こんにちは、CADDiの図面解析チームで機械学習エンジニアをしている宇佐見です。 このブログでは先日行われたチーム合宿について書かせて頂きます。
はじめに
CADDiは「製造業AIデータプラットフォームCADDi」を提供しています。
私が所属するData&Analysis部(以下、D&A)は文字通り集約されたデータを分析するのがメインの業務です。
Drawerに集まるあらゆるデータを対象とはしていますが、私が所属するチームは図面データ活用クラウドであるCADDi Drawerというプロダクトに集まった図面解析を主な業務としていて、図面の形状解析や記載されている情報の抽出等を機械学習を使って行っています。 自分は8月に入社したばかりではありますが、早速大量の図面データを扱う機会を得て、その奥深さと必要性をひしひしと感じています。
これまでメーカー→AIスタートアップと働いてきて、一貫して画像処理、データ分析等を行ってきましたが、CADDiに来て感じたのは図面データの重要性のみならず、CADDi内に図面に対してのドメイン知識が豊富にある点です。
Drawerに統合されたManufacturing事業にて、図面を書いたり読んだりしていたメンバーがPdMとして活動していて、かなりのドメイン知識がエンジニアにも共有されています。それにより、開発の方向性に自信を持って開発ができていると感じています。
またPdM自体もチームとしてしっかり存在していて、エンジニアが開発に集中できる環境を作ってもらえています。
良し悪しはあると思いますが、これまでは自分が前に立ってお客様と折衝したり、セールス向けに資料を作ったりしていたりという活動に時間を使っている部分はあったので、そういう点では恵まれていると思います。
とはいえ、あまりに受け身だと限られた情報しかもらえないので、気になったことは積極的にPdMとコミュニケーションを取る必要はあります。コミュニケーションに関しては、皆さん気兼ねなく話せて、ちゃんと返してくれる方々ばかりなので、こちらからコミュニケーションを取ることにも心理的障壁を感じたこともありませんでした。
またMLOpsチームが管理、運営している解析基盤もしっかりと作られていて、慣れが必要ではありますが、モデル開発した後にどういうデプロイをすれば良いのかも明確なのはありがたいです。
さて、そんなD&Aはミッションとしては以下のようなものを挙げています。

私は結構このミッションが好きで、「非連続」というCADDiっぽいストレッチした目標を表しつつ、1年後にはその非連続的な変化を日常的に使われる「スタンダード」にするという部分が、高い技術を追いつつもお客様に価値を提供しようというスタートアップらしさをよく表していると思っています。
さて、そんなD&Aが開発したデータ解析技術が使われているCADDi Drawerはありがたいことに使っていただくお客様がどんどん増加しています。それに伴いデータの量や、扱いたいデータの種類が増え、D&Aが行うべき業務も重要性が増していっています。
これを受け、D&Aは新規採用や部署異動も含め、直近で大きく人員が増加しています。また正確にはD&Aではないものの、機械学習を使いうるサービスを開発しているチームや、今後取り入れる技術探索するチームもあったりして、D&Aが関わる人たちはどんどん増えていっています。 人員の増加は喜ばしいことではある一方、今までお互いにコミュニケーションを取ったことが少ないメンバーも増えてきました。私自信、8月入社ということもありまだまだコミュニケーションを取ったことのないメンバーも多いです。
そこで、D&A全体でお互いのことを知り合うための合宿を行うこととなりました。CADDiは10月が期初のため、ちょうど2025年度のスタートとしてもぴったりです。 このブログでは、合宿でどのようなことを行ったかについて紹介します。
全体の流れ
合宿全体としては以下のような流れでした

D&A戦略理解 & チーム説明
集中力があるうちに初めは真面目なプログラムから。
まずはD&A全体の戦略理解です。CADDi全体としては10月期初にKickoffのイベントがあり、そこで25年度のD&Aとしてどういうことをやっていくのかという説明はありましたが、全体向けのため抽象的な部分が多めでした。今回はもう少し細かいところを掘っての共有になりました。
書いてる内容はconfidentialなので詳細は載せられないのが辛いのですが、端的にいえばCADDiはデータでこんなことができるはずで、こんな業界にも価値が届けられるはずだ、というお話です。
自分はまだ入社3ヶ月経ってないくらいなのでまだ事業理解が浅かったためどういうデータを扱えばお客様に価値を届けられるのかが提案しづらいところがあったのですが、
説明を受けて我々が扱いうるデータがどんなものがあり、こんなことで価値が提供できるはずだという未来が想像でき、非常にワクワクしました。
その後、各々のチームリーダーよりチームの説明がありました。 今D&Aは大きくAnalysis, Analysis Platform, Data Managementの3グループに分かれています。 簡単に各チームのやっていることをまとめると、
- データ分析(機械学習モデル作ったり、デプロイしたり)
- 機械学習モデルをデプロイする基盤作り
- データ基盤づくり(プロダクト活用状況ダッシュボード作成、BQ使用の仕組みづくりなど)
です。 ものすごく端的にいえば、機械学習エンジニアはAnalysis、MLOpsエンジニアはAnalysis Platform、データエンジニアはData Managementに所属しています。ただお互いに業務が完全に分断されているわけではなく、協力し合うところは協力してやっています。
マシュマロチャレンジ
次にチーム間の連携を高めるアクティビティとして、マシュマロチャレンジを行いました。
マシュマロチャレンジとは、
- パスタ
- テープ
- 紐
- ハサミ
を使って、頂点にマシュマロが刺さった塔をなるべく高く作るというアクティビティです。 パスタ、テープ、紐は無限に使っていいものではなく、個数、長さに制限があります。

どのチームもなるべく高いタワーを作ろうと苦心していましたが、結局8チーム中3チームしか立てられないという結果でした。
さて、これだけだとただのアクティビティなのですが、このマシュマロチャレンジが選ばれたのは1つ理由があります。
それは、このアクティビティを通じてチームで活動することでいくつかのことを学べるためです。
例えば、
- 考えすぎず、まずはやってみること
- 実際のプロジェクトでも、小さな試行を重ねることが成功の鍵である
- 柔軟な発想で考えること
- 普段の業務も「コスト」「リソース」「時間」などの制約がある中で、どうやって最大限の成果を出すかが問われている
- 役割を分担し協力すること
- PdMとEngineer などの普段の業務でも役職はあるが、オープンなコミュニケーションが重要である
など、実際の業務につながる重要なヒントが隠されていました。
単純にアクティビティとしても面白かったですが、振り返ってみると高さに固執して完成品ができずに最終的に高さが0cmになってしまったり、テープが足りなくなってしまったりなど、自分の取りやすい行動がどのようなものなのかを見つめ直す良い機会だったと思います。
実際、この後のプログラムにも効いてくる部分がありました。
ハッカソン
続いてはメインイベントのハッカソンです。 テーマは明確に決まっていたのではなかったのでチームごとに色々特色があり、CADDi Drawerで扱いうるデータの活用方法であったり、LLMをローカルで複数実行してみる基盤を作ってみたり、はたまた社内Slackでの任意のユーザーのその日のメッセージのまとめを作ってくれるアプリを作ってみたりなど様々でした。
自分のチームはカスタマーサクセスの方がデータ整理をしやすくなるツールを作ることになったのですが、開発過程でたくさんの発見がありました。 まず出来上がりの方向性がずれないよう、各メンバーに絵を描いてもらいました。元々文字だけで持っていたイメージが、皆の間でズレがなかったことを確認できてよかったです。
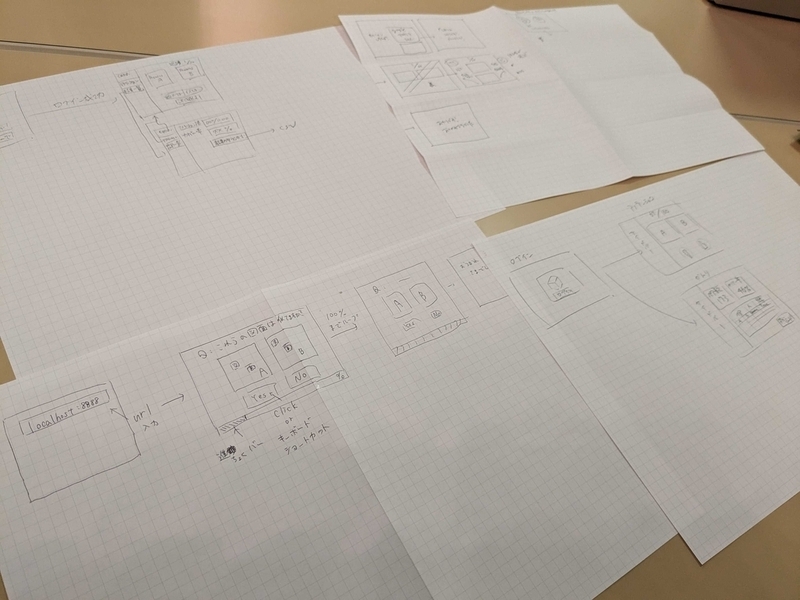
またチームメンバーにマネージャーの役割を持っているメンバーがいたため、その方主導でユーザーストーリーマップを作って開発を進めてみました。

自分はこれをちゃんとやったことがなかったのですが方向性を決める手段として使いやすく、業務にも活かせそうだなと感じました。
また先ほどのマシュマロチャレンジを経て、チームのキーワードとして「マシュマロを立てよう」という言葉が自然発生していました。これにより、必ず動くものを短い単位で作るという意識が生まれ、最後の細かい修正をしている中でも、「最悪この修正が入らなくても動くものがあるからいいか」という安心感の中で開発できていました。
約1日かけて開発を終了し、各チームの発表が完了しました。 内容は前述した通り多岐に渡り非常に面白いものをみなさん開発していました。

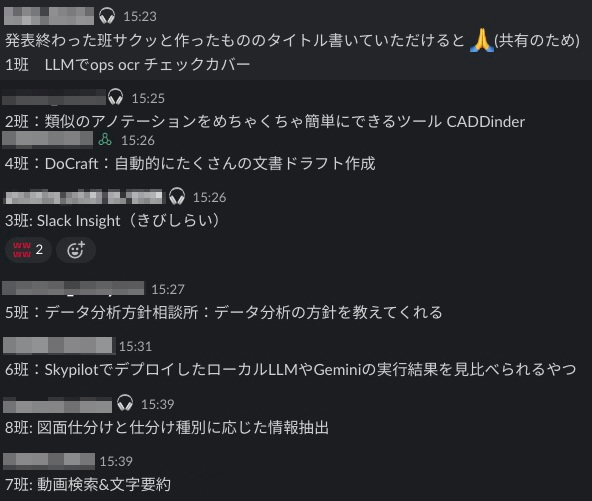
1つ1つ説明すると長くなってしまうので割愛します。
最後に全体の総括がありましたが、そこで2年ほど前に開催されたハッカソンからは大きく変わったことがあったという話がありました。 それは全てのチームが動くものを作成するところにまで到達した、という点です。
そこには2つのポイントがあったようです。 まず、マシュマロチャレンジを行ったこと。上述の通り「マシュマロを立てよう」というワードが自分のチームで発生しましたが、他のチームも同様なようで、動くものを短い単位で作っていこうという意識づけが自然と行われていたようです。
また開発環境的な要因として、LLMの台頭とUIを容易に作成できる方法が充実してきたというのがあります。LLMによって学習なしで機械学習の恩恵を受けることができますし、チームメンバーがほぼPythonを使っているという関係で、StreamlitのようなPythonでUIを作成できるパッケージのおかげで目にみえるアプリケーションとして完成させることが容易になっています。実は自分のチームには技術リサーチがメインで、プログラミング未経験のメンバーが一人いたのですが、そのメンバーも1日のうちにStreamlitを使ったコンポーネントを開発できるようになっていて、その威力を強く感じました。
決して2年前のチームが今のチームと比べて技術的に劣っていたわけではありませんが、環境要因によりアウトプットが大きく変わるということを実感できました。
最後に
多くのアクティビティを通し、今まで喋ったことのないメンバーと喋ってお互いの理解が深まったと思います。業務上においても、コミュケーションを取ることがよりスムーズに行けるようになったと思います。また、実際の業務にも役立つような体験もあり、非常に実のある合宿でした。
実際アンケートをとると5段階評価で4以上の評価がほとんどを占めるという結果となり、参加者皆の体験も良好だったようです。

さてこの合宿は総勢28名のメンバーが参加するほど、チームは大きくなってきています。しかし、それでもプロダクトの成長を考えるとまだまだメンバーが足りません。D&Aに所属するMLエンジニア、MLOpsエンジニア、データエンジニアはもちろん、その他エンジニアやデザイナーなど、様々な職種で採用を超強化中です!
「はじめに」、でも書いた通りCADDiにはインターネット上に存在しない図面というデータをお客様から預かっており、世の中に解決策が転がっていないような課題がたくさんあります。それを素早く、価値のあるものとして届けるというのは非常に面白いです。
少しでも興味を持っていただけましたら、↓の採用ページをご覧ください。ご応募もカジュアル面談も、お待ちしております!
ML Engineer
Machine Learning Engineer / キャディ株式会社
MLOps Engineer
MLOps Engineer / キャディ株式会社
Data Engineer
Data Engineer / キャディ株式会社