こんにちは、Data&Analysis部(D&A)です。
D&Aでは週1回、機械学習の勉強会を開催しており、本記事は、勉強会の内容を生成AIを活用して記事にまとめたものです。
※勉強会内容公開の経緯はこちら
※過去の勉強会は「社内勉強会」タグからもご覧いただけます。
はじめに:我々が直面していた課題
現在、我々はドキュメントを解析するプロジェクトを推進しています。その中で以下のような壁に直面しました。
- フォーマットの多様性
- PDF、Word、PPT、スキャン画像など、形式がバラバラなドキュメントの前処理が大変
- 構造情報の損失
- テキスト抽出時にレイアウト、表、図が崩れて意味が失われてしまう
- 既存ツールの限界
- 商用ツールは高価かつクラウド必須の制約があったり、OSSでは品質・機能不安があったり
それらを解決するため、Doclingが効果がありそうだと分かり、その性能検証を進めることにしました。
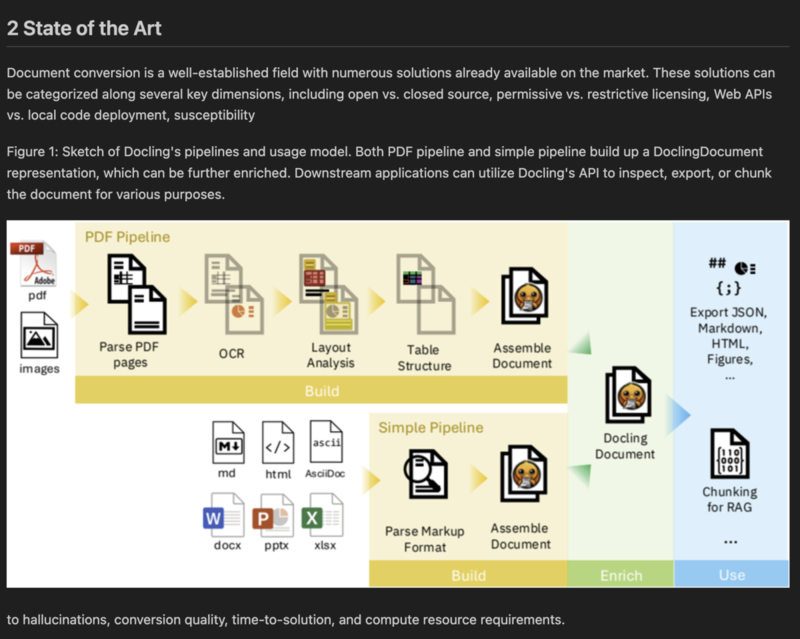
DoclingはIBMによって開発されたOSSのドキュメント変換ツールキットです。次の章でDoclingについて説明していきます。
ちなみに、この記事は以下の論文とテクニカルレポートを参考にした内容になります。
- [2408.09869] Docling Technical Report
- [2501.17887] Docling: An Efficient Open-Source Toolkit for AI-driven Document Conversion (AAAI,2025)
Doclingの主要なコンセプトと特徴
Doclingは以下の4つのキーワードでその強みを説明できます。
- 高性能AIモデル搭載
- DocLayNetベースのレイアウト分析モデルを内蔵し、ページ内のタイトル、本文、表、図などを検出します。RT-DETRベースの高速オブジェクト検出器で、文書レイアウトに特化したDocLayNetで学習済み。
- TableFormer(表構造認識)を内蔵し、表の画像からセルの結合や階層ヘッダーを含む複雑な構造を正確に読み取ります。Vision Transformerベースで、罫線がない表や複雑なレイアウトの表も言語に依存せず高速に解析可能。
- OCR(文字認識)はEasyOCR(デフォルト)とTesseractをサポートしています。
- 完全ローカル実行
- クラウドにデータを送ることなく、手元のマシンやオンプレミス環境で完結するため、機密性の高い文書も安心して扱えます。
- 豊富な対応フォーマット
- PDF、画像、Word、PowerPoint、Excel、HTMLなど、ビジネスで使われる主要なドキュメント形式を幅広くサポートしています。
- 開発者に優しい
- MITライセンスで商用利用も可能であり、Pythonライブラリとして提供されるため、LangChainやLlamaIndexなどの主要なフレームワークと簡単に連携可能です。
DoclingDocument データモデル
DoclingDocumentは、Doclingの中核となるデータモデルであり、様々なフォーマットの情報を1つの型で表現することで、後段の処理での扱いやすさを追求しています。
- 多様な要素
- テキスト、表、リスト、画像、キャプションなどを個別の要素として認識します。
- 階層構造
- セクションやヘッダー/フッターといった階層構造を保持します。
- 豊富なメタデータ
- 各要素がページのどこにあるか(座標情報)や、どのページ由来か(出所情報)といったメタデータを持ちます。
- 柔軟な操作
- ドキュメントの構築、検査、そしてRAGに最適な「チャンク」への分割も容易です。
内蔵AIモデルの詳細
Doclingに内蔵されているAIモデルは以下の通りです。
- レイアウト分析モデル (DocLayNetベース)
- ページ内のどこが「タイトル」「本文」「表」「図」なのかを検出する。
- RT-DETRベースの高速オブジェクト検出器。文書レイアウトに特化したデータセットDocLayNetで学習済み。
- TableFormer (表構造認識)
- 表の画像から、セルの結合や階層ヘッダーを含む複雑な構造を正確に読み取る。
- Vision Transformerベース。罫線がない表や複雑なレイアウトの表も、言語に依存せず高速に解析可能。
- OCR (文字認識)
- スキャンされた画像からテキストを抽出する。
- EasyOCR(デフォルト)とTesseractをサポート。
これらのレイアウト分析と表構造認識モデルは、事前学習済みの重み(Hugging Faceでホスト)と、推論コード用のPythonパッケージ(doclingibm-models)が提供されています。
パフォーマンス比較
テクニカルレポート内で行われていた、幾つかのOSSとの比較実験を紹介します。
比較対象は、unstructured.io (Unstructured.io Team 2024)、Marker (Paruchuri 2024)、MinerU (Wang et al. 2024)です。
実験内容
- データセット:
- 多様なスタイル、機能、コンテンツ、長さをカバーする89個のPDFファイル(4008ページ、56246個のテキスト項目、1842個の表、4676枚の画像を含む)からなるテストセットを使用。それぞれのデータで項目の抽出にかかった時間を比較。
- システム構成
- AWS EC2 VM (g6.xlarge, Nvidia L4 GPU搭載)とMacBook Pro M3 Max (ARM) で比較。
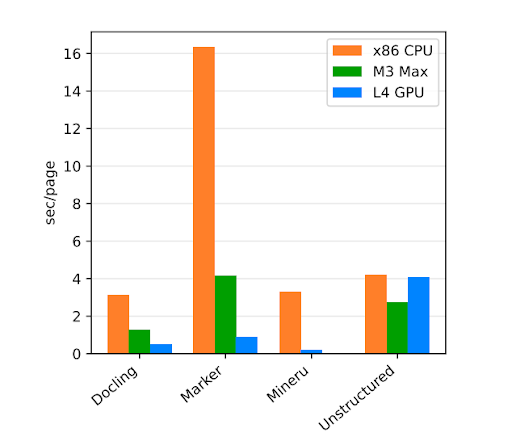
まずDoclingで実行環境の違いによる抽出速度の差を確認してみましょう。
ほとんどのタスクにおいてはGPU搭載の環境での速度が最速でした。
ただし、pdfのパースにおいてはあまりGPUの恩恵は受けられないようです。

続いて、各OSSとの比較です。
結論として、GPU環境ではMinerUが最速ですが、Doclingはどのようなマシンでも満遍なく速いという特徴が見られました。unstructuredに関してはあまりGPUの恩恵を受けられないようです。
苦手な点・今後の課題
- 縦書き文字の表示が崩れる可能性があります。
追加実験
実際に手元でdoclingを利用してドキュメントを変換してみます。
uvでdoclingをインストールすれば、下記のようにdoclingを実行できます。
uv run docling target_data
まず、doclingの論文を変換してみましょう。web上のデータも対象にできます。
uv run docling https://arxiv.org/pdf/2501.17887
変換結果の一部分は以下の通りです。
テキストはmarkdown構造で出力され、画像はbase64変換されており、vscodeのプレビュー機能で綺麗に表示できます。
表構造も表としてmarkdown内で表現されています。

別の例として、日本語の文章も変換してみましょう。
例として、こちらの令和6年度 年次経済財政報告を変換してみます。
uv run docling https://www5.cao.go.jp/keizai3/2024/0802wp-keizai/setsumei00.pdf
こちらは元々pdf形式のスライドなのですが、以下の通り画像も出力できていて、表構造や文書の構造も守って変換できているように見えます。

しかし、以下のような縦書きのラベルに関してはうまく出力できていません。一番右の「製品・サービスの品質低下を招く」というラベルは、「製品・サ」で途中までしか出力されていません。また、その他のラベルは全く出力されていません。

まとめ
Doclingは、非構造化データのAI活用におけるドキュメント変換の課題を解決する、高性能で柔軟なオープンソースツールキットです。
特にRAGシステム構築において、その構造理解能力とローカル実行の安全性は大きなメリットとなることがわかりました。
しかし縦書きの文字はうまく出力できないという課題もあり、日本語の文書に適用するには工夫が必要です。