はじめに
こんにちは、Platformチームの小森です。
eBPF (extended Berkley Packet Filter) について、2022年8月2日に開催された社内勉強会で発表しました。
eBPFはここ数年で注目が集まっている技術で、2021年にはeBPF Foundationが設立され、Facebook、Google、Isovalent、Microsoft、Netflixなどの大手IT企業が参画を進めています。
筆者は概要程度しか把握していなかったので、遅ればせながらキャッチアップのために情報収集しました。すでに多くの情報が出回っているので新規性は少ないですが、引用元を示しつつ、短時間で理解できるようにまとめてみました。
特に次のような方は、eBPFの概要を押さえておくと良いのではないかと思います。
- Kubernetesに興味がある、または使っている
- Linuxの中でもネットワーク周りの基盤技術に興味がある
- 日々障害調査に追われている
- iptablesが大好き
eBPF とはなにか
ざっくり概要
eBPF(extended Berkley Packet Filter)は、Linuxカーネル内でのイベント発生時に動作する処理を、安全・手軽に組み込むための仕組みで、現在ではLinuxカーネルの機能として提供されています。
eBPFは、カーネル空間で動作する仮想マシンです。仮想マシンというと、VMWare、VirtualBox、KVMなど、ハードウェアを含めてエミュレートするハイパーバイザを思い浮かべるかもしれませんが、eBPFは専用の命令セットを持った仮想的なCPUのようなものです。小型のJavaVMのようなものがカーネル内で動作するとイメージすれば良さそうです。
JavaVMと同じように、eBPF専用のバイトコードを渡すと、カーネル内部で検証され、実際に動作するマシンコードにコンパイルされたのちに、カーネルに組み込まれます。
「Packet Filter」なのに「Virtual Machine」?
なぜ、eBPFは「Packet Filter」という名称なのに、実体は Virtual Machine なのでしょうか。理由は、その発展の歴史にあります。
eBPFの歴史は意外に古く、約30年前の1992年に、ローレンス・バークレー国立研究所のSteven McCanneとVan Jacobsonが公開した論文「The BSD Packet Filter: A New Architecture for User-level Packet Capture」にさかのぼります。
当初はその名のとおり、パケットキャプチャやフィルタリングを効率化するための技術でした。
現在でも、障害調査などで特定の宛先やポートで通信されるパケットを取得したいことはよくあります。 ネットワークでやりとりされるパケットをキャプチャして必要なものだけを抽出(フィルタ)するには、カーネル空間で動作するネットワークドライバはキャプチャしたパケットを、ユーザー空間で動作するアプリケーションに渡し、アプリケーション側でフィルタ処理を行う必要がありました。
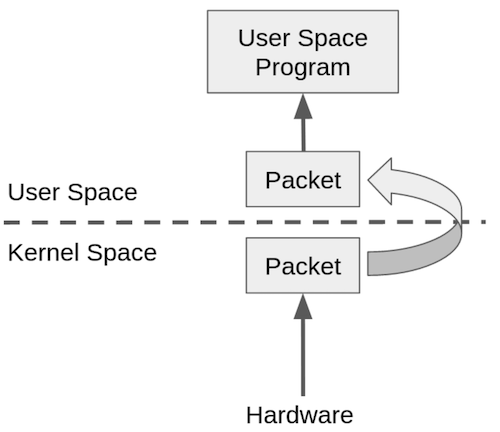 [出典] : BPF Overview The BSD Packet Filter: A New Architecture for User-level Packet Capture
[出典] : BPF Overview The BSD Packet Filter: A New Architecture for User-level Packet Capture
このような作りでは、カーネル空間とユーザー空間の切替が多く発生し、効率がよくありません。 そこで、カーネル空間で動作する仮想マシンを用意し、その上でパケットをフィルタリングするアプリケーションを実行できるようにすれば、多くの処理がカーネル空間で完結するのでパフォーマンスが向上するというのが基本的なアイデアです。
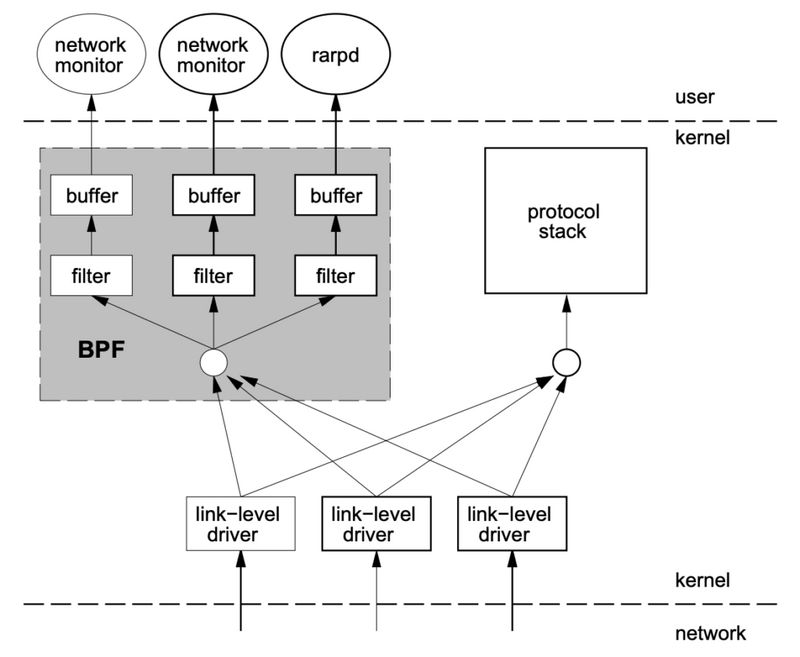 [出典] : BPF Overview The BSD Packet Filter: A New Architecture for User-level Packet Capture
[出典] : BPF Overview The BSD Packet Filter: A New Architecture for User-level Packet Capture
BPFは当初BSDに実装されたのち、1997年にLinuxカーネル2.1.75に移植されました。 BPFを利用したパケットキャプチャとフィルタリング機能はlibpcapというライブラリとして実装され、現在でもよく使われているパケットキャプチャツール、tcpdumpで利用されています。
そしてしばらく時がたち、2013年、対象をネットワークパケットだけに限らず、より汎用化した仕組みとして「eBPF」が提案されました。2014年、eBPFがLinuxカーネル3.17に組み込まれて拡張が続き、今にいたります。
eBPFと対比して、当初のBPFを「cBPF (classic BPF)」と呼ぶこともあります。なお、現在ではeBPFは 「which is no longer an acronym for anything (何の略称でもない)」とされています。
[出典]
eBPFでなにができるか?
カーネルイベントのフック
eBPFでは、ネットワークだけではなく、さまざまなカーネル内のイベントをフックし、さまざまな処理を実行することができます。
フックできるカーネルイベントは「Program Types」として定義されています。
いくつかの記事を参考にして大別すると、以下のようになります。Program Typeの説明は、原文のほうが分かりやすいので、翻訳せずに出典からそのまま引用しました。
- ソケット操作 - パケットフィルタリングや、コネクション確立/タイムアウトなどのソケット属性変更、パケットのリダイレクトなどのイベント
BPF_PROG_TYPE_SOCKET_FILTER: a network packet filterBPF_PROG_TYPE_SOCK_OPS: a program for setting socket parametersBPF_PROG_TYPE_SK_SKB: a network packet filter for forwarding packets between sockets
- トンネリング - ネットワークスタック内のパケットカプセル化フレームワークに関するイベント
BPF_PROG_TYPE_LWT_*: a network packet filter for lightweight tunnels
- 帯域制御 - 帯域制御を実現するためのイベント
BPF_PROG_TYPE_SCHED_CLS: a network traffic-control classifierBPF_PROG_TYPE_SCHED_ACT: a network traffic-control action
- XDP(Xpress Data Path) - NICから受け取ったパケットデータを直接操作するためのイベント
BPF_PROG_TYPE_XDP: a network packet filter run from the device-driver receive path
- トレーシング - カーネル関数呼び出し、カーネル関数内のイベント発生、パフォーマンスカウンタなどのイベント
BPF_PROG_TYPE_PERF_EVENT: determine whether a perf event handler should fire or notBPF_PROG_TYPE_KPROBE: determine whether a kprobe should fire or notBPF_PROG_TYPE_TRACEPOINT: determine whether a tracepoint should fire or not
- Cgroups - Cgroup(プロセスをグループ化してリソース割り当てを制御する機構)におけるイベント
BPF_PROG_TYPE_CGROUP_SKB: a network packet filter for control groupsBPF_PROG_TYPE_CGROUP_SOCK: a network packet filter for control groups that is allowed to modify socket optionsBPF_PROG_CGROUP_DEVICE: determine if a device operation should be permitted or not
当初のBPF(いわゆるcBPF)で実現されていたのは、ネットワーク処理の部分だけでしたが、eBPFではさまざまなフックポイントが追加されていることがわかります。
[出典]
- A thorough introduction to eBPF (上記Program Typeの説明は、本記事より引用)
- BPF: A Tour of Program Types
- @IT - Berkeley Packet Filter(BPF)入門(4) - LinuxのBPFで何ができるのか? BPFの「プログラムタイプ」とは
- eBPF - 入門概要 編
- 「おいしくてつよくなる」eBPFのはじめかた
ユーザーランドアプリケーションとのやりとり
eBPFプログラムは、Program Typesでフックしたイベントによって動作し、処理結果をユーザー空間で実行するアプリケーションと受け渡しすることができます。
具体的には、Mapsという機構が提供されており、ハッシュテーブルや配列、LRU、リングバッファなどの各種データ構造が使えます。
eBPFの主な用途
eBPFが使われているプロダクトは、こちら のサイトで紹介されていますが、いくつかを簡単に紹介します。
ネットワーク制御
- Cilium
- コンテナ間通信に対してパケット処理に可観測性・セキュリティ・高度な通信制御を付与するソフトウェア。主にKubernetesでの利用を想定
- Katran
- Facebookが開発する、XDPを活用した高性能L4ロードバランサ
- Pixie
- Kubernetesアプリケーションから自動でテレメトリデータを取得してObservability(可観測性)を向上させるツール
- Cloudflare Magic Firewall
- プロダクトではないが、Cloudflare のDDoS対策機能として利用されている
セキュリティ
トレーシング
- bpftrace
- BPFをラップするDSL(Domain Specific Language)を提供する、汎用的なトレーシングツール
このように、eBPFが提供するさまざまなフックポイントを活用したプロダクトが作られています。
eBPFが注目される背景
近年eBPFが注目されている背景には、Kubernetes(以下、k8s)の普及によるアプリケーションのコンテナ化やマイクロサービス化が進んでいることがあると思われます。
k8sでコンテナ間の通信を実現するには、Linuxに古くからある netfilter/iptables が使われています。
netfilter は、BPFと同様にカーネル内のネットワークスタックのさまざまな場所に、コールバック関数を追加できるしくみで、iptablesはそのフロントエンドツールです。
iptablesはnetfilterを使ってパケットのフィルタリングや転送を実現し、Linuxによるファイアウォールやネットワークルータの実現には、古くからiptablesが利用されていました。
さきほど述べたように、k8sにおけるコンテナ間通信にも、netfilter で実現されています。
しかし、k8sクラスタで管理されるコンテナが増えるにしたがって、iptablesの問題点が浮き上がってきました。
iptablesは、ルール順番に処理してマッチしたパケットを処理する仕組みなので、ルールの量(つまり通信するコンテナの数)に比例して遅くなってしまいます。
たとえば、eBPFの機能の1つであるXDP(Express Data Path)を活用することで、NICに近いところでパケットを受け取り、独自に処理して高速なコンテナ間通信を実現しようとしているのが、eBPFを活用したプロダクトでも特に注目を集めているCiliumです。 (Ciliumについては、前多さんの記事を参照ください)
また、コンテナ環境を活用してシステムのマイクロサービス化が進むと、安定運用のために通信や各種メトリクス、パフォーマンスを把握する必要性が高まり、可観測性やセキュリティもより重要視されます。
このようなニーズにも、冒頭で紹介したeBPFの多彩なフックポイントと、カーネル空間内で高速処理できるという特性がマッチしていると思われます。
[出典]
eBPFの仕組み
アーキテクチャと処理フロー
eBPFの概要や背景がわかったところで、その仕組みをもう少し追ってみましょう。
eBPF - 入門概要 編 - eBPFアーキテクチャ概要 で説明されている図が分かりやすかったので、これを参考にアーキテクチャの説明図を書きました。
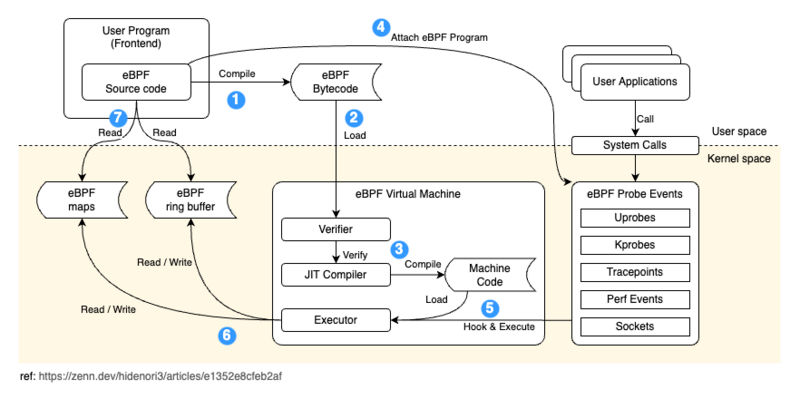
この図に使って、eBPFの大まかな処理フローを説明します。
- eBPFを扱うユーザープログラムは、eBPFソースコードをコンパイルしてバイトコードに変換する
- システムコールを使用してeBPFバイトコードをカーネルへロードする
- eBPF Verifierがバイトコードを検証。問題なければコンパイラによって機械語に変換する
- ユーザープログラムはeBPFプログラムを目的のイベントにアタッチする
- イベントが発生すると、ExecutorがeBPFプログラムを実行
- 処理結果を map や ring buffer へ格納
- ユーザープログラムが結果を参照
カーネルモジュールとeBPFの違い
もともと、Linuxには「カーネルモジュール」という仕組みがあり、カーネルモジュールを作成することでカーネル空間で動く処理を追加で組み込めるようになっており、これを使ってカーネルの機能を拡張できるようになってる。
カーネルモジュールの代表例としては、ファイルシステムや、デバイスドライバなどハードウェアを制御するプログラムが挙げられます。
一方で、カーネルモジュールは自由度が高すぎるため、作りが悪いとカーネルをクラッシュさせる危険性があります。また、modprobeコマンドで明示的にロード/アンロードする必要があります。もともとデバイスドライバやファイルシステムなどの使い方が想定されていたので、頻繁にロード/アンロードすることは想定されておらず、特定のアプリケーション実行時だけカーネルに処理を組み込むといった使い方がしにくいです。
eBPFでは、ユーザー空間で動作するアプリケーションからシステムコールを呼び出すことで、カーネル空間で動作するeBPFプログラムを動的に組み込むことができます。
また、eBPFでは実行されるプログラムに一定の制約をつけ、Verifierによる検証をパスしなければカーネルに組み込めないような仕組みとして安全性を高めています。
Linuxのリポジトリに、検証器ののコード(verifier.c)があります。こちらのコメントを読むと、たとえば最初の段階では、次のようなチェックが行われるようです。 (参考1, 参考2)
- 命令数が一定数以下であること(大きなプログラムはダメ)
- ループがないこと
- 到達不可能な命令がないこと
- 境界の外に出る不正なジャンプがないこと
特に命令数やループなどの制約は、カーネル空間で実行される処理であることから、厳しめになっていることがわかります。
このような仕組みによって、カーネル空間での処理を手軽かつ安全にアドオンできるようになったことがeBPFとカーネルモジュールの違いです。eBPFによってカーネル空間での処理を手軽に作成できるようになったため、従来のようにカーネル空間とユーザー空間の切替を頻繁に行う必要もなくなり、パフォーマンス向上にも寄与できるようになりました。
[参考]
eBPFプログラムの作り方
eBPFプログラムの実際の作り方を見てみましょう。
eBPFは最終的に専用のバイトコードにしてカーネルに渡す必要があります。いきなりバイトコードを書くわけにもいかない(書くこともできますが)ので、現実的にはなんらかのプログラミング言語を使うことになります。
eBPFのプログラムはC言語で作成します。BCC(BPF Compiler Collection)というツールチェーンが公開されているので、これを使用してコンパイルします。
一方、eBPFプログラムをカーネルに組み込み、eBPFの処理結果を受け取ってユーザーに機能を提供するアプリケーション)を、eBPFのフロントエンドと呼びます。
eBPFのフロントエンドは、BCCの公式サポート範囲では、C++、Python、Luaで記述することができます。(世の中のサンプルを見渡すと、簡単なツールはPythonで書かれているものが多いようです)
また、BCC本体のサポート範囲ではありませんが、RustやGoといった新しい言語でもフロントエンドが作成できるようです。
また、さきほど紹介したbpftraceは、独自の言語(DSL:Domain Specific Language)を提供しており、トレース用途中心ではありますが、C言語を知らなくてもeBPFとして動作する処理を作成することができます。
bpftraceのGitHubリポジトリには、多数のサンプルが公開されています。
たとえば、次のようなワンライナーでプロセスが開くファイルを表示させることができます。
# Files opened by process
bpftrace -e 'tracepoint:syscalls:sys_enter_open { printf("%s %s\n", comm, str(args->filename)); }'
このように、コマンドラインからアドホックにeBPF処理を実行できるのがbpftraceの魅力です。
eBPFプログラムを作ってみる
ここからは、実際にeBPFのプログラムを作成して理解を深めます。
環境の準備
今回は、GCP の Computing Engine に CentOS8 の仮想マシンを作り、そこで試しました。
先ほど紹介したbpftraceが標準のパッケージマネージャで提供されているので、コマンド一発でインストールできます。
sudo dnf -y install bpftrace
bpftraceをインストールすると、bccも同時にインストールされて使えるようになります。
Hello world
BCCの公式リポジトリにあるサンプルから、もっとも簡単なものを選んで実行してみます。
hello_world.py を少しだけ分かりやすく書き直したものが、以下のコードです。
このサンプルは、Pythonをフロントエンドとして書かれています。
from bcc import BPF bpf_src=""" int kprobe__sys_clone(void *ctx) { bpf_trace_printk("Hello, World!\\n"); return 0; } """ b = BPF(text=bpf_src) b.trace_print()
上のプログラムの最終行でBPF関数に渡しているテキストのC言語部分が、eBPFのコードです。
抜き出したものが以下のコードです。
int kprobe__sys_clone(void *ctx) { bpf_trace_printk("Hello, World!\\n"); return 0; }
イベント名__関数名という命名ルールで、カーネル内の関数にフックできます。(ここでは、kprobe__sys_clone)kprobeは、カーネル内の関数呼び出し前のイベントであることを示します。sys_cloneは、Linuxでプロセスがforkされるときに呼び出されるシステムコールです。(この関数はカーネルのバージョンやCPUアーキテクチャによって異なることがあるので注意 (※))
eBPFプログラムの3行目では、 bpf_trace_printk という関数を呼び出しています。これは主にeBPFのデバッグ用途でカーネル空間からユーザー空間へ文字列を渡すためのものです。
Pythonで書いたフロントエンドコードの11行目でBPF関数を呼び出すことにより、eBPFプログラムをコンパイルされ、カーネルへ組み込まれます。
そして、12行目の trace_print 関数で、bpf_trace_printk が出力した文字列を受け取って表示しています。 (このあたりの仕組みは eBPF の紹介 - Qiita で詳しく解説されています)
このサンプルを実行し、別のターミナルでコマンドを実行すると、そのたびに「Hello, World!」が表示されます。
実用性はありませんが、eBPFプログラムの書き方と組み込み方、結果の受け取りかたがわかりました。
(※) 「この関数はカーネルのバージョンやCPUアーキテクチャによって異なることがあるので注意」・・・BPFのプログラムは、その特性上CPUアーキテクチャやカーネルのバージョンに依存してしまいます。このためBPFを実際に実行するマシン上でコンパイルするのが原則のようです。このあたりのポータビリティを高めるしくみとして、 BPF CO-RE(Compile Once - Run Everywhere) が考案されており、ある環境でコンパイルしたBPFコードを他の環境でも実行できるようにしています。
もう少し複雑なサンプル
eBPF側からフロントエンド側に情報を渡す、もう少し実用的なサンプルを動かしてみます。
第690回 BCCでeBPFのコードを書いてみる | gihyo.jp で紹介されているコードを写経しました。 eBPF部分には、少しコメントを追加しました。
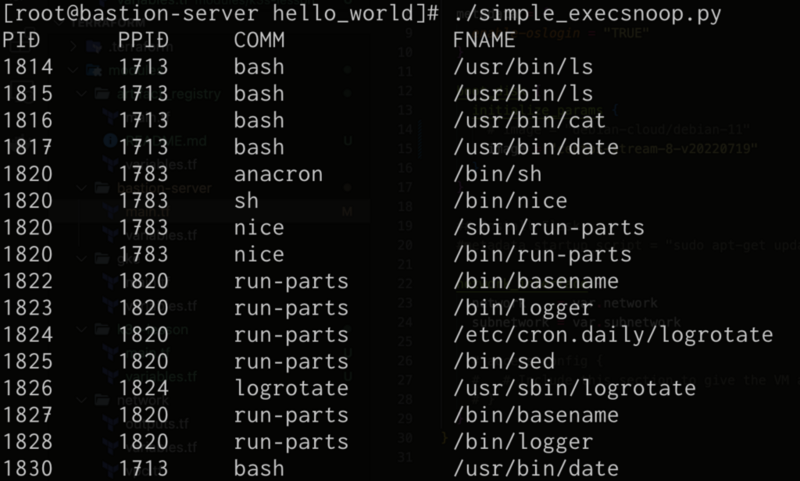
#!/usr/bin/python3 from bcc import BPF bpf_text=""" #include <linux/sched.h> /* Information passed from eBPF to frontend */ struct data_t { u32 pid; u32 ppid; char comm[TASK_COMM_LEN]; char fname[128]; }; /* Make ring buffer named `events` */ BPF_PERF_OUTPUT(events); int syscall__execve(struct pt_regs *ctx, const char __user *filename) { struct data_t data = {}; struct task_struct *task; /* Get PID */ data.pid = bpf_get_current_pid_tgid() >> 32; /* Get Parent PID */ task = (struct task_struct *)bpf_get_current_task(); data.ppid = task->real_parent->tgid; /* Get current task program name */ bpf_get_current_comm(&data.comm, sizeof(data.comm)); /* Get execve argument from user space */ bpf_probe_read_user(data.fname, sizeof(data.fname), (void *)filename); /* Stores data in a ring buffer */ events.perf_submit(ctx, &data, sizeof(struct data_t)); return 0; } """ b = BPF(text=bpf_text) b.attach_kprobe(event=b.get_syscall_fnname("execve"), fn_name="syscall__execve") print("PID PPID COMM FNAME") def print_event(cpu, data, size): # Get eBPF data from `event` ring buffer event = b["events"].event(data) print("{:<8} {:<8} {:16} {}".format(event.pid, event.ppid, event.comm.decode(), event.fname.decode())) b["events"].open_perf_buffer(print_event) while True: try: b.perf_buffer_poll() except KeyboardInterrupt: exit()
今度は、eBPF部分が長くなっていますが、関数はsyscall__execveの1つです。
execveは、指定したファイルを実行する時に使用するシステムコールです。システムコールの引数をeBPFから取得する場合は、 syscall イベントでアタッチします。
execve システムコールが実行されるときに、その引数をeBPFで取得してdata_t構造体に格納し、リングバッファ経由でユーザー空間で動くフロントエンドへ送ります。
フロントエンド側では、リングバッファからデータを取得して整形して出力しています。
実行例は以下のようになります。プログラムを実行して他のターミナルで ls や cat コマンドを実行すると、そのログが表示されますし、バックグラウンドで実行されているプログラムも検知できています。
その他のサンプル
最初に紹介した、BCCのリポジトリには豊富なサンプルが公開されており、サンプルに留まらず、実用性のあるツールも多数公開されています。多くは数百行程度なので、勉強がてら自分の用途に改造して使うこともできそうです。
ツールとサンプルの一覧はこちらです。
https://github.com/iovisor/bcc#contents
最後に、このなかから実用性がありそうなものを、いくつか選んで紹介します。
HTTPリクエストのダンプ
TCP接続先の調査
PID COMM SADDR DADDR DPORT 1479 telnet 127.0.0.1 127.0.0.1 23 1469 curl 10.201.219.236 54.245.105.25 80 1469 curl 10.201.219.236 54.67.101.145 80
tcplife
実行中に開始/終了されたTCPセッションを記録します。
PID COMM LADDR LPORT RADDR RPORT TX_KB RX_KB MS 22597 recordProg 127.0.0.1 46644 127.0.0.1 28527 0 0 0.23 3277 redis-serv 127.0.0.1 28527 127.0.0.1 46644 0 0 0.28 22598 curl 100.66.3.172 61620 52.205.89.26 80 0 1 91.79 22604 curl 100.66.3.172 44400 52.204.43.121 80 0 1 121.38 22624 recordProg 127.0.0.1 46648 127.0.0.1 28527 0 0 0.22 3277 redis-serv 127.0.0.1 28527 127.0.0.1 46648 0 0 0.27 22647 recordProg 127.0.0.1 46650 127.0.0.1 28527 0 0 0.21 3277 redis-serv 127.0.0.1 28527 127.0.0.1 46650 0 0 0.26 [...]
dirtop
ディレクトリ単位でのread/writeの記録。
# ./dirtop.py -d '/hdfs/uuid/*/yarn' Tracing... Output every 1 secs. Hit Ctrl-C to end 14:28:12 loadavg: 25.00 22.85 21.22 31/2921 66450 READS WRITES R_Kb W_Kb PATH 1030 2852 8 147341 /hdfs/uuid/c11da291-28de-4a77-873e-44bb452d238b/yarn 3308 2459 10980 24893 /hdfs/uuid/bf829d08-1455-45b8-81fa-05c3303e8c45/yarn 2227 7165 6484 11157 /hdfs/uuid/76dc0b77-e2fd-4476-818f-2b5c3c452396/yarn 1985 9576 6431 6616 /hdfs/uuid/99c178d5-a209-4af2-8467-7382c7f03c1b/yarn 1986 398 6474 6486 /hdfs/uuid/7d512fe7-b20d-464c-a75a-dbf8b687ee1c/yarn 764 3685 5 7069 /hdfs/uuid/250b21c8-1714-45fe-8c08-d45d0271c6bd/yarn [...]
filetop
ファイル単位でのread/writeしたプロセスのトレース
# ./filetop -C Tracing... Output every 1 secs. Hit Ctrl-C to end 08:00:23 loadavg: 0.91 0.33 0.23 3/286 26635 PID COMM READS WRITES R_Kb W_Kb T FILE 26628 ld 161 186 643 152 R built-in.o 26634 cc1 1 0 200 0 R autoconf.h 26618 cc1 1 0 200 0 R autoconf.h 26634 cc1 12 0 192 0 R tracepoint.h 26584 cc1 2 0 143 0 R mm.h 26634 cc1 2 0 143 0 R mm.h 26631 make 34 0 136 0 R auto.conf [...]
oomkill
OOM killerによるプロセスkillイベントのトレース。
# ./oomkill
Tracing oom_kill_process()... Ctrl-C to end.
21:03:39 Triggered by PID 3297 ("ntpd"), OOM kill of PID 22516 ("perl"), 3850642 pages, loadavg: 0.99 0.39 0.30 3/282 22724
21:03:48 Triggered by PID 22517 ("perl"), OOM kill of PID 22517 ("perl"), 3850642 pages, loadavg: 0.99 0.41 0.30 2/282 22932
まとめ
eBPF登場の背景と位置づけを確認し、大まかな仕組みとサンプルの実行を通してeBPFプログラムの作り方を確認しました。
発展中の技術であるため、体系的な情報はまだ少ない印象ですが、サンプルが豊富なので試行錯誤しながら習得していくこともできそうです。
一方で使いこなすにはC言語やカーネルのシステムコールなど、比較的低レイヤーの知識が必要になるため、習得には一定の時間がかかりそうです。(おそらく、bpftraceでこのハードルが下がりそうです)
eBPFはなにに使えるか
全体としては、採用プロダクト例で挙げたように、特にネットワーク周りの基盤技術や、可観測性(Observability)の強化が主な用途になると思いました。
一般のエンジニアがeBPFのコードをバリバリ書けるようになる必要は、あまり無さそうですが、eBPFの仕組みを理解しておくと、これから登場するeBPFを活用したプロダクトを使いこなす時に理解が進むと思います。
また、bpftraceのようなツールを使いこなせるようになると、障害調査に使える武器として大いに役立ちそうです。
個人的には、システム運用の場面で監査やセキュリティチェックなど、プロダクト独自のニーズが生じたときに、eBPFを活用できるのではないかと期待しています。
ここまでお読みいただきありがとうございました。
CADDiでは、現在積極的に採用を行っています。 まずはカジュアルにお話を聞いてみたい!という方は、ぜひこちらより面談をお申し込みください。 また、Tech Blogや勉強会等のイベントについてはSNSで随時発信しておりますので、Twitterのフォローや、connpassのメンバー登録をぜひよろしくお願いします。
参考サイト
記事中でも断片的に示しましたが、eBPFについて体系的に紹介されていて参考になったサイトを紹介します。
- @IT連載 > Berkeley Packet Filter(BPF)入門 全10回の連載でかなりボリュームがありますが、Web上の日本語での説明が一番よくまとまっています。著者はbpftraceのコミッタでもあります。
- (1) : パケットフィルターでトレーシング? Linuxで活用が進む「Berkeley Packet Filter(BPF)」とは何か
- (2) : BPFのアーキテクチャ、命令セット、cBPFとeBPFの違い
- (3) : BPFプログラムの作成方法、BPFの検証器、JITコンパイル機能
- (4) : LinuxのBPFで何ができるのか? BPFの「プログラムタイプ」とは
- (5) : BPFによるパケットトレース――C言語によるBPFプログラムの作り方、使い方
- (6) : BCC(BPF Compiler Collection)によるBPFプログラムの作成
- (7) : Linux 5.5におけるBPF(Berkeley Packet Filter)の新機能
- (8) : BPFを使ったLinuxにおけるトレーシングの基礎知識
- (9) : BPFによるトレーシングが簡単にできる「bpftrace」の使い方
- (10) : 単なるデバッグ情報だけではない「BPF Type Format」(BTF)の使い道
- 「eBPF - 入門」 必要な要素がコンパクトにまとまっています。私もこの記事を取っ掛かりとしました。