はじめに
こんにちは、キャディAILab MLOpsエンジニアの廣岡です。MLOpsエンジニアの業務では、機械学習エンジニア(MLE)の開発したモデルのデプロイ面の協働や、それらを含む機械学習基盤の開発・運用などを担当しています。最近は特にモデルデプロイに伴うチェック内容の自動化や、各ライブラリのアップデートを安全に実施するためのCI/CDの整備などに取り組んでいます。
本稿では、AILabが運用する図面解析ETL基盤、および開発に際して得られた知見や悩みを記載します。読者の方の参考になれば幸いです。
TL;DR
- 社内オペレーションにおいて、膨大な図面に対する解析とその結果に対するアクセスが必要となっていた
- 社内のアプリケーションにアップロードされた図面に対して、機械学習を用いた画像解析を実施し、解析結果をデータベースに格納するETL(Extract、Transform、Loadからなるデータ処理)基盤を構築した
- 結果として、アップロードされた図面群に対して当初目標としていた「30分以内に図面10000枚の解析完了」を達成することができた :tada:
背景
キャディでは業務の中で膨大な量の図面を扱っています。こうした膨大な量の図面を全て人手でチェックするのは大変なため、図面の取り扱いに際するオペレーションを自動化することで、業務効率化や情報抽出の高度化・均一化が期待できます。今回紹介するETL基盤もそうした自動化の一端を担っており、機械学習によって図面からの情報抽出を行います。
本稿で紹介するETL基盤の構築以前から、キャディでは社内向けのML APIをホストするAPI基盤が構築されていました(詳しくは以前のブログ投稿をご参照ください)。このAPIを用いることで、社内のアプリケーションから図面に対する機械学習の解析結果を取得することができていました。
一方でこうしたAPIの利用者はエンジニアを想定していたため、非エンジニアからは利用しづらいと言う課題がありました。これに対して、例えばBigQueryのようなストレージに解析結果を格納しておくことで、多くの社員が図面の解析結果にアクセスでき、機械学習の価値を享受できるようになります。こういった背景から、図面情報のETL基盤の開発が検討されました。
ETL基盤の開発にあたっては、「10000枚の図面データ入力に対して30分以内に解析結果をアクセス可能な状態にする」という、処理性能の数値目標を定義していました。詳細は割愛しますが、これは図面情報を用いる業務オペレーションから逆算した数値となっています。
プロダクトの開発に際してはDesgin Docという資料をまとめており、開発の基礎としています。上記の開発背景や数値目標の他にも、ユーザーストーリーや機能要件、プロダクトのスコープが意図する要素などを整理して記載しています。これらをチームとして考え合意しておくことで、必要なことにフォーカスし、不要なものを作らないことが期待できます。
ETL基盤のアーキテクチャ
ETL基盤の開発前には、インポートされた図面に対して採番(ID付与)を行う図面管理基盤と、MLモデルをホストするAPI基盤がありました。これらを踏まえて以下のようなアーキテクチャのETL基盤を構築しました。
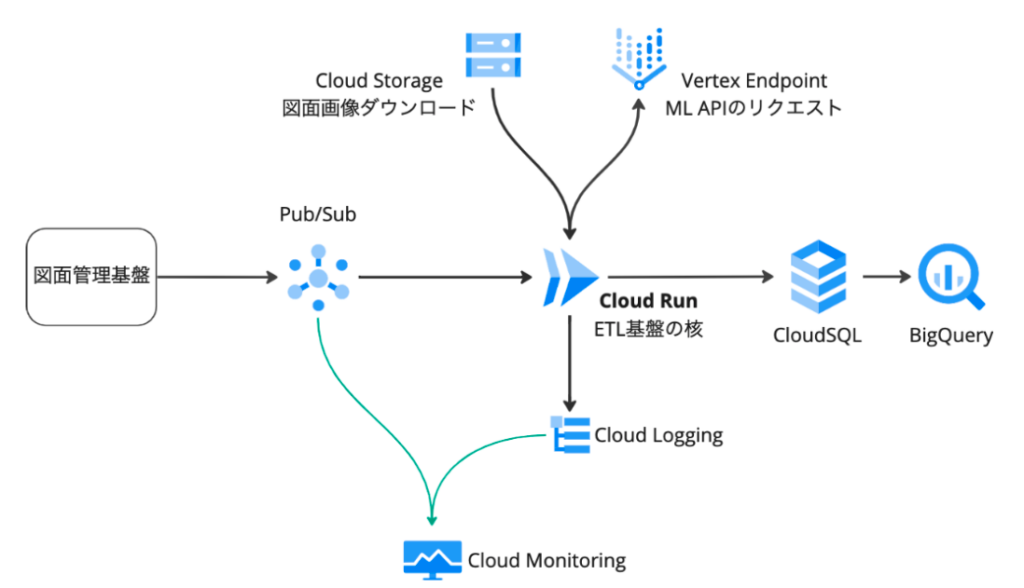
AILabでは基本的にGoogle Cloudのサービスを利用しています。今回のETL基盤の核となっているのは中央のCloud Runにデプロイされるサービスであり、下記の流れで、図面の情報抽出を実施します。
- 図面管理基盤に図面がインポートされると、Pub/Subトピックにメッセージが発行される
- Pub/Subからのプッシュサブスクリプションによって、Cloud Runにリクエストが送られる
- Cloud RunからVertex Endpoint(ML API基盤)にリクエストを送り、図面に対する解析結果を得る
- 解析結果をCloud SQLに格納する
- (BigQueryを介してCloud SQLにクエリすることで、解析結果が閲覧できる)
またPub/Subメッセージの状態や、Cloud Runのログや各種リソースの動作状況はCloud Monitoringに取り込まれ、処理が問題なく進んでいるかをチェックできるようになっています。
開発時の議論
開発を進める際には、各リソースの動作確認や構成の議論が必要でした。ここではその一部を紹介します。
スケーラビリティ
図面管理基盤への図面のインポートはまとめて行われるため、リクエストの変動が激しくなることが予想されました。Cloud Runを用いることで迅速なスケールアウトが期待でき、リクエスト数に応じたスケーラビリティを獲得できると感じています。
一方でVertex Endpointで提供されるML API基盤は機械学習モデルを搭載しているためか比較的スケールアウトが遅い場合がありました。これをETL基盤の問題と捉えるかは微妙なところですが、「30分以内に10000枚の図面を解析」と言う目標に対しては致命的なほどではありませんでした。しかし今後さらに大量の図面を扱う場合や、高速な処理が求められる場合は改善が必要と感じています。
処理のリトライ
一度に大量の図面に対してETLを実行する場合、ML APIのスケールアウトが間に合わないなどの理由で、一部の図面に対して処理が失敗することが考えられました。
これに対するリトライ処理はPub/Subのリトライ機能を利用しており、処理が成功するまで一定時間リクエストを送り続けます。時間経過に応じてインスタンスのスケールアウトなどが間に合うと処理が成功し、結果がデータベースに格納されます。
解析結果へのアクセス権管理
解析結果はCloud SQLに格納され、ユーザーからはBigQueryを介してクエリを実行し、各図面に対応した解析結果を得られます。
BigQueryへのアクセス権はTerraformを介してIAMによって付与しています。アクセスが必要な際にはMLOpsチームに連絡してもらう運用にしており、これによって解析結果にアクセスできるユーザーやグループを管理しています。
リリースに伴う動作チェック
ETL基盤のリリースに際しては、開発環境での疎通確認や、ステージング環境での負荷テストなどを実施しています。特に負荷テストでは、「30分以内に10000枚の図面を解析」の性能指標が達成できているかを確認するため、実際に10000件の図面を投入し、処理性能が問題ない範囲で収まっているかを確認しています。
ML APIの増加に伴う失敗率の増加
本稿のETL基盤では、一つの図面に対して複数のML APIによる解析を実行しており、全て完了した後に結果をデータベースに格納しています。この時Vertex Endpointのスケールアウトなどの要因でAPIのどれか一つでも失敗すると、ETLの実装上一図面に対する解析がまとめて失敗となっていました。リトライ時には、元々成功していたAPIも再度リクエストを送る必要があり、処理時間の増加につながってしまいます。
この課題は暫定的にVertex Endpointの最小インスタンスを増やすことで対応しましたが、APIごとに解析結果を随時保存するように、アーキテクチャと実装を鋭意改善しています。
ユースケースの拡大と社内の認知向上
今回紹介した図面ETL基盤は、社内の非エンジニアの特定オペレーションに際して、大量の図面を効率的に扱うために開発されました。今後実際にオペレーションに組み込まれていく中で、精度や処理性能面のさらなるブラッシュアップができると良いと感じています。
また元々想定していたオペレーション以外にも、ETL基盤による図面情報の提供は、図面を扱う多くのオペレーションに有用であるとも考えています。これに対しては、社内のSlackで宣伝したり、必要に応じて抽出できるデータやデータベースのアクセス方法を紹介する機会を作ったりしています。一方で、さまざまなユースケースが混在するとシステムの要件が複雑になる可能性もあるため、今回のETL基盤が本当に適しているのかはよく見極めて進めたいと考えています。
まとめ
本稿では、キャディ社内でAILabが開発・運用している図面に対するETL基盤を紹介しました。他にもMLOpsチームとしては下記の課題や機能候補なども検討しており、今後さらにブラッシュアップしていきたいと感じています。
- API単位でのリトライ
- Pub/Subなど外部サービスに依存している箇所のテスト
- バッチ推論への対応
本稿で紹介したETL基盤では、Google Cloudのマネージドサービスを使いながら「30分以内に10000枚の図面を解析」という目標を達成できました。これを用いてキャディのビジネスをさらに加速していきたいと考えています。