentials():
if "gcp_service_account" in st.secrets:
return service_account.Credentials.from_service_account_info(
st.secrets["gcp_service_account"]
)
else:
return None
データを返す関数には @st.experimental_memo が使用できます。
@st.experimental_memo
def load_data(nrows):
data = pd.read_csv(DATA_URL, nrows=nrows)
data[DATE_COLUMN] = pd.to_datetime(data[DATE_COLUMN])
return data
これらの問題を解決したところ、無事デモ用のアプリケーションが Streamlit Cloud 上で動作するようになりました :tada:
おわりに
以上、Streamlit と Streamlit Cloud の紹介でした。
Streamlit をうまく活用できたおかげで、機械学習のモデルの評価も順調に進み、現在は「機械学習を実際のアプリケーションにどう組み込むか」を議論するフェーズにたどり着くことができました。 (ぼくが担当したのは Streamlit Cloud を使えるようにするための設定と若干のコード変更だけでしたが)研究開発の成果がきちんと「次」につながっていく場に立ち会えるのは嬉しいですね。
We're hiring
キャディでは、機械学習のタスクを実装し、結果を可視化して高速に改善することで、モノづくり産業のポテンシャルを解放するプロダクトを開発するエンジニアを募集しています。
ところで、ぼくの専門はバックエンドエンジニアです。こちらのご応募もお待ちしております。