はじめに
こんにちは、Analysisチームの宇佐見です。
こちらはCADDi プロダクトチーム Advent Calendar 2024 6日目の記事になります。
皆さん、機械学習モデルの精度を追ってますか?PoCの話ではなく、デプロイした後の話です。
CADDiが展開するCADDi Drawerの一機能の図面解析も機械学習を用いて行われており、デプロイしたモデルの精度が期待していたよりも低ければ図面から適切な情報を得られない可能性があります。なのでどうにかしてデプロイ後のモデルの精度は監視したいものです。
とはいえ直接的な精度評価は難しいです。従って、例えば間接的に特徴量の推移を追うことで精度変化が起きている可能性を考えると思います。
データドリフトのように特徴量の分布が変わってしまったり、コンセプトドリフトのように全く異なるコンテキストのデータに適用してしまったりすると精度低下は容易に起こりえます。
CADDiが扱う領域である図面で考えれば、例えば学習画像に含まれていないような書き方の図面だったり、はたまた全く扱っていない業界の図面だったりを推論すると精度低下は発生し得ます。
ただ、ここで精度が低下したと本当にわかるのは人間が確認した時であるというところが問題になります。
つまり定期的に推論にかけられたデータを確認し、アノテーションをして初めて本当に精度低下が起きているかが確定するわけです。
また、図面の特徴量の分布ってどうやって測るの?というところも難しいです。
定期的にバナーでポップアップを出してユーザーに体験を聞くことでフィードバックを得ることで、ユーザー体験を測ることもできますが、直接的な精度計算はできません。この場合フィードバックが悪くなってから気づくことになるので、後手に回る感も否めません。
つまり、理想的には
ユーザーが悪い印象を得るよりも早いタイミングでアノテーション作業なしに精度を測りたい
ということになります。

究極的にはこんな感じで推論に使われた画像に自動的にアノテーションができていれば、デプロイされたモデルの推論結果の評価ができるなあというのをずっと昔から考えていました。
この「めっちゃすごい何か」を埋めてくれるピースとしてついにLLMが来たのではと思い、最近話題のLLM-as-a-judgeの考え方を取り入れてこれを実現できないか?ということを実験してみた、というのがこの記事の主旨になります。
LLM-as-a-judge
昨今注目を集めるLLMですが、実用するとなれば他の機械学習モデルと同様性能評価は必須です。
LLMを評価する方法はいくつか挙げられますが、いずれの方法にしても人間が関わってきて、どうしてもコストや時間がかかります。
そういった課題を解決するために、LLM-as-a-judgeという方法が注目されています。
これは文字通りあるLLMの性能を評価するためにLLMを使うという方法です。
評価したいLLMに対して評価用のLLMを用意し(Claude, ChatGPTなどの汎用LLMや、ファインチューニングされたLLMなど)、特定のスコア(1~10の離散値、Yes/No、2つの選択肢を比較するペアワイズ比較など)を返すようなプロンプトを用意します。後処理でそのスコアをうまく抽出します(正解している割合など)。
評価用のLLMから返されたスコアが十分高ければ被評価LLMの性能は良い、と言えるわけです。
ものすごくざっくりした説明ですが、本記事はその詳細よりも実際に試したいことに注力して書いていきたいと思います。
上記の前提に則って考えると、図面解析で使っているモデルが返却する値を評価用LLMに評価してもらうことでLLM-as-a-judgeを適用できそうです。
CADDiでは図面解析にはいくつかのモデルを使っていますが、ここでは最大寸法推定というタスクを例に考えてみたいと思います。
対象のタスク
先述の最大寸法推定とはどのようなタスクかというと、文字通り図面内に存在する寸法のうち、最大値を推定するというタスクになります。
なぜ最大の寸法を知りたいのかというと、製品の最大寸法がわかることにより、大方使う材料の量が決まってきて、製造のコストに大きく影響するからです。例えば、新しく作った図面の最大寸法がわかり、それと同じような形状の図面かつ最大寸法が同じような図面が過去にあったとします。そうすると、その図面が持つ当時の見積もり額を確認すれば、新しくつくった図面の妥当な見積額がわかるわけです。
実験概要
タスクがわかったところで、どのような実験をするか説明します。
現在、CADDiでは最大寸法を推定する機械学習モデル(以下、最大寸法推定モデル)を運用しています。それ自体は図面を与えると、最大寸法らしき値を抽出するというモデルになります。
とすると、以下のような評価方法が考えられます。
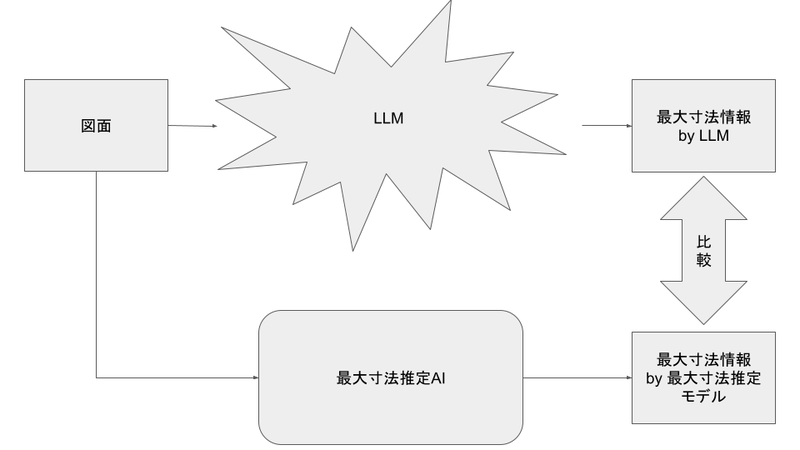
素晴らしい。先ほどのピースが埋まりました。
もちろんLLMが最大寸法をある程度精度高く推定できるという前提がありますが、過去の実験からGPT-4oを使えばある程度高い精度で抽出できることがわかっているので、評価用のLLMとして十分実用に耐えそうです。
ところで、そこまで精度がいいのならばLLMを実運用して使えば良いのでは?という疑問があるかと思いますが、これはレスポンスタイムとコストの面から不採用となった経緯があります。
現行の最大寸法推定モデルと比べ、GPT-4oでは1リクエストあたりのコストが数十倍になることがわかっており、そのコストは飲めませんでした。また、1リクエストあたりのレスポンスタイムがかかりすぎて、SLOを満たすことができませんでした。
しかし評価用としていくつかのサンプルに実行してやるとなれば、コストを抑えつつLLMの恩恵を享受できそうです。
実際には人がアノテーションする金銭的なコストと比較する必要はあると思いますが、少なくとも結果を得られるまでの速度の面では圧倒的に早くなるでしょう。
実験のプロセス
それでは実際に実験をやってみます。
本実験では、CADDiがGoogle Cloudを使っているため、Gemini 1.5 Proを使って実験します。
対象の図面は、CADDiが持っているサンプル図面を使ってみます。

ここで図面上の最大寸法は、図の中央下部にある214になります。
では、Gemini 1.5 Proにこの図面をリクエストした場合、どのような結果になるかを見ていきます。
プロンプトは以下のようにしてみました。
Extract the maximum dimension of the image.
とすると、レスポンスは以下の通りでした。
{'max_dimension': 214.0}
正解できているようです。
こうやって得られた結果と、元々の最大寸法推定モデルの回答とを同時に比べていけば、常に精度の監視ができそうです。
次の章でもう少し、実運用の方法について考えていきたいと思います。
Generative AI on Vertex AIでの実装
Gemini 1.5 Proへのリクエストの送信ももちろん、LLM-as-a-judgeの評価も、Vertex AIを使って行うことができます。 以降のコードは、Google Cloudが公開しているNotebookを参考に進めていきます。
さて、シンプルにGemini 1.5 Proにリクエストを送る方法は以下の通りです。
vertexai.init(project=PROJECT_ID, location=LOCATION)
model = GenerativeModel(
"gemini-1.5-pro",
generation_config=GenerationConfig(
response_mime_type="application/json",
response_schema=response_schema,
)
)
question = 'Extract the maximum dimension of the image.'
image="gs://path/to/image.png"
image_file = Part.from_uri(image, "image/png")
prompt = [
"QUESTION: ",
question,
"IMAGE: ",
image_file,
]
response = model.generate_content(prompt)
上記のPROJECD_ID, LOCATION, imageのパスは適宜変更してください。 responseの一部に先述のmax_dimensionが含まれており、それを抽出すれば最大寸法がわかります。
これを踏まえ、最大寸法推定モデルの推論結果を評価する関数を用意してみます。
def get_autorater_response(metric_prompt: list) -> dict: metric_response_schema = { "type": "OBJECT", "properties": { "score": {"type": "NUMBER"}, "max_dimension": {"type": "NUMBER"}, "explanation": {"type": "STRING"}, }, "required": ["score", "max_dimension", "explanation"], } autorater = GenerativeModel( "gemini-1.5-pro", generation_config=GenerationConfig( response_mime_type="application/json", response_schema=metric_response_schema, ) ) response = autorater.generate_content(metric_prompt) response_json = {} if response.candidates and len(response.candidates) > 0: candidate = response.candidates[0] if ( candidate.content and candidate.content.parts and len(candidate.content.parts) > 0 ): part = candidate.content.parts[0] if part.text: response_json = json.loads(part.text) return response_json
この関数では、Geminiのレスポンスにscore, max_dimension, explanationを必ずキーとして持つように設定しています。
そして、関数に与えられたmetric_promptをGeminiに与えます。
metric_promptは以下のように作成します。
question = 'Extract the maximum dimension of the image.' context = [ { "question": question, "image": "gs:path/to/image", }, ] eval_instruction_template = """ # Instruction You are a specialist of reading manufacture drawings. You will be provided with a question and an image of a manufacture drawing. Your task is to extract the maximum dimension of the image. Please leave why you think the maximum dimension is the correct answer in the explanation section. """ # read image from uri image_file = Part.from_uri(image, "image/png") evaluation_prompt = [ eval_instruction_template, "QUESTION: ", question, "IMAGE: ", image_file, ] evaluation_response = get_autorater_response(evaluation_prompt)
ここで、Instructionとして情報を与えています。後段の評価のステップで評価時の説明を追加してもらうことができるので、説明に推定の根拠を書いてもらうように情報を与えています。
さて、どのようなプロンプトで最大寸法を得るのかを決めたので、どのような指標で最大寸法推定モデルの性能を評価できるかを考えていきます。
簡単に考えれば、Geminiが出力した最大寸法と、元々の最大寸法推定モデルが出力した最大寸法が一致しているかどうかで評価できそうです。ただ少しマージンを持たせて、どれくらいずれているか、という割合を評価指標として使うことにします。
具体的には、以下の計算式で評価します。
score = round(1 - (abs(float(max_dimension) - float(ground_truth)) / float(ground_truth)), 3)
max_dimensionがGeminiが出力した最大寸法、ground_truthが元々の最大寸法推定モデルが出力した最大寸法です。
このスコアを評価指標に使う方法として、VertexAIのCustomMetricを利用します。
custom_metric = CustomMetric(
name="score",
metric_function=custom_score,
)
custom_score_simpleは先ほどの処理を踏まえ以下の通りに定義します。
def custom_score(instance): question = instance["context"]["question"] image = instance["context"]["image"] ground_truth = instance["ground_truth_dimension"] eval_instruction_template = """ # Instruction You are a specialist of reading manufacture drawings. You will be provided with a question and an image of a manufacture drawing. Your task is to extract the maximum dimension of the image. Please leave why you think the maximum dimension is the correct answer in the explanation section. """ # read image from uri image_file = Part.from_uri(image, "image/png") evaluation_prompt = [ eval_instruction_template, "QUESTION: ", question, "IMAGE: ", image_file, ] # get_autorater_responseは上部で定義 evaluation_response = get_autorater_response(evaluation_prompt) max_dimension = evaluation_response.get("max_dimension", "") score = round(1 - (abs(float(max_dimension) - float(ground_truth)) / float(ground_truth)), 3) return { "score": score, "max_dimension": evaluation_response.get("max_dimension", ""), "explanation": evaluation_response.get("explanation", ""), }
ここで返却するDictの形で最終的なレスポンスのを定義できます。他にも返したいものがあるときは、get_autorer_responseのmetric_response_schemaを適切な形に変更して、ここで返却するDictの形も変えると良いです。引数のcontextは後段の処理で与えられることになります。
続いてEvalTaskを使って評価します。
ground_truth_dimension = ["214"] eval_dataset = pd.DataFrame( { "prompt": question, "context": context, "ground_truth_dimension": ground_truth_dimension, } ) metrics = [custom_metric] experiment_name = "eval-multimodal-metric" eval_task = EvalTask( dataset=eval_dataset, metrics=metrics, experiment=experiment_name, ) eval_result = eval_task.evaluate()
eval_datasetがcustom_metricの引数として与えられます。
これで結果を得るための準備は整いましたので、評価結果を見てみましょう。
評価結果の確認
得られたeval_resultを整形すると、以下のようにまとめられます。
| score | max dimension | explanation |
|---|---|---|
| 1.0 | 214.0 | The maximum dimension is 214, which represents the total length of the part, measured horizontally. |
max dimensionが214を返しているため、ground truthと完全一致し、scoreは1を返しています。
explanationを見ると、ある部分の水平方向の全長を取ったと説明していて、適切なところから寸法を推定したことがわかります。この説明があるおかげで、実際に最大寸法推定モデルと推定値がずれてしまった場合に、結果が妥当かどうかが全く図面を読めない初心者でも評価する助けにもなりそうです。
追加実験
更に他のタスクや評価指標も追加して複数のタスクの評価をやってみたいと思います。
追加のタスクは、与えられた画像が図面なのか、全く関係ない画像なのかを分類するタスクを考えてみます。
例として、以下の見積書のような画像を推論対象に追加してみます。

今度はそれも考慮してコードを少し変更してみます。
def custom_score(instance): question = instance["context"]["question"] image = instance["context"]["image"] ground_truth = instance["ground_truth_dimension"] eval_instruction_template = """ # Instruction You are a specialist of reading manufacture drawings. You will be provided with a question and an image of a manufacture drawing. Your task is to extract the maximum dimension of the image. Please leave why you think the maximum dimension is the correct answer in the explanation section. If target image is not a manufacture drawing, please return 1.0 as the maximum dimension and write "Not a drawing" in the drawing_or_not section. If you think the image is a manufacture drawing, please write "Drawing" in the drawing_or_not section. A manufacture drawing is a type of technical drawing that provides information about shape, dimensions, and materials of a part. It should have some of the figures like lines, circles, arcs, and text. """ # read image from uri image_file = Part.from_uri(image, "image/png") evaluation_prompt = [ eval_instruction_template, "QUESTION: ", question, "IMAGE: ", image_file, ] evaluation_response = get_autorater_response(evaluation_prompt) max_dimension = evaluation_response.get("max_dimension", "") score = round(1 - (abs(float(max_dimension) - float(ground_truth)) / float(ground_truth)), 3) return { "score": score, "max_dimension": evaluation_response.get("max_dimension", ""), "drawing_or_not": evaluation_response.get("drawing_or_not", ""), "explanation": evaluation_response.get("explanation", ""), }
Instructionの内容に、図面かどうかを分類するように指示を追加し、返却するDictのキーにその結果が入るようにしました。また、図面でない場合は仮の値で1.0を返すようにも指示しています。
評価の実行部分に関しては、以下のように更新します。
context = [
{
"question": question,
"image": "gs://path/to/image1",
},
{
"question": question,
"image": "gs://path/to/image2",
},
]
ground_truth_dimension = ["214", "1.0"]
ground_truth_drawing = ["Drawing", "Not a Drawing"]
reference = ["Drawing", "Not a drawing"]
eval_dataset = pd.DataFrame(
{
"prompt": question,
"context": context,
"response": ground_truth_drawing,
"reference": reference,
"ground_truth_dimension": ground_truth_dimension,
}
)
custom_metric = CustomMetric(
name="score",
metric_function=custom_score_simple,
)
metrics = ["exact_match", custom_metric]
experiment_name = "eval-multimodal-metric"
eval_task = EvalTask(
dataset=eval_dataset,
metrics=metrics,
experiment=experiment_name,
)
eval_result = eval_task.evaluate()
metricsにexact_matchを追加しました。指標の例としてはこちらにありますが、ここではDrawingorNot a Drawingの2択のうち、出力した結果が完全一致しているかを指標として追加しています。
また、exact_matchを利用する際にはreferenceがcontextのcolumnが必要なので追加しています。
同じように、この時の結果の表を見てみましょう。
| response | score | score/max_dimension | score/drawing_or_not | score/explanation | exact_match/score |
|---|---|---|---|---|---|
| Not a Drawing | 1.0 | 1.0 | Not a Drawing | There are no dimensions, lines, arcs, or circles in this image. | 1.0 |
| Drawing | 1.0 | 214.0 | Drawing | The maximum dimension is 214 which is the length of the part. | 1.0 |
図面かそうでないのかの回答についてはしっかり正解しています。説明にも図面でない理由を説明してくれています。exact_match/scoreに関しても、いずれも正解と一致しているため1.0となっています。
まとめ
ここまでの実験により、LLMを使うことでデプロイ後のモデルの精度を監視できそうな予感がしました。
もちろん、実際には評価用のLLMを用意するコストや、評価用のプロンプトを作成するコスト、評価用のデータを用意するコストなどがかかります。それでも人がアノテーションするコストよりは安く、かつ早く評価することができるのではないかと思いますので、実際に運用してみる価値はありそうです。
ただ外部のLLMを使っているので、モデル自体をコントロールできないというリスクはあります。なので、できるならば自社でLLMを学習させ、そのモデルを評価用LLMとして使うことが望ましいかもしれません。図面解析LLM、ちょっと夢があります。
そんなCADDiは機械学習エンジニア、MLOpsエンジニアを始め、様々なポジションでのメンバーを募集しています。
少しでも興味をお持ちいただけましたら、以下の採用ページよりお問い合わせください。
カジュアル面談もお待ちしております!
ML Engineer
Machine Learning Engineer / キャディ株式会社
MLOps Engineer
MLOps Engineer / キャディ株式会社
Data Engineer
Data Engineer / キャディ株式会社