※本記事は、技術評論社「Software Design」(2023年12月号)に寄稿した連載記事「Google Cloudで実践するSREプラクティス」からの転載です。発行元からの許可を得て掲載しております。
はじめに
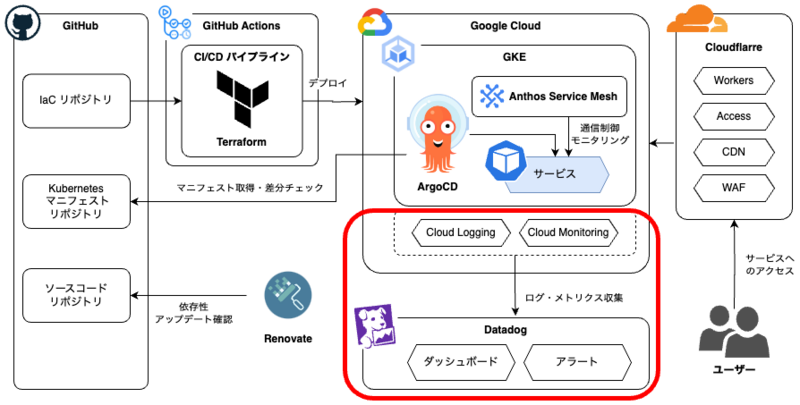
前回は、Google Cloudが提供するAnthos Service Meshを導入して、GKEで動くアプリケーションに可観測性やセキュリティなどの機能を追加する方法について紹介しました。今回はDatadog1を利用したモニタリング基盤について、Datadogの採用理由や基本機能、キャディでの活用事例を紹介します(図1)。
▼図1 CADDiスタックにおける今回の位置付け
Datadogとは
Datadogはクラウドベースの運用監視SaaSです。おもにクラウドプロバイダ(AWS、Azure、Google Cloudなど)やオンプレミス環境でのアプリケーションとインフラストラクチャの監視をサポートし、システムの状況をリアルタイムで追跡・可視化する機能を提供しています。 また、インフラストラクチャモニタリング、ログ管理などの用途でも利用でき、Kubernetes、NGINX、MySQLなどさまざまなサービスやアプケーションをサポートしているのもDatadogの特徴です。
なぜDatadogなのか
筆者らがDatadogを導入した2020年頃以前、キャディではGoogle Cloudが提供するCloudMonitoringを利用していました。キャディでは複数のGoogle Cloudのプロジェクトでさまざまなプロダクトを運用しています。それぞれの状態を確認するためには、Google Cloudの管理コンソール上で対象プロジェクトに移動する必要があり、操作が繁雑でした。このことから、モニタリングを一元化したいという要望が出てきました。 また、キャディはスタートアップ企業であるためプロダクト開発に注力する必要があり、独自の監視基盤を構築・運用する人的リソースを割くことができません。そのため、フルマネージドな監視基盤であるDatadogを採用することにしました。 Datadogはさまざまな特徴を備えますが、とくに筆者らの要件に合致したのは次のような点でした。
- さまざまな対象からログやメトリクスを収集して一元管理できる
- WebUI上でダッシュボードが簡単に作成できる
- クエリ定義による柔軟なアラート設定ができる
- Terraformが対応しており、設定をIaC化できる
これらの特性から、自社で運用する多くのプロダクトの状態をプロダクト軸・時間軸の両方で分析・監視でき、状況把握や障害対応の効率が大きく向上しました。
Google Cloud連携のしくみ
Datadogがクラウドサービスからログやメトリクスなどを収集するしくみを、Google Cloudとの連携を例に紹介します(図2)。
▼図2 DatadogとGoogle Cloudの連携方法
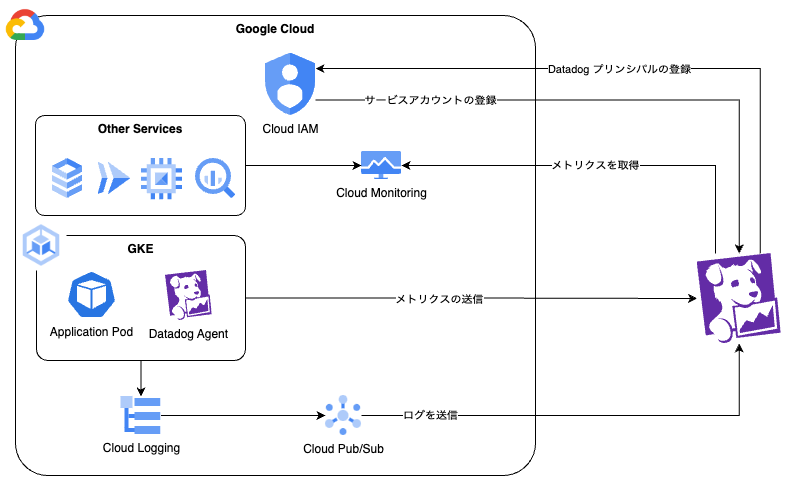
Google Cloudとの連携では、Datadog向けに用意したサービスアカウントを通じて認証します。Datadogはこのサービスアカウントを利用してGoogle CloudのAPIをコールすることで、多くの情報を収集します。 APIを通じて取得する主要な情報は各種メトリクスです。メトリクスにはCPU使用率、メモリ使用量、ネットワークトラフィックなどをはじめとするシステムやアプリケーションの状態、パフォーマンス、使用状況などに関する数値データがあります。これらのメトリクスは、Google CloudのCloud Monitoringと呼ばれるモニタリングサービスのAPIから取得します。 Pod などの GKE 上のリソースは、CloudMonitoringでメトリクス収集できないため、GKEにDatadog Agentをインストールし、DataDog AgentがPodの状態を収集し、Datadogへメトリクスを送信します。 CloudRunやGKE上のコンテナなどをはじめとする各種ログは、Google Cloudの標準サービスであるCloud Loggingに集められます。CloudLoggingにはログルーターという機能があり、ここでログのフィルタリングと転送ができます。 ログルーターの転送先としてCloud Pub/Sub(Google Cloudのキューイングサービス)を指定し、さらにPub/SubにDatadogのログ転送APIを設定することでDatadogにログが転送されます。 メトリクスやログ収集の詳しい設定方法はDatadogのドキュメント2にわかりやすく説明されています。これに従えば、それほど難しくはないでしょう。
Resource Managerを活用した一括設定
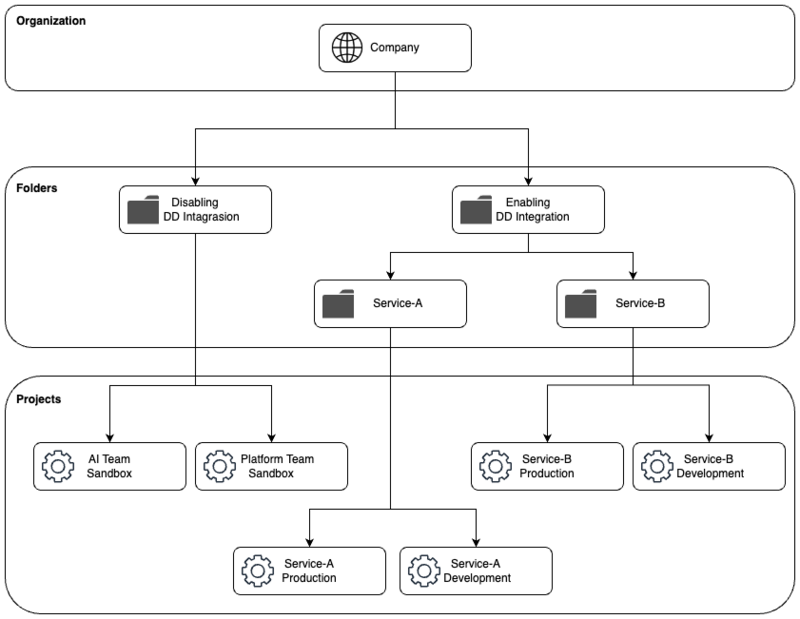
前述のように、DatadogとGoogle Cloudの連携作業はそれほど難しくありません。しかし、冒頭でも紹介したように、Google Cloud上に多くのプロジェクトを抱える組織では、これらの設定がトイルになってしまいます。また、設定漏れや誤りといった作業ミスも発生します。 キャディではこれらの課題を解決するために、Google CloudのResource Managerを活用しています。Resource Manager は、Google Cloudアカウント内のリソースの整理、階層化する機能で、筆者らはアクセスコントロールやコスト管理の向上に役立てています。 Resource Managerでは「組織」と「フォルダ」という単位でプロジェクトを管理できます。「組織」はGoogle Cloudアカウント全体を管理するトップレベルのエンティティです。組織には複数のプロジェクトやフォルダを含められます。 「フォルダ」は組織内でプロジェクトを管理するための階層的なエンティティです。フォルダ配下のプロジェクトに関して、アクセスコントロールポリシーや管理ポリシーを一元的に設定できます。 キャディでは、特定フォルダ配下のプロジェクトを自動検出するしくみを取り入れてDatadog導入の運用負荷を下げています。図3のようなフォルダ構成では、Enabling DD Integrationフォルダで連携設定するようにしており、このフォルダ配下に作成したプロジェクトではメトリクスが収集されるようにしています。一方、Disabling DD Integrationフォルダ配下のプロジェクトは対象外になります。
▼図3 プロジェクトの自動検知を考慮したResource Managerの構成
ログをDatadogで管理する
ログをDatadogに集約することで、分析、視覚化、アラートなどの機能が提供されます。これによって、システムやアプリケーションの監視が可能になり、トラブルシューティングもしやすくなります。キャディではアプリケーションログ、アクセスログ、監査ログなどさまざまなログDatadogに集めており、分析や監視に役立てています。
Datadog logsをメインで利用する理由
Google CloudにはCloud Loggingという機能があり、こちらでもログ管理ができます。しかし、キャディでは次の理由でおもにDatadog logsを利用しています。
- ログ、メトリクス合わせて普段運用で見るべき場所をDatadogだけに統一できる
- Google Cloud上のプロジェクトが増えても横断的にログを調べられる
- 使いやすいエクスプローラによって、高度なフィルタや加工ができる
- ログの属性をインデックスする(ファセット化3)ことにより、条件によってはCloudLoggingより検索が速い
- ログの内容から、HTTPステータスの統計をメトリクスで可視化したり、処理時間に対してアラートの設定ができる
ただ、すべてのログをDatadogで管理しているわけではありません。Datadogでは、ログの保持および、取り込み時・復元時に料金がかかります。このため、利用頻度が高いアプリケーションやアクセスログなどをDatadogで利用し、そのほかのログにはCloud Loggingを利用するといった使い分けをしています。
運用方針
キャディではいくつかの方針を定めてDatadogでログを運用しています。利用するアプリケーションによってログのフォーマットがさまざまであり、そのままDatadogに送るだけでは、トラブルシューティングや監視の有効活用にはなりません。また、コストにも注意をはらう必要があります。
ログの標準属性を決める
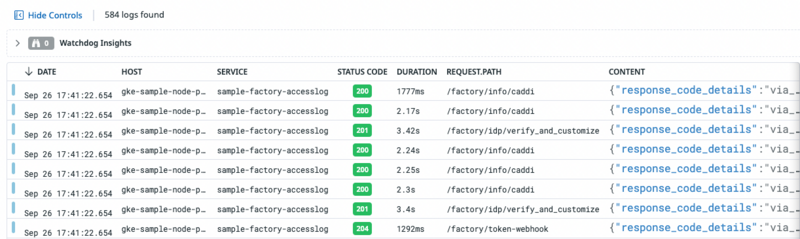
キャディでは、Datadog側でログを解析してもらうために、JSON形式で出力することを推奨しています。解析されたログは、各属性に割り振られ、ログのフィルタリングに利用できます。よく利用する属性(ユーザーIDやリクエストIDなど)を統一させて標準化することで、直感的に検索が行えるようになります。また、ログの一覧画面(図4)で項目の追加や削除ができたり、各項目でのソートができたりして、分析や調査時にとても役立ちます。
▼図4 ログ一覧のイメージ
ただ、アプリケーションの仕様でフォーマット化しづらいケースなどもあります。その場合は、Datadogのパース機能4を使ってDatadog内で構造化できます。
たとえば、リスト2のような非構造化ログがDatadogに送られてくるとします。
▼リスト2 非構造化ログの例
[2023-10-10 02:20:48][PID:158][INFO] method=GET path=/ping status=200 content_type=text/html;
これに対してリスト3のようなパース規則を設定します。
▼リスト3 パース規則の設定
SampleRule \[%{date("yyyy-MM-dd HH:mm:ss"):date}\]\[PID\:%{integer:pid}\]\[%{word:level}\]\s+%{data::keyvalue("=",";\\[\\]/")}
結果、リスト4のようなJSON形式に解釈され、ログインデックスに保存されます。
▼リスト4 ログインデックスに保存されるJSON
{ "date": 1696904448000, "path": "/ping", "method": "GET", "content_type": "text/html;", "level": "INFO", "pid": 158, "status": 200 }
パース規則の定義は、Grokと呼ばれるパターンマッチ構文を使って、ログ解析ルールを作る作業です。正規表現に似た部分もあるので、正規表現を知っていればドキュメントを見ながら規則を書けると思います。 また、DatadogのUI上で実際のログをサンプルとしてパース規則を作成でき、作成したパース規則の動作確認もしやすくなっています。 NGINXやPostgreSQLなど、代表的なアプリケーションのログのパース規則もプリセットで用意されているので、これらを参考にするのも良いでしょう。 なお、推奨レベルではありますが、日時のフォーマットや必須項目(サービス名、リクエストIDなど)を定義しており、ログフォーマットの標準化に努めています。
必要なものだけインデックスする
Datadog logsでは、インデックス5という箱にログを格納することでLog Explorerからの検索が可能になります。どのインデックスにどんなログを入れるかフィルタを書くことができるので、アプリケーション側で選別して送信する必要がありません。Datadog側でフィルタすることで、より柔軟なログの運用ができます。一方で、インデックスするログの量が増えるほどコストがかかるので、なるべく不要なログは除外しておくようにしています。
ログをアーカイブする
Datadogのアーカイブ6は、収集したログを長期保存するためにログをクラウドストレージ(Google Cloud Strageなど)へ転送する機能です。インデックスの保存期間を過ぎてしまったログを再度確認したくなった際に、リハイドレート7使ってクラウドストレージに保存されているアーカイブから復元できます。
ダッシュボードを作成する
Datadogのダッシュボードは、複数のメトリクスやログから得られる情報をウィジェット8と呼ばれるブロックで配置します。グラフ、テーブル、ヒートマップなどさまざまなウィジェットが提供されており、自身のニーズに合わせてカスタマイズできます。 筆者らは次の3つを念頭にダッシュボードを作成しています。
- プロダクトの現在の状態を一目で把握できる
- 異常検知後の原因分析が速やかにできる
- 将来のための傾向分析ができる
また、ダッシュボードを切り替えながら監視や調査をするのは困難なため、1つのプロダクトに1つのダッシュボードを作成することを推奨しています。キャディでは、Grani社の事例9を参考にして表1の3つのレイヤを定義しています。レイヤごとにその役割を解説していきます。
▼表1 キャディで定義しているダッシュボードの3つのレイヤ
| レイヤー | 概要 | 閲覧頻度 | 詳細度 |
|---|---|---|---|
| 1 | Overview | 常時 | 低 |
| 2 | 重要指標の詳細 | 障害時、最適化時 | 中-高 |
| 3 | リソースやアプリケーションの詳細 | 障害時、最適化時 | 中-高 |
Overview
プロダクトが正常に稼働できているかを一目で把握するためのレイヤです。ファーストビューに配置し、Query Valueと呼ばれるウィジェットを使用して現在の値を表示します。また、値に応じて背景色が変わるようになっており、正常時は緑、警告時は黄色、異常時は赤に切り替わります(図5)。
▼図5 Overview正常時のイメージ

また、プロダクト固有のメトリクスも含めると、開発者以外のメンバーも状況が把握しやすくなります。ショッピングサイトを例に固有のメトリクスの詳細を挙げてみます。
- 商品検索の成功率
- ログイン成功率
- 決済の成功率
- 商品レビューの投稿成功率
このような指標は、障害が発生したときに、プロダクトにどのような影響が及んでいるか早期発見ができ、プロダクトマネージャーなどのシステムの詳細を把握していないメンバーとの連携もしやすくなります。このような情報は、基本メトリクスとして用意されていないので、カスタムメトリクス10としてアプリケーション側から送ります。また、ログからメトリクスへの変換もできます。 SLOのウィジェットを利用して、パフォーマンスや信頼性を可視化するのもよいでしょう。
重要指標の詳細
このレイヤには、アプリケーションやビジネスとして重要なメトリクスや、可用性や性能面でボトルネックになりやすいメトリクスをグラフでまとめておきます。重要指標の関連グラフを横断的に参照できるようにしておくことで、特定時刻に何が起こったかを分析しやすくなります。障害が起きたとき、問題の切り分けが迅速にでき、より早く復旧できるようになります。 たとえば、次のようなメトリクスが考えられます(図6は「ユーザーの同時接続数」「アプリケーションエラー数」をダッシュボードにグラフウィジェットで可視化したときのイメージです。
▼図6 アプリケーションのメトリクスイメージ
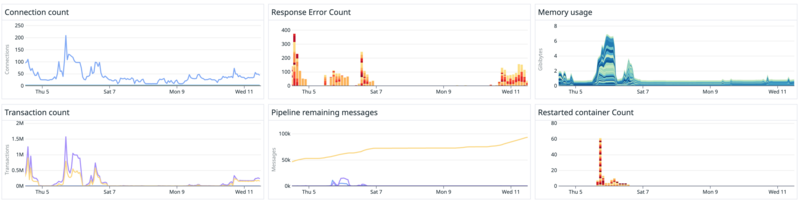
- ユーザーの同時接続数
- トランザクション数
- アプリケーションエラー数
- メッセージキューの状態
- データベース(DB)やWorkloadの負荷
- 仮想マシン(VM)/コンテナの再起動イベント
- DBのコネクション数
- 平均レスポンスタイム
- 定期実行ジョブの成功・失敗
リソースやアプリケーションの詳細
このレイヤには、重要指標ではないがプロダクトに関連するすべてのメトリクス(ApplicationやDBやWorkloadなど)をグラフでまとめておきます。「重要指標の詳細」レイヤで障害の特定ができないときや将来のための傾向・キャパシティ分析のために利用します。
アラート運用
ソフトウェアは複雑で、運用中にはさまざまな問題が発生します。とくにクラウドネイティブなアーキテクチャでは、さまざまな要因で障害が発生します。ログやメトリクスを監視して問題が発生したとき、即座に通知するようアラート設定することで、迅速に対処し、システムのダウンタイムや障害の影響を最小限に抑えられます。 アラートというと、おもにリソース枯渇の検知というイメージが強いかもしれません。しかし、そのほかにもセキュリティやパフォーマンスの観点でアラートを設定すると、プロダクトの信頼性向上につなげられます。Datadogのアラート機能(Monitors)を運用するにあたり、筆者らが注意しているポイントを紹介します。
アラート設定基準
キャディではdevelopment、staging、productionの全環境でアラートを設定しています。本番環境以外でも作成しておくと、アラート自体の動作検証にもなります。通知先はSlackにしており、環境に応じてチャンネルを分けています。 また、4つのレベルでSeverity(重大度)を定義(表2)し、アラートの緊急度が一目でわかるようにしています。
▼表2 キャディが定義する重大度の4つのレベル
| レベル | 重大度 |
|---|---|
| A | なるべくはやく対応する |
| B | 4時間以内に対応する |
| C | 24時間以内に対応する |
| D | 一週間以内に対応する |
Runbookの整備
Runbookとは、トラブルシューティングの手順や関連情報などをまとめた文書のことで、筆者らはそのURLをアラート本文に記載しています(図7)。Runbookはシステムの正常運用を維持するのに必要な情報を提供し、運用担当者が問題を迅速に特定し、解決するのに役立ちます。
▼図7 Slackに通知されるアラートのイメージ
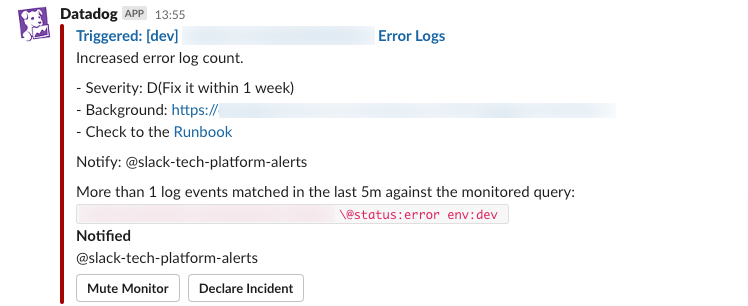
一般的な記載内容は次のとおりです。
- システム概要:システムの構成、アーキテクチャ、技術スタックなどの概要情報
- 運用手順:システムの起動、停止、バックアップ、復元などの基本的な運用手順を詳細に示す
- 対応方法:システムの問題を特定し、解決するための具体的な手法を提供する。エラーコードに対する対処法や調査に使えるコマンドの実行方法が記載されている
- エスカレーション手順:複雑な問題や深刻な障害が発生した場合、適切なサポートまたは管理チームへのエスカレーション手順を示す
- 緊急対応手順:システムに深刻な障害が発生した場合の緊急対応手順を示し、迅速な復旧を目指す
キャディではDevOpsを実践しています。運用専門のチームはおらず、各開発チームがアラート対応をしています。アラート対応は属人的になりがちで、それゆえに一部のメンバーに負荷が偏りがちです。筆者らは日替わりでアラート対応の当番を決め、アラート発生時はRunbookを参照することで対応しやすくなるよう、運用の改善に取り組んでいます。
セキュリティへのアラート活用
キャディでは、一歩進めてセキュリティ観点でもアラートを活用しています。本連載の第2~3回(本誌2023年5~6月号)でも紹介したように、キャディではGoogle CloudのリソースをTerraformで管理しており、IAM Policyもその対象の1つです。IaC化したにもかかわらず、誰かがIAM Policyを手動で変更してしまったり、意図しない変更があった場合、とくに本番環境ではセキュリティインシデントにつながることもあります。これをただちに検知できるようにアラートを設定しています。 IAMの変更はGoogle Cloudの監査ログで確認できます。監査ログをDatadogに流したうえで、リスト5のようなqueryを設定することでアラートを通知できます。 Terraformによる正規の手順でIAM Policyが変更された場合もアラート発報しますが、めったに変更するものではないため、その都度それが意図した変更なのかどうかをアラート担当者が確認する運用としています。
▼リスト5 alert-queryのサンプル
logs("@evt.name:SetIamPolicy project_id:*-production -@usr.id:(*iam.gserviceaccount.com* OR service-agent-manager@system.gserviceaccount.com)").index("*").rollup("count").by("@usr.id").last("5m") > 0
Datadogを導入していない場合、このような検知はGoogle Cloudのプロジェクト単位で実現しなければならないでしょう。Datadogを導入するとログが集約されるので、1つのアラート設定で複数のプロジェクトを監視できます。
まとめ
今回はDatadogを利用したモニタリング基盤の構築や運用について紹介しました。要点は次のとおりです。
- SaaSを使って運用負荷を下げ、リッチなモニタリング環境を利用する
- メトリクスやログを一元化することで、複数のGoogle Projectに対応したダッシュボードやアラートが作成できる
- Runbookを作成し、誰でもトラブルシューティングできるような運用体制を目指す
本稿がみなさんのシステム運用のヒントになれば幸いです。次回はCloudflareを用いたCDNやゼロトラストセキュリティについて紹介します。
- https://www.datadoghq.com/ ↩︎
- https://docs.datadoghq.com/ja/integrations/google_cloud_platform/ ↩︎
- https://docs.datadoghq.com/logs/explorer/facets/ ↩︎
- https://docs.datadoghq.com/ja/logs/log_configuration/parsing/ ↩︎
- https://docs.datadoghq.com/ja/logs/log_configuration/indexes/ ↩︎
- https://docs.datadoghq.com/ja/logs/log_configuration/archives/ ↩︎
- https://docs.datadoghq.com/ja/logs/log_configuration/rehydrating/ ↩︎
- https://docs.datadoghq.com/ja/dashboards/widgets/ ↩︎
- https://engineering.grani.jp/entry/2017/05/29/173141 ↩︎
- https://docs.datadoghq.com/ja/metrics/custom_metrics/ ↩︎