※本記事は、技術評論社「Software Design」(2023年4月号)に寄稿した連載記事「Google Cloudで実践するSREプラクティス」からの転載です。発行元からの許可を得て掲載しております。
はじめに
キャディ株式会社の前多です。筆者はPlatformグループという部署で、クラウドインフラの整備や開発組織横断の技術課題の解消に携わっています。 キャディでは製造業向けのビジネスを展開しており、社内外向けにSaaSを含む多くサービスを運用しています。また、事業展開にあわせて常に新たなプロダクトが開発されています。
各サービスには担当の開発チームが組織されていて、開発・運用に責任を負っています。筆者らPlatformグループは、開発チームが自律的にユーザーへの価値提供に集中できることを目標に、SREプラクティスの導入、信頼性の高いサービス基盤やサービス横断の機能開発といった活動をしています。 サービスの開発・運用主体は開発チームであるため、筆者らは個々のサービスに対するインフラ構築やサービス運用、アーキテクチャ設計や言語・ライブラリ等の技術選定といった作業を行いません。開発チームがこれらを主体的に進められるよう、サービスの基盤や監視基盤を整えたり、ガイドの作成や啓蒙、SREプラクティスの実践サポートなどが主な役割です。
筆者らPlatform グループと開発チームの関係は次の図のようになります。 詳しくは弊社のブログで紹介していますので、興味ある方はぜひ ご覧ください。
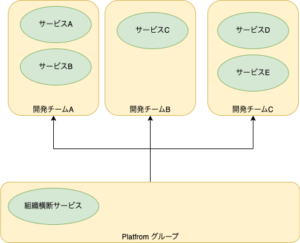
現在のキャディは事業成長フェーズにあり、開発組織の拡大に伴い、さまざまな課題が発生しています。このような状況に対応するため、Platformグループでは、少人数でもレバレッジの効くような戦略的・技術的な解決手法の提供も目指しています。 その取り組みの1つが、高い信頼性と開発組織のスケールへ追従できるサービス基盤の提供です。 この連載では、筆者らが提供するGoogleCloudを中心とした組織横断の基盤について、技術選定の方針と、採用している各種技術要素について解説していきます。
信頼性とは何か
信頼性とは、サービスが一定の条件下で要求された機能を果たす性質であり、サービス利用者が遅延や障害などにより機会損失する度合いを管理していくことです。 ソフトウェアエンジニアリングによってサービスの信頼性を向上させる役割を果たすのが、Googleによって提唱されたSRE(Site Reliability Engineering)です。
書籍『SRE サイトリライアビリティエンジニアリング ―Googleの信頼性を支えるエンジニアリングチーム』や、Google Cloud の SRE ページでは、SREのマインドセットやツールセットについてべられています。
高い信頼性を示すには、信頼性を数値化して計測することが必要です。以前から信頼性の尺度としてMTBF(平均故障間隔)、MTTR(平均復旧時間)といったものがあり、最近ではSREプラクティスの1つとして紹介されたSLI(サービスレベル指標)、SLO(サービスレベル目標)を使うこともあります注4。筆者らもサービスごとにSLI、SLOを定義して監視・運用することを標準化し、開発チームへの導入を始めたところです。 信頼性を高く保つためには、信頼性の可視化だけではなく、サービスの品質を底上げしていくための取り組みも必要です。そのために筆者らが導入している技術要素を次に見ていきます。
コラム : 信頼性の尺度
MTBF(平均故障間隔)はサービスが故障せずに稼働できる平均時間で、長いほど故障がしづらいと言える尺度です。一方MTTR(平均復旧時間)はサービスが故障から復旧までにかかる平均時間で、短いほど故障から復旧が早いと言える尺度です。 この2つの尺度からMTBF÷(MTBF+MTTR)を計算すると稼働率が得られます。たとえば稼働率が99% なら、年間でサービスが停止しているのは約87時間、月間では約7時間です。信頼性を計測する方法の1つとして、目標とする稼働率を設定して実際の稼働率を計測します。 SLI(サービスレベル指標)とSLO(サービスレベル目標)は、サービスの利用者がサービスを安定して使えているかという観点で設定します。SLIは、サービスの状態を計測して定量化した値です。サービスの特性によって独自に決めます。汎用的なものとして、サービスへのリクエストの遅延時間やエラー率などがあります。 一方でSLOは、サービスが安定して稼働しているかを判断するためのSLIの目標値です。 たとえば「月間のエラー率(SLI)を1%以下にする」といったものです。SLOを満たしていないようであれば、SLOを満たすために改善作業を実施します。
SLIとSLOについて詳しくは、Googleが公開している The Art of SLOs を参照してください。
技術選定の観点
サービス基盤の技術選定に際して筆者らは次の4点を重視しています。
- IaC(Infrastructure as Code)
- 自動化
- 可観測性(Observability)
- セキュリティ
IaC(Infrastructure as Code)
筆者らが使用するパブリッククラウドやSaaSの構築作業は、可能な限りコード化(IaC)し、CI/CDパイプラインに載せて作業を自動化しています。APIが提供されているツールを選択し、UIが提供されていたとしても手動による変更は原則として行いません。 こうすることで、複数環境の構築や複製が簡単になったり、環境に加えた変更の差分が明確になるといった利点があります。また、コード化によってインフラ構築のノウハウが形式知化されるので、属人性の排除や手順書に基づくインフラ構築といった煩雑な作業からの解放につながります。 IaCと次に説明する自動化により、サービス拡大に伴うインフラ構築の負荷を最低限に減らすことができます。
自動化
信頼性を高く保つためには、サービスの品質を上げることが重要です。 そのためには「テストをしてバグを減らす」「最新のライブラリを使う」「新機能や改善を取り込んだサービスを早くリリースする」などの行動が必要です。これらの行動を繰り返すことで品質は向上します。 繰り返しの速度を上げるためには、自動化が欠かせません。 自動化の方法として CI(継続的イングレーション)とCD(継続的デプロイメント)が知られています。 キャディでもこの2つを合わせたCI/CDパイプラインを整備して、サービスのテスト、ビルド、デプロイを繰り返し実行できるようにしています。 また、自動化の推進によって、特定の人しかデプロイができないといったような属人化を減らすことにもつながります。
可観測性(Observability)
信頼性を計測するためには、稼働しているサービスから指標となるデータを取得する必要があります。また、パフォーマンスの劣化やサービス障害に対する調査も、勘に頼ったり場当たり的に行ったりするのではなく、実測値に基づいて行うことが重要です。 そのために、サービスや利用するツールからログやメトリクスなどのデータが取得できること、それらのデータを一元的に収集して分析可能であることを重視します。
セキュリティ
キャディでは創業当初からシステムのすべてがパブリッククラウドやSaaSにあるため、社内ネットワークのような閉じたネットワークはありません。また、多くの社員がリモートワークをしています。 そこで、筆者らはゼロトラストネットワークの考え方の基づいてサービスを構築しています。 システムへのリクエストは、原則として正当性の検証が必要であり、そのための認証認可や監査のしくみの標準化を進めています。 また、DDoS攻撃のような脅威からサービスを守るための方法も検討しています。
安定したサービス基盤に使う技術
前述した技術選定の観点をふまえて、キャディのサービスが稼働している環境で実際に使っている技術を端的に紹介します。詳しい内容は今後の連載で掘り下げていきます。 なお、これらのツールは現時点のキャディにマッチしていると考えているものであり、唯一の正解だとは考えていません。必要に応じて見直し、ときにはツールを入れ替えるなどの判断もしていきます。
これから紹介する技術の全体像は次の図を見てださい。必要な要素以外は割愛してあります。

Google Cloud
キャディのサービスは、ほぼすべてがGoogleCloudのインフラ上で動いています。 筆者らがおもに使っているGoogle Cloudのサービスは次のものです。
- Google Kubernetes Engine (GKE / マネージド Kubernetes)
- Cloud Run (コンテナベースのPaaS)
- BigQuery (データ分析基盤)
- Cloud SQL (RDBMS)
- Vertex AI (機械学習プラットフォーム)
- Anthos Service Mesh (マネージド サービスメッシュ)
- Cloud Logging (ログ収集)
- Cloud Trace(分散トレーシング)
創業間もない2018年当時、サービスをすばやく開発・提供するにはパブリッククラウドを使うことが必然でした。 創業当時の社員にGoogleCloudの選定理由を聞いたところ、実は明確な理由があったわけではなく、社員のアカウント管理でGoogle Workspaceを使っていたから、とりあえずGoogle Cloudを選択したとのことでた。 また、2018年当時はアプリケーションをコンテナ化してデプロイすることが注目された時期であり、当時の開発メンバーもコンテナ化を検討していました。そのときにGoogle Cloudの東京リージョンでGKEが開始されたのは、大きな後押しになりました。 もちろん、Google Cloud以外のパブリッククラウドにも類似のサービスはありますがGoogleCloudを使っていて良かった点をいくつか紹介します。
まずは BigQuery です。キャディでは BigQueryに社内のデータを集約し、開発組織以外の社員もデータを閲覧・分析しています。 データ容量がスケールでき、BigQueryにデータを投入する方法が豊富であるため、データ分析基盤として初期投資が不要で使いやすいことが利点です。
次にCloud Runです。コンテナを基本としたアプリケーションの基盤としてキャディではGKEを使っていますが、小規模のサービスではCloud Runを使う機会も増えています。コンテナ化の知見がそのまま利用できるのに加え、運用監視に必要な可観測性を最初から備えているためです。 さらにAnthos Service Meshも良かった点ですが、これついては後述します。 また、筆者が個人的に気に入っている点は次の2点です。
- プロジェクト単位でGoogle Cloud のサービスをまとめられる
- IAMによる権限制御ができることです。
多数のキャディのサービスをGoogle Cloudのプロジェクト単位でまとめることで、効率よく管理できています。
IaCに関する技術
IaCに関しては次の2つを使用しています。
- Terraform
- Argo CD
Terraform
Terraform はOSSのインフラ構築ツールです。インフラリソースの構成をコードとして記述し、その内容を現在のインフラ構成と比較・検証して差分反映できるため、インフラ構築作業や設定変更を自動化できます。
同様のツールはAnsibleやAWS Cloud Formationなどほかにも存在しますが、Terraformは「Provider」というしくみで拡張できるようになっており、AWSやGoogle Cloudなどのパブリッククラウドだけでなく、キャディで採用しているSaaSについてもProviderが提供されています。そのため、Terraformのコードでインフラの大半を制御できます。
Argo CD
Argo CDはKubernetesへの継続的デリバリーを通じて行うツールです。 Gitリポジトリをソースとしてを継続的デリバリーを行う手法を「GitOps」と呼びます。Argo CDはKubernetesへのデプロイをGitOpsに沿って行います。
通常、Kubernetesへのデプロイは、デプロイ内容を記述したマニフェストファイルKubernetes APIやkubectlコマンドに指定して実施します。 この作業は、ファイル数が増えると煩雑になるほか、ファイルの変更を追従してKubernetesに反映することが困難になります。 Argo CDは、gitリポジトリにあるマニフェストファイルを取得し、Kubernetesへのマニフェストファイルの適用状況を可視化します。また、差分検知、履歴管理、ロールバック、自動反映といった機能も備えています。 権限制御可能なWeb UIがあるため、Argo CDを通してKubernetesにデプロイされているサービスの構成を把握したり、管理者のみがArgo CD経由でデプロイ操作をしたりするといった操作もできます。
自動化に関する技術
自動化に関する技術は次の2つを使用します。
- GitHub Actions
- Renovate
GitHub Actions
GitHub Actionsは、GitHub上で提供されるCI/CDツールです。GitHubへのプッシュやプルリクエストなどのイベントをトリガーとして、任意の処理を実行できます。 キャディでは当初CI/CD基盤としてCircleCIを採用していましたが、現在ではGitHub Actionsへの一本化を進めています。その理由は次の3点です。
OpenID Connect連携によってGoogle Cloudのリソースをクレデンシャルを介することなく扱えます。 これによって、CI/CDパイプラインから安全にTerraformのコマンドが実行できるようになり、インフラ構築の自動化に役立ちます。 筆者らは、プルリクエストのマージをトリガーとしてTerraformを実行し、インフラ構築作業をCI/CDで行うことを徹底しています。
Renovate
Renovateは、依存性の更新を自動化するツールです。 現在のソフトウェア開発では、さまざまなツールやライブラリに依存していますが、それらは絶えずアップデートされています。なかには脆弱性の対策によるアップデートもあるため、そのような更新は早めに気づき対応する必要があります。 Renovateは、GitHubリポジトリの内容から依存性を抽出し、最新版があればその内容や更新をプルリクエストとして作成します。 キャディでは100を超えるGitHubリポジトリがあり、多くのリポジトリの依存性の更新チェックを自動化するためにRenovateを導入しています。
可観測性に関する技術
可観測性に関しては次の4つの技術を使います。
- Anthos Service Mesh
- Datadog
- Cloud Logging
- Cloud Trace
Anthos Service Mesh
Anthos Service MeshはGoogle Cloudが提供するマネージドのサービスメッシュです。 サービスメッシュは、Kubernetes上のサービスにアクセスログやメトリクスといった可観測性を与えたり、ネットワークのセキュリティ向上や通信制御といったさまざまな機能を追加したりします。サービスメッシュを導入することで、開発者の作ったサービスに対して、一定品質の可観測性やセキュリティを一律に付与できます。 オープンソースのサービスメッシュとしてはIstioが有名ですが、多くのコンポーネントを連携させる必要があるため、導入や運用の負荷が非常に高いのが難点です。 Anthos Service Meshは、Istioベースでありながら、Google Cloudによるフルマネージドサービスであるため導入が簡単です。自動バージョンアップなども備えているため、運用負荷が低減できます。
Datadog
Datadogは複数のクラウドに対応した運用監視SaaSです。キャディで実行する大半のサービスのログやメトリクスを収集し運用監視を行っています。SLI/SLOをはじめとした負荷状況・稼働状況の可視化、サービス異常を検知と通知、外形監視によるサービスの死活監視、証明書期限チェックなどに活用しています。 運用監視サービスは多くの製品がありますが、次の点から選定しました。
Cloud LoggingとCloud Trace
Cloud LoggingはGoogle Cloudが提供するログ収集サービスで、Cloud Traceは分散トレーシングのサービスです。 どちらもGoogle Cloud内部のアプリケーションやインフラの可観測性に関するデータを収集します。 Cloud LoggingのデータはDatadogでも収集しており、Datadogと役割が重複していますが、次のように使い分けています。
- Datadog : 検索や可視化に優れるため、リアルタイムログ検索やダッシュボード、アラートの一元化に使用
- Cloud Logging : Datadogに収集していない一部のログの参照や、過去のログの検索に使用 (Detadogにすべてのログを集約するとコストがかかり、ログの保存期間にも制約があるため)
Cloud Traceは、複数のサービスのパフォーマンスデータを収集して可視化できるため、どのサービスが遅延や障害を起こしているかを調査するのに役立ちます。Datadogにも同様のサービス、DatadogAPMがありますが、 Cloud Traceのほうが低コストであるためCloudTraceを使っています。
また、監視サービスの Cloud Monitoringもありますが、Datadogと 重複するので積極的には利用していません。 ですが、Google Cloud Managed Service for Prometheusが登場したことで、より扱いや すくなりメトリクス収集の範囲が広がるという期待があり注目しています。
セキュリティに関する技術
セキュリティに関してはCloudflare を利用しています。Cloudflareは、インターネット上で提供するサービスに対して、CDN、TLS、ネットワークセキュリティ、エッジコンピューティングなど、さまざまな機能を提供します。
当初はキャディのWebサイトを動かしていたWordPressの負荷軽減のためにCDNを導入する目的で利用を開始しました。 しかし、現在ではセキュリティに関する機能を有効活用するために、すべてのサービスをCloudflareのCDN経由で公開しています。 利用している機能の一部は次の通りです。
- Cloudflare DNS: DNSレコードとTLS証明書を管理する
- Cloudflare Access: Cloudflare にホストしているサービスに認証プロキシを設定できる。社内システムへのアクセスをGoogle Workspaceのアカウントで認証できるようになる
- Cloudflare WAF: DDos攻撃や不正アクセスを検知しアクセスの遮断や通知を行う
- Cloudflare Workers: Cloudflareのネットワーク内でリクエストに応じて任意のプログラムを実行できる仕組。重要なデータへのアクセスに対して高度な認証を適用したり、監査ログを取得するために使用したりする
まとめ
今回は、信頼性を高めるための技術選定の4つの観点(IaC、自動化、可観測性、セキュリティ)について解説し、それらの観点から現在筆者らが使用している技術について紹介しました。 最初からこれらの観点があったわけではなく、試行錯誤を積み重ねた結果として今の形に型化できました。注力する技術を型化したことにより、技術トレンドに応じて柔軟に使用する技術を組み替えていけると考えています。 次回からは、各技術トピックについて詳しく解説していきます。どれか1つでも興味のある技術があれば幸いです。お楽しみに。