キャディでエンジニア採用を担当しています片渕です。
今回は2022年2月25日に開催したイベント『【ABEJA × CADDi】Computer Visionのビジネス活用を考える 』に登壇のエンジニア(竹原・中村)からのプレゼン内容をまとめたものを紹介していきます。

図面画像に対する母材形状認識タスク
竹原:
今回の発表では、母材形状認識に対しCNNを適応した内容について話します。
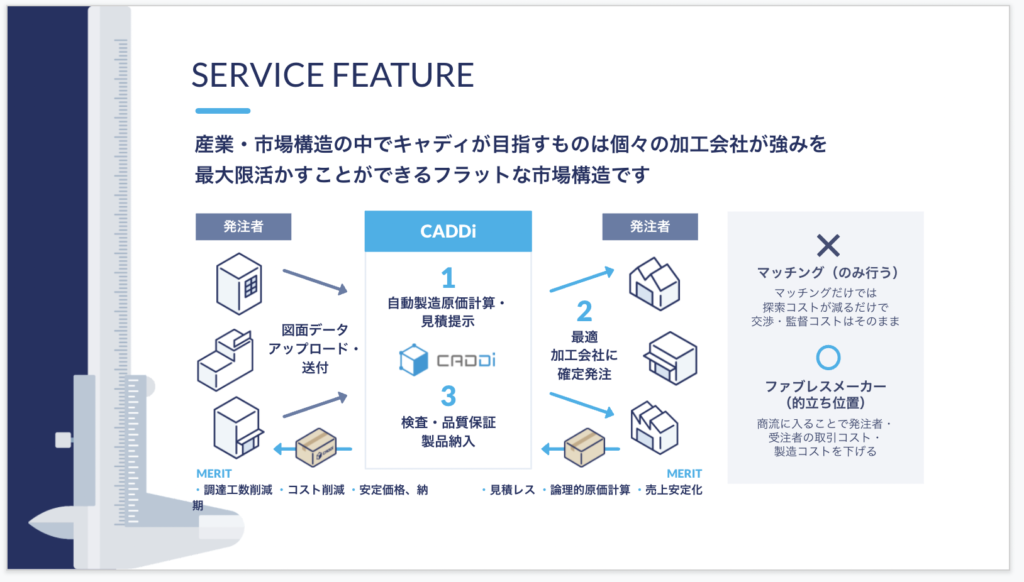
キャディのビジネスでは、発注者から図面データを預かって製品を発注します。その図面データを活用するために図面から様々な情報を抽出するニーズがあります。
母材形状とは、製造における加工前の形状のことで、完成品から逆算して選択されるものです。
例えば、丸棒に対して、旋盤加工をして完成品ができるという流れです。今回紹介する認識タスクでは板金加工と機械加工を含む10種類の母材が対象になります。

今回紹介する認識タスクは、図面からどのような母材が利用されるかを10クラスに分類する問題です。
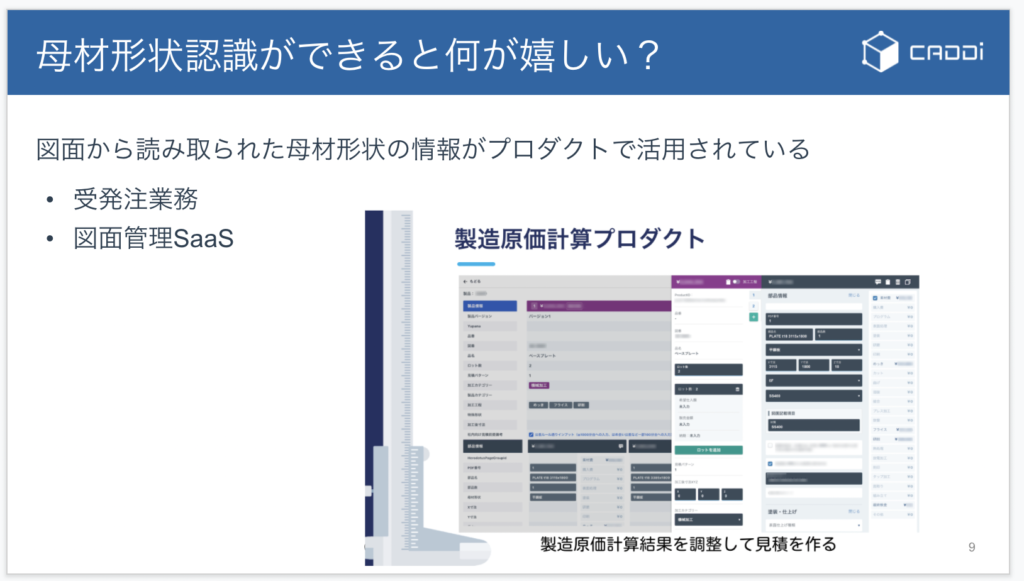
母材形状認識のシステムは、社内の原価計算プロダクトや現在開発中の図面管理SaaSで活用されています。
CNNモデリングにおける工夫
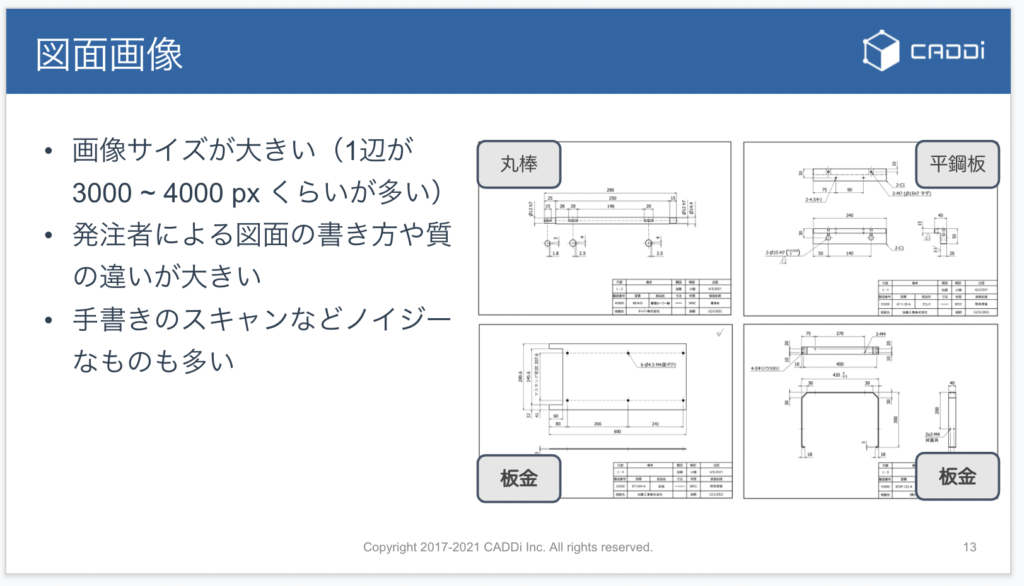
母材形状認識に対して、CNNを適応しました。図面画像はサイズが大きく、CNNに入力する前にリサイズするのですが、やりすぎると細い線で表現されている情報が失われるので注意が必要でした。
また、図面は発注者により書き方や質が大きく異なっていることがあり、こういった点が母材形状認識する上での難しさになります。
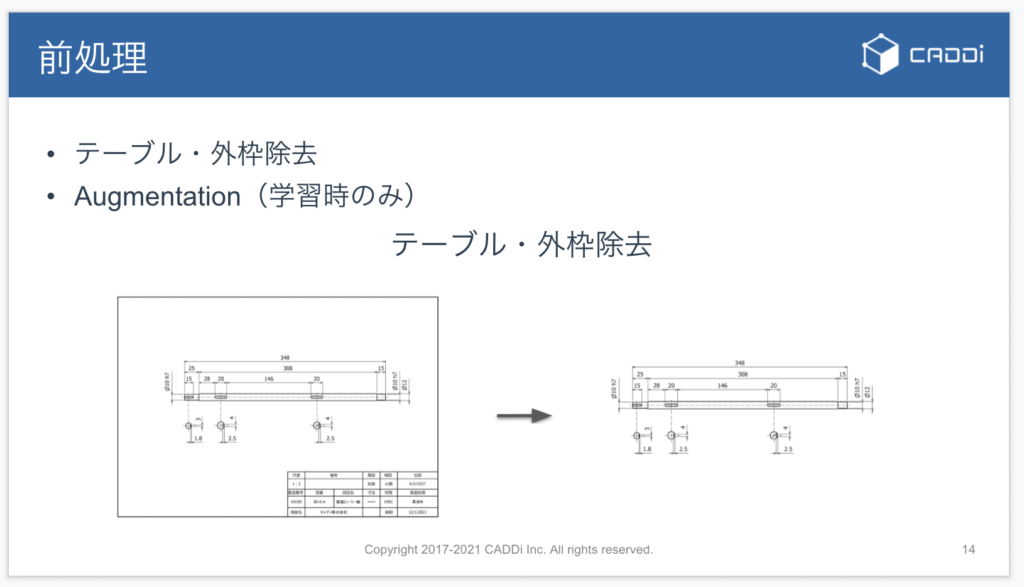
モデルに入力する画像への前処理としては、テーブル(主に図面の右下にある表部分)および外枠を除去しています。また、簡単なAugumentationも適用しています。
データセットとしては、キャディの受発注業務を通して蓄積された正解データを利用しています。

モデルの学習についてですが、入力画像サイズは1024×1024、前処理はテーブル・外枠除去とAugumentation、モデルはEfficientNet、損失関数はCross Entropyで、Label smoothingを用いた学習を行なっています。
結果

認識精度を確認するための検証データは、母材形状ごとにバランスよく用意したデータセットや、顧客ごとに作成した実世界に近いデータセットをそれぞれ作成しました。
厳密な精度はお話できませんが、10クラス分類で正解率で85%~くらいでした。
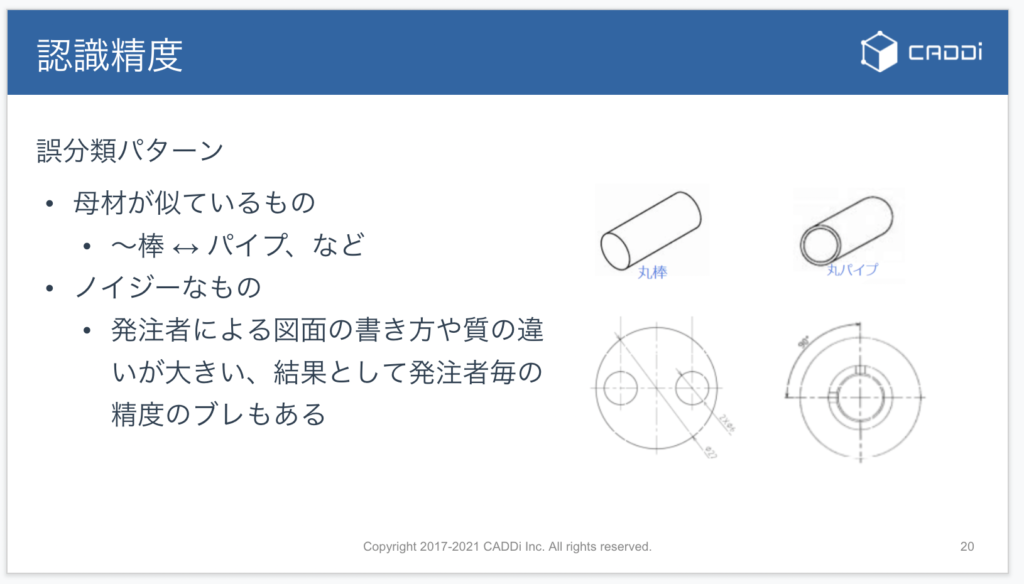
誤分類のパターンとしてはやはり母材自体が似ているものは間違えやすいことが確認できています。例えば、丸棒と丸パイプのような、形が同じだが中に空洞があるかないかのような違いです。
また、図面がノイジーなもの、発注者側によって書き方が特殊な場合にも間違いが多いことが確認できました。

例えば、六角棒の母材形状分類は通常簡単な部類ですが、ノイズが多い場合丸パイプに間違えるものなどがありました。
ノイズを取り除く話については、この後に登壇する中村さんの話で詳しくさせていただきます。
図面画像に対するデノイジング技術
中村:
キャディでは、Computer Visionによる図面解析を行っています。
例えば、図面に書かれている寸法線や、加工指示に関する記号、表に書かれているテキストなど、様々な情報を画像解析によって取得しています。
図面解析に対するノイズの影響
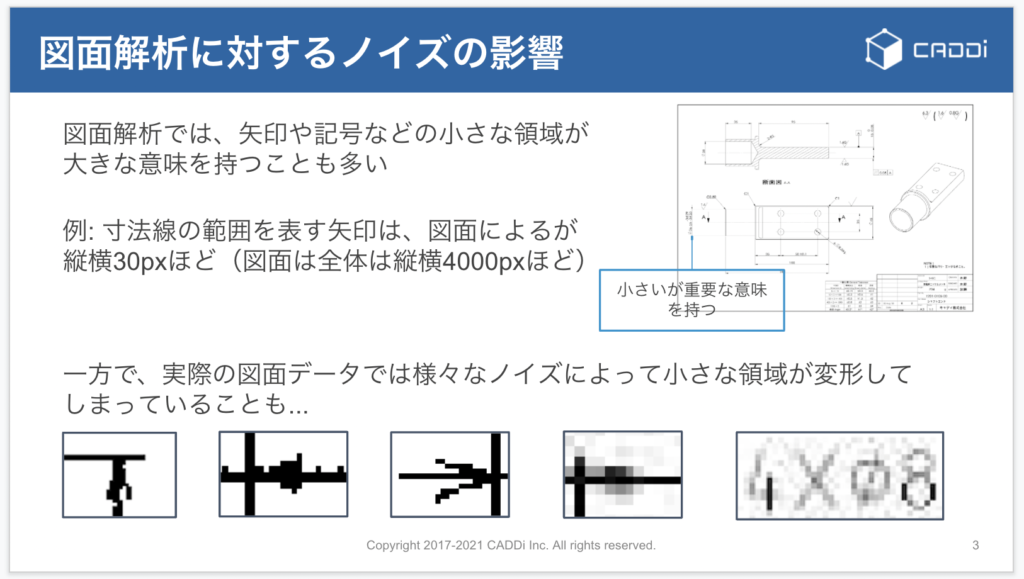
図面解析では、矢印や記号などの小さな領域が、大きな意味を持つことがあります。 例えば、寸法線の中には両端に小さな矢印がついているものがあり、解析のヒントになり得ます。 しかし、矢印自体の大きさは、図面全体が数千pxあるのに対して数〜数十pxほどしかなく、さらに図面に様々なノイズが乗っている事もあり、劣化・変形してしまうことが多々あります。
そのため、図面解析においてはノイズ除去の技術が必要です。
一口にノイズといっても、図面には様々な種類のノイズが乗ることがあり、代表的なものとしてヒゲノイズ・モスキートノイズ・カスレの3つがあります。
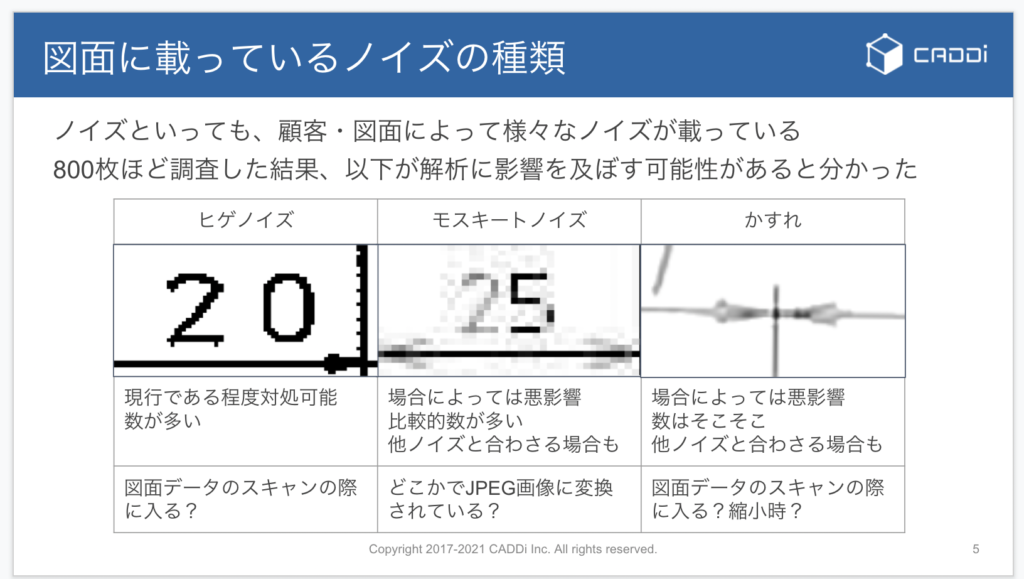
ヒゲノイズは線がギザギザになってしまうもので、こちらは現行の図面認識アルゴリズムの中で対処できるものです。一方でモスキートノイズやカスレは、複合的なアルゴリズムでも対処が難しく実際に認識の妨げになることがあります。
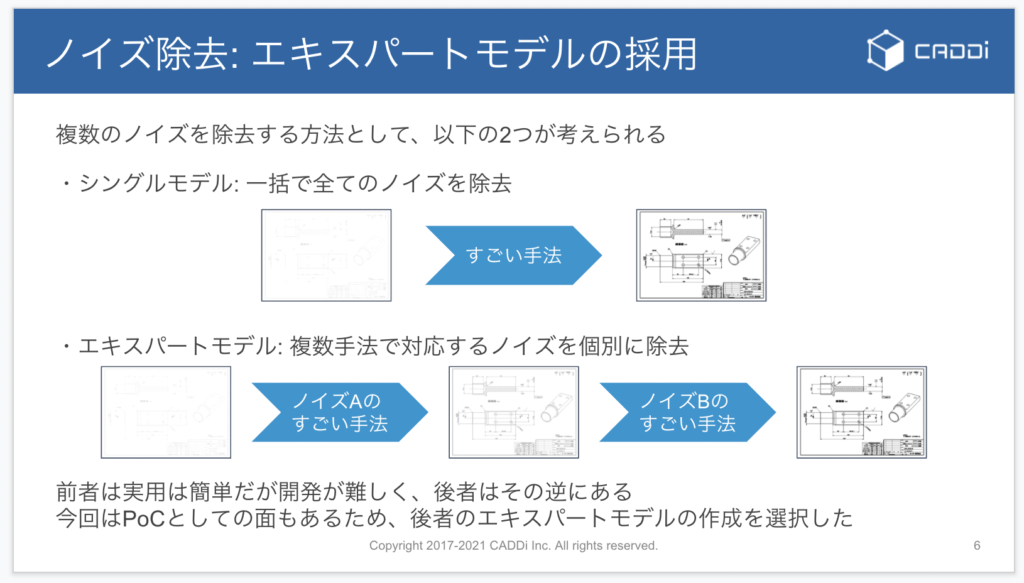
ノイズ除去のアイデアとしては2つあります。 シングルモデルとして一括で全てのノイズを除去する方法と、複数手法を扱うエキスパートモデルで対応するノイズを個別に除去していく方法です。
前者は運用が簡単なのですが開発が難しく、後者はその逆になります。 今回はPoCとしての側面もあるので、後者のエキスパートモデルの作成に挑戦しました。
ノイズ除去モデルの開発

具体的なエキスパートモデルとして、モスキートノイズとカスレの除去モデルの2つを作成しました。これらは先に述べた代表的なノイズ・劣化に当たります。
ノイズ除去のアルゴリズムはたくさんあるのですが、図面ごとに異なる傾向を簡単に取り扱える点と、ある程度パラメータフリーであるという点で、畳み込みニューラルネットワーク(CNN)によるノイズ除去を採用しました。
モデル構造にはU-Netベースの構造を用いました。選定理由としては、実装が簡単であること、構造として高解像度画像を扱いやすいこと、これまでの実績や知見が数多くあることが挙げられます。
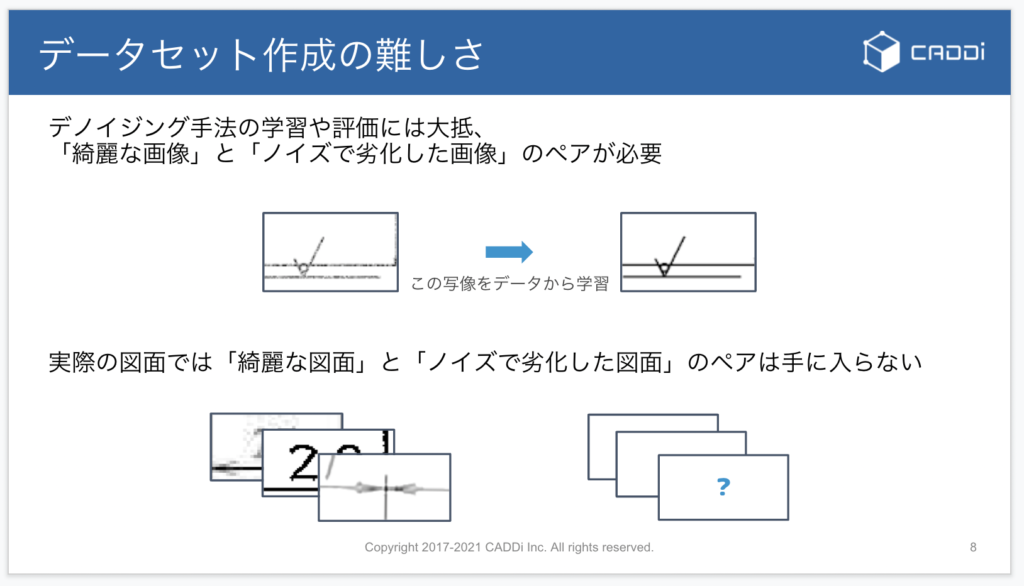
CNNによる学習ベースのノイズ除去では、大抵の場合綺麗な画像とノイズで劣化した画像のペアが大量に必要になります。
しかし、実際の図面では綺麗な画像とノイズの乗った画像のペアを入手することは非常に難しいという問題があります。
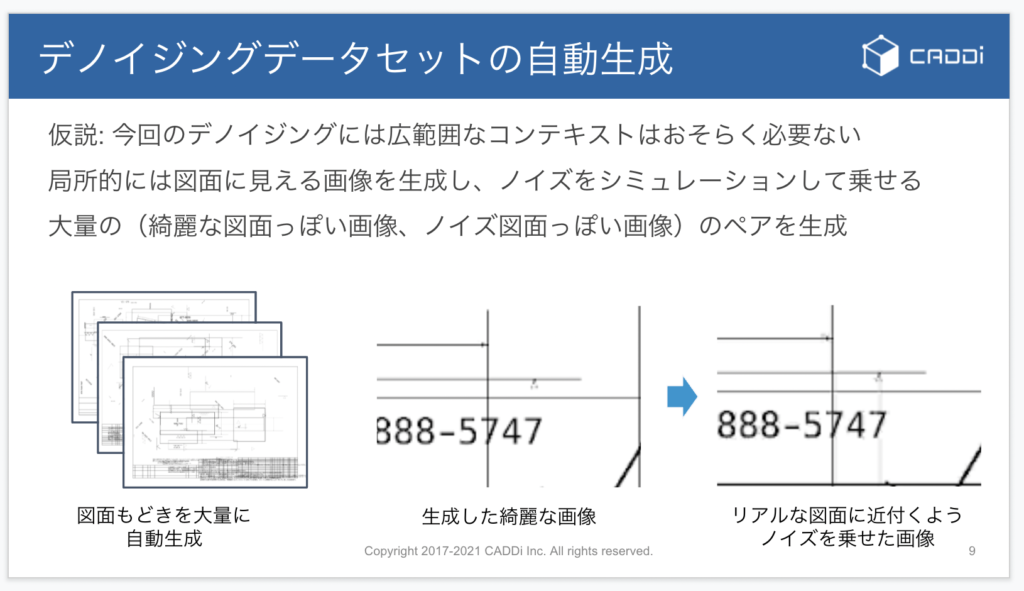
今回はその難しさを、「図面のように見える画像を大量に生成し、ノイズをシミュレーションして乗せる」という方法で解決しています。今回モデリングでは、ノイズ除去に図面の広範囲の情報は必要ないだろうという仮説を立て、画像から小領域を切り抜いて入力しています。そのため、局所的に図面のように見える画像であれば、実際の図面でなくても良いだろうという仮説に基づいています。
結果の可視化と分析
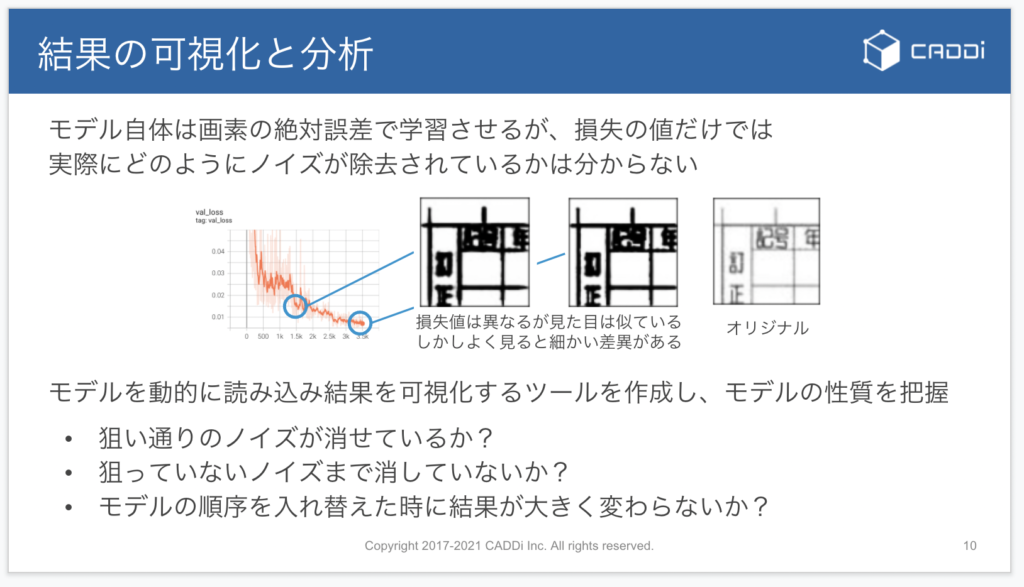
学習は、モデルの出力する綺麗な画像と、実際の綺麗な画像との画素値の絶対誤差で学習させます。
誤差が下がっていけば学習できたと言えるのですが、注意すべきこととして誤差の値と、実際に生成された画像のクオリティが、感覚として結び付きづらいということが挙げられます。
例えば、学習の中盤のモデルと、終盤のモデルを比べると、誤差の値としては大きく差がありますが、実際に出力されたノイズ除去画像は人の目ではほとんど差がわかりません。故に、誤差の値だけでモデルの精度を正確に評価するのは難しいと考え、定性的な評価も行うことにしました。
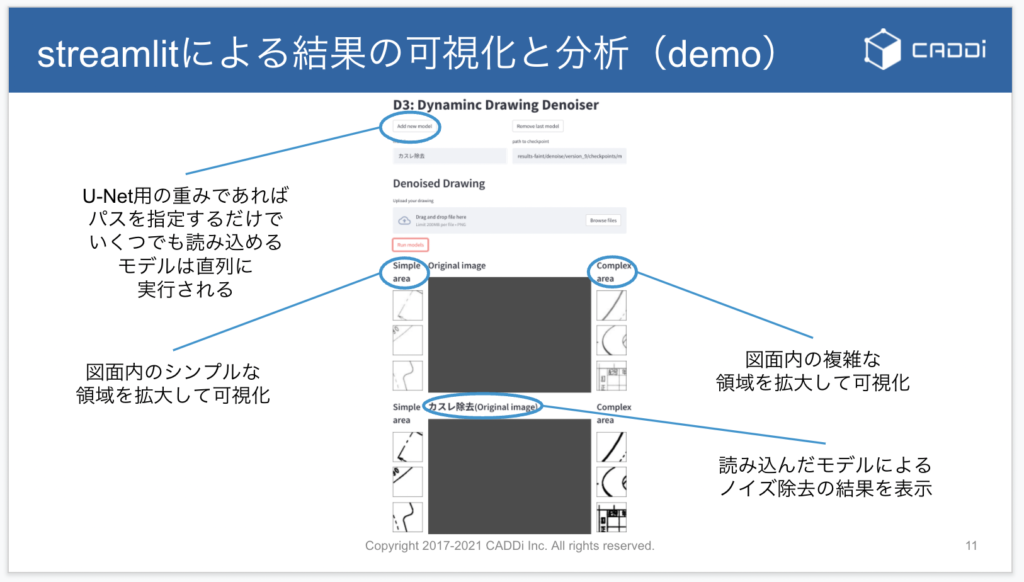
モデルの傾向を簡単に把握できるようにするため、Web UI上で、学習したモデルを動的に読み込んで、指定した画像のノイズ除去後の結果を可視化するツールを作成しました。このツールでは
- 狙い通りのノイズが消せているか
- エキスパートモデルが除去対象としていないノイズや、図面に載っている正しい情報まで消していないか
- モデル同士が独立していて、適用順序を変えても最終的に得られる綺麗な画像は変わらないか
という点を簡単に可視化できるようにしています。
(当日イベント内ではdemoを公開しました)
今回行ったノイズ除去の最終的な目的は、後段の図面解析がうまく進む点にあるので、その観点でも定量評価を実施しました。
まず、評価用の図面データセットとして、図面をランダムに集めたデータセット、そしてノイズが乗った図面のデータセットを作成し、それらに対してノイズを除去した前後での記号認識精度を比較しました。

結果としては、ランダムに集めた図面データセットでの記号認識精度はあまり変わりませんでしたが、ノイズが多く乗ったデータセットでは認識精度が向上しました。

今回はノイズの種類を分析し、エキスパートモデルをCNNで作り、定量的・定性的な観点から評価しました。実際にノイズの乗った図面での記号認識の精度向上を確認できました。
最後に
今回イベントに登壇させていただきました竹原・中村含め、カジュアルにキャディのエンジニアからもっと話を聞いてみたい!という方は、こちらより申し込んでいただけますと幸いです。
また、イベントに関する情報は、キャディのconnpassがありますので、こちらも登録いただけると嬉しいです。

最後までお読みいただきまして、ありがとうございます。