こんにちは。 Platformチームの前多(@kencharos)です。
2022年8月9日に開催した社内勉強会で、eBPFベースのネットワークミドルウェア、Cilium(スリィアム) について発表しました。 この記事は発表の内容をベースに内容を補足したものです。
この記事を読むにあたり、Kubernetesをある程度触ったことがないと用語などが分かりづらいかもしれません。 サービスメッシュやIstioについては、構成や導入目的について簡単に次節に記載しています。 より詳しく知りたい方はIstioのサービスメッシュの説明を見てもらえると、Ciliumとの対比がわかりやすくなるでしょう。 またサービスメッシュを触ったことがある、あるいは運用している方であれば、Ciliumの魅力がより伝わると思います。 eBPFの知識は必要ありません。またeBPFについて同僚も社内勉強会で発表していますので、eBPFについて詳しく知りたい方は以下の記事を見てください。
はじめに
私はこれまでに3度サービスメッシュをプロダクトに導入した経験があります。 サービスメッシュを導入する目的はプロダクトに応じて様々ですが、私の中では観測性(Observability)を基盤側で提供することを主な目的としています。
例えば、Kubernetesクラスタにサービスメッシュを導入すると、クラスタ内の各PodのHTTPレベルのメトリクスやアクセスログの取得をアプリケーションの改修なしで実現できます。 GCPのCloud RunやApp EngineといったPaaSでも自分でデプロイしたアプリケーションの外側で、アクセスログやメトリクスの取得ができ、ダッシュボードなどの可視化の仕組みが提供されています。 それと同様の仕組みをKubernetesでもサービスメッシュを用いて実現できます。
こういった機能は従来のサービスメッシュでは各アプリケーションにプロキシとして挿入されるサイドカーと、サイドカーの管理を行うコントロールプレーンといったコンポーネントで実現されるのが普通です。 代表的なものが Istio ですね。また、サイドカーとして挿入されるプロキシはEnvoyが使われることが大半です。 実際私がこれまでに携わってた3度の経験でも、全て同様の構成でした。
サイドカーによるサービスメッシュは強力な方法ではあるものの、やはり結構複雑です。 透過的にサイドカーが挿入されるのはソースコードを変えることなく導入できて便利ですが、一方でその原理を理解しておかないと、なんとなく不安に思われたり通信障害の原因として真っ先に疑われがちだったりします。 また、サービスメッシュを導入しない場合と比較してパフォーマンスへの影響も気になるところですが、それはアプリケーションの性能要件と比較して妥協可能かどうかを判断すると良いでしょう。よほどクリティカルな状況でなければ問題になるほどの影響はないはずです。
といったようなサービスメッシュ導入あるあるをこなしていた時に、たまたま Cilium のことを見かけました。 eBPFがベースのネットワークライブラリであり、2022年8月時点の最新版の 1.12 では サイドカーフリーのサービスメッシュ機能がGAになったとの内容 を見て、Istioなどと比較してどこまでの機能が実現できるのかがとても気になりました。
なお、私は eBPFやネットワークレイヤーに関する知識はあまりありません。そのため知識不足により見当違いのことを書いている場合があるかもしれませんので、その場合はコメントいただけると幸いです。
Ciliumとは
Cilium は主にIsovalent社によってメンテナンスされているOSSのネットワークライブラリです。 OSSとして無償利用するほか、同社による有償サポートもあります。
Ciliumの主な機能は、eBPFを使用してカーネル内で行われるパケット処理に観測性・セキュリティ・高度な通信制御を付与することです。
オンプレミスやDockerネットワークに対して動かすことも可能なようですが、主な対象はKubernetesだと思います。 KubernetesにCiliumを導入すると、透過的にPod間の通信制御やHTTPメトリクスの取得といったサービスメッシュで実現してきた機能の一部がCiliumで実現できます。 また、Ingress Controllerも1.12から実装されました。
eBPFでKubernetesのネットワーク課題を解決する
Kubernetes ネットワークの課題とeBPFによる解消方法を簡単にまとめます。 KubernetesのPodネットワークの制御は主にiptableによって行われていますが、iptableはL3/L4に対するネットワーク制御のツールであり、多数のプロセスが動的・短期的にIP・Portを変えていくような Podネットワークでは大量のルール変更が必要で、そのオーバヘッドはPodが増えるほど無視できないものになります。 eBPFによりiptableを置換し、より効率的なパケット処理であったり、ユーザ空間からKubernetesのPodの情報を持ち込むことで、IP・PortしかないパケットにどのPod宛の通信であるかやL7レベルの情報を与えることができ、観測性の付与やセキュリティの向上を果たすことができます。
今回はCiliumを実際に試すことが目標だったので、あまり深掘りはできていません。より詳細な内容は 以下の資料を見ていただくのが良いでしょう。
- CNI Benchmark: Understanding Cilium Network Performance
- Replacing iptables with eBPF in Kubernetes with Cilium
Ciliumをインストールする
さて実際にCiliumをインストールして動作を試していきます。 Ciliumのinstall手順 によれば、主要なパブリッククラウドのKubernetesサービスのほか、ローカルの環境でも試すことができます。 今回私がCiliumを試した環境は以下の通りです。
- Cilium 1.12
- Minikube 1.26.0 on M1 macbook pro
Ciliumのコンポーネントの概要は公式ドキュメントを参照してください。 主要なコンポーネントは次の通りです。
- Cilium Agent: DaemonSet として動く Ciliumの基本機能を提供するコンポーネント
- CNI-plugin: Pod ネットワークの情報と連携する機能。通常KubernetesクラスタにはデフォルトのCNI pluginがあるためそれを無効化して インストールします
- Hubble: Ciliumネットワークを可視化し、Prometheusメトリクスを提供するツール
これらのコンポーネントがインストーラによってクラスタに導入されます。 インストーラはCilium CLI を使用するかHelm chartを使用します。 実際には CLIからのインストールもHelm経由です。
今回はHubbleのHTTPメトリクスを サービスごとにグループ分けをしたかったので、以下のような helm オプションを設定して Cilium, Hubble をインストールしました。
# Prometheusメトリクスを有効化してインストール
cilium install --helm-set prometheus.enabled=true --helm-set operator.prometheus.enabled=true
# Hubble のメトリクスに pod, namespace をタグ付けするように設定してインストール
cilium hubble enable --ui --helm-set hubble.metrics.enabled="{dns,drop:destinationContext=pod-short|namespace,tcp:destinationContext=pod-short|namespace,flow:destinationContext=pod-short|namespace,icmp:destinationContext=pod-short|namespace,http:destinationContext=pod-short|namespace}"
サンプルアプリケーションの実行
今回は front, backend, backend2という 3つのnginxコンテナを用意してCilium上でアプリケーションを実行します。 proxy_passで後続のサービスを指定することで、 front->backend1->backend2 というように数珠繋ぎでpodを接続します。
# nginx.conf 抜粋
server {
listen 80;
# front -> backend
location /api/ {
proxy_pass http://backend:80;
}
# front->backend->backend2
location /api2/ {
proxy_pass http://backend:80;
}
Ciliumはネットワークレイヤに対して動くツールなので、単にKubernetesにPodをデプロイするだけなら特にマニフェストを修正する必要はありません。
この時点で何度か pod にリクエストを送信し、可視化コンポーネントの hubble の UI を開くと次のような接続状態の可視化が得られます。

何もしなくても Pod間の接続状態が可視化ができてしまいました。 また、UIの下部にはパケットキャプチャのようなTCP接続のステータスが並んでいます。
どれか一つに注目してみると、パケットのIP・Portの他に宛先podやラベル情報が見て取れます。

これが eBPFによって持ち込まれたPodのContextで、これらの情報をパケット処理で扱えるようになります。
L7 Protocol visibility を設定する
サイドカーがなくてもPod間接続が可視化できるだけでも私としてはだいぶ驚いたのですが、どうせならもっとHubbleで可視化できる情報を増やしたいところです。 eBPFでL7 Protocolを動的に判定するような高度な処理ができるわけではありませんが、Kubernetesのマニフェストでヒントを与えることができます。
L7 Protocol Visibilityのドキュメント によれば、PodのアノテーションやCiliumNetworkPolicyといったリソースでPodの通信プロトコルを明示することができます。 ただし現時点では、HTTP,DNS,Kafka(beta)のみが指定可能です。
まずは、各Podのmanifestに次のようにio.cilium.proxy-visibilityアノテーションを設定してみます。
通信の入出力のポートで、TCP/UDPおよびL7プロトコル名を設定します。
apiVersion: apps/v1
kind: Deployment
metadata:
name: front
spec:
replicas: 1
selector:
matchLabels:
app: front
template:
metadata:
labels:
app: front
annotations:
"io.cilium.proxy-visibility": "<Egress/53/UDP/DNS>,<Egress/80/TCP/HTTP>,<Ingress/80/TCP/HTTP>"
これらのマニフェストを適用して再びHubble UIを表示すると、可視化される内容にHTTPのURLなどの情報が付加されていることがわかります。素晴らしい。

CiliumNetworkPolicy
続いて、CiliumNetworkPolicyリソースを設定してみます。
例えば次の例は front->backend の通信でPOSTメソッドしか受け付けないという定義です。
apiVersion: "cilium.io/v2"
kind: CiliumNetworkPolicy
metadata:
name: "front2backend"
spec:
description: "Only POST"
endpointSelector:
matchLabels:
app: backend
ingress:
- fromEndpoints:
- matchLabels:
app: front
toPorts:
- ports:
- port: "80"
protocol: TCP
rules:
http:
- method: POST
このリソースを適用すると今までのGETリクエストは通らなくなります。
% curl -i http://localhost:8083/api2/hello
HTTP/1.1 403 Forbidden
Server: nginx/1.23.1
Date: Mon, 29 Aug 2022 10:38:07 GMT
Content-Type: text/plain
Content-Length: 15
Connection: keep-alive
x-envoy-upstream-service-time: 0
Access denied
Hubble UIでもパケットのドロップが記録されます。
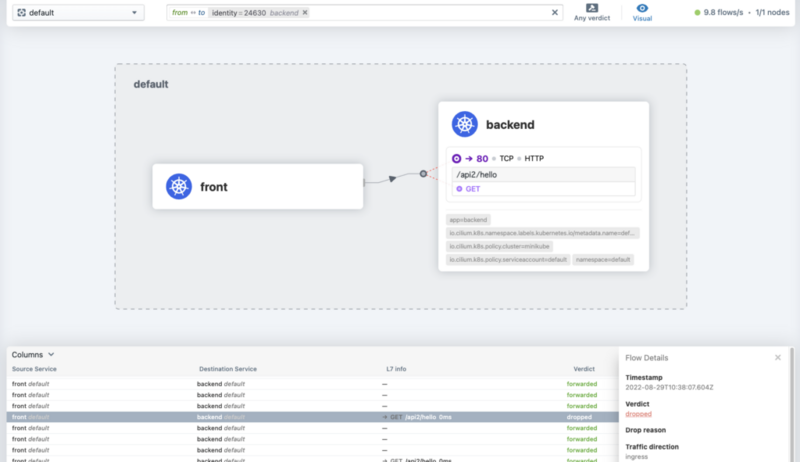
メトリクスを取得する
HubbleにはPrometheus用のメトリクスを提供する機能もあります。 こちら にある通り、メトリクスのタグにはPodの情報を付与できます。
ただし前述した通り、この内容はインストール時に明示的に設定する必要がありました。 コンテキストオプションを指定した場合、次のようにpod, http ステータスごとのメトリクスを得ることができます。
# HELP hubble_http_responses_total Count of HTTP responses
# TYPE hubble_http_responses_total counter
hubble_http_responses_total{destination="default/backend",method="GET",status="200"} 13
hubble_http_responses_total{destination="default/backend",method="GET",status="500"} 12
hubble_http_responses_total{destination="default/front",method="GET",status="200"} 13
hubble_http_responses_total{destination="default/front",method="GET",status="500"} 7
個人的にはサービスメッシュ導入の主目的であるメトリクスの取得が、これだけで実現できてしまって驚きました。
弊社ではモニタリングでDatadogを使用していて、CiliumとのIntegrationもありました。
現時点ではCilium AgentのメトリクスのみのようでHubbleのメトリクスはまだサポートされていないようですが、将来に期待して良いのではと思っています。
sidecar free service mesh
Cilium 1.12の目玉であるサービスメッシュの機能については、Cilium 1.12のリリース記事 や サービスメッシュのブログに内容がまとまっています。
Ciliumはネットワークコンポーネントなので、Istioのようなサイドカーベースのサービスメッシュと組み合わせて動かすこともできます。 1.12 ではそれに加えて、Ingress ControllerおよびCilium Agent と協調して動いているEnvoyへ、eBPFだけではできないネットワーク制御を適用する方法を、sidecar free のサービスメッシュというふうに表現しています。 Cilium AgentはサブプロセスとしてEnvoyもノード単位で動かしています。 eBPF (IngressController, TLS終端, L7 load balancing, リトライなど)をEnvoyに移譲するようになっていて、Envoyへの設定を適用するCRDが追加されています。 IstioなどではPodごとにサイドカーとしてEnvoyが必要ですが、 Ciliumの場合ノード単位で一つEnvoyがあれば良いので通信パフォーマンスが大幅に向上するとサービスメッシュのブログ には書かれています。 また、 ロードマップ でも今後さらなる機能追加が予定されています。
では、実際にいくつかのサービスメッシュのサンプルを試してみます。
サービスメッシュのサンプル1-サービス振り分け
最初は複数サービスを割合に応じて接続先を振り分けるというものです。
これまでのサンプルプリケーションにもう一つ、 backend3 というPodを追加し、次のようなCiliumEnvoyConfigリソースを適用します。
apiVersion: cilium.io/v2
kind: CiliumEnvoyConfig
metadata:
name: envoy-backend-listener
spec:
services:
# backend2,および backend3への接続がまとめられる。
- name: backend2
namespace: default
- name: backend3
namespace: default
resources:
- "@type": type.googleapis.com/envoy.config.listener.v3.Listener
name: envoy-backend-listener
filter_chains:
- filters:
- name: envoy.filters.network.http_connection_manager
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.network.http_connection_manager.v3.HttpConnectionManager
stat_prefix: envoy-backend-listener
rds:
route_config_name: lb_route
http_filters:
- name: envoy.filters.http.router
- "@type": type.googleapis.com/envoy.config.route.v3.RouteConfiguration
name: lb_route
virtual_hosts:
- name: "lb_route"
domains: [ "*" ]
routes:
- match:
prefix: "/"
route:
#接続を 50:50 で振り分ける
weighted_clusters:
clusters:
- name: "default/backend2"
weight: 50
- name: "default/backend3"
weight: 50
retry_policy:
retry_on: 5xx
num_retries: 3
per_try_timeout: 1s
- "@type": type.googleapis.com/envoy.config.cluster.v3.Cluster
name: "default/backend2"
connect_timeout: 5s
lb_policy: ROUND_ROBIN
type: EDS
outlier_detection:
split_external_local_origin_errors: true
consecutive_local_origin_failure: 2
- "@type": type.googleapis.com/envoy.config.cluster.v3.Cluster
name: "default/backend3"
connect_timeout: 3s
lb_policy: ROUND_ROBIN
type: EDS
outlier_detection:
split_external_local_origin_errors: true
consecutive_local_origin_failure: 2
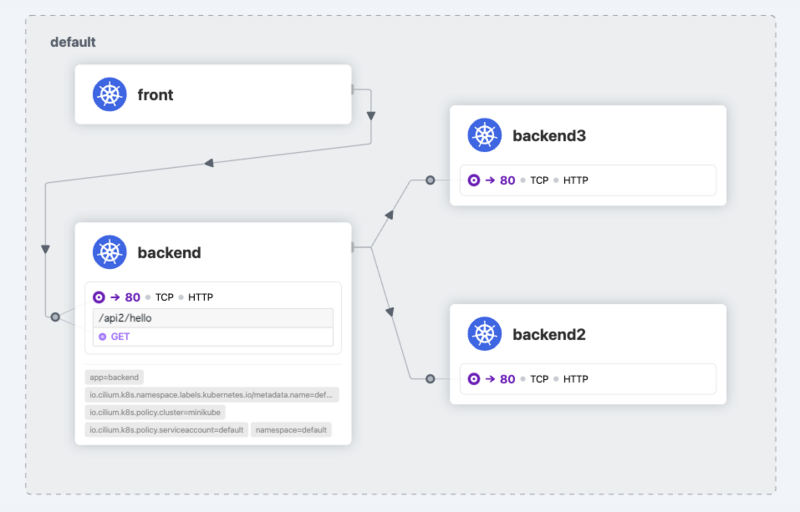
CiliumEnvoyConfigリソースはCilium Agentの Envoyに対して設定をするためのリソースで、ここでは backend2, backend3への接続に対してEnvoy Listenerを起動して接続をプロキシするようになります。 その後、weighted_clustersの設定で接続を割合で振り分けるようになります。

backend Podのnginxにはproxy_passとして backend2 しか記述がないにもかかわらず、暗黙的に接続がenvoy経由になり、50:50で backend3にも繋がるようになります。
% curl localhost:8083/api2/hello
{"message":"fom-backend2"}
% curl localhost:8083/api2/hello
{"message":"fom-backend3"}
% curl localhost:8083/api2/hello
{"message":"fom-backend3"}
% curl localhost:8083/api2/hello
{"message":"fom-backend2"}
サービスメッシュのサンプル2-外部認証リクエスト(ExtAuthz)
前述のCiliumEnvoyConfigリソースのサンプルを見て、わかる人にはわかると思いますがリソースの記述内容は、ほとんどEnvoyのListenerとClusterの設定そのままです。
とはいえ、CiliumEnvoyConfig の説明 をみると、
記載が可能なフィルターの内容はある程度限定されています。
Istioでは可能なアクセスログ出力,JWT検証, Fault Injectionなどは現時点では設定できないようです。
ですが、外部リクエスト認証を行うための ext_authzフィルターは設定可能なようなので、これを使用して 特定のリクエストヘッダがなければアクセスを拒否するように設定してみます。
外部リクエスト認証を行うサービスとして、Istioの認証サンプル を使用します。
これは リクエストヘッダに x-ext-authz: allow という値があるかどうかをチェックするものです。
このサンプルをext-authz Podとして デプロイし、次のCiliumEnvoyConfigリソース を適用します。
apiVersion: cilium.io/v2
kind: CiliumEnvoyConfig
metadata:
name: envoy-front-authz-listener
spec:
#front podへの接続を envoyでプロキシする
services:
- name: front
namespace: default
# 接続をproxyしないが、envoyから接続するサービスは backendServiceとして記述する
backendServices:
- name: ext-authz
namespace: default
number: ["8000", "9000"]
resources:
- "@type": type.googleapis.com/envoy.config.listener.v3.Listener
name: envoy-front-authz-listener
filter_chains:
- filters:
- name: envoy.filters.network.http_connection_manager
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.network.http_connection_manager.v3.HttpConnectionManager
stat_prefix: envoy-front-authz-listener
rds:
route_config_name: front_lb_route
http_filters:
# ext_authzフィルターを追加。 全てのリクエストを ext_authz podへ転送して認証チェック
- name: envoy.filters.http.ext_authz
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.http.ext_authz.v3.ExtAuthz
stat_prefix: ext_authz
transport_api_version: V3
http_service:
server_uri:
uri: "http://ext-authz.default.svc.cluster.local:8000"
cluster: "default/ext-authz:8000"
timeout: 1s
path_prefix: /
authorization_request:
allowed_headers:
patterns:
- contains: authz
failure_mode_allow: false
include_peer_certificate: true
- name: envoy.filters.http.router
- "@type": type.googleapis.com/envoy.config.route.v3.RouteConfiguration
name: front_lb_route
virtual_hosts:
- name: "front_lb_route"
domains: [ "*" ]
routes:
- match:
prefix: "/"
route:
cluster: "default/front"
- "@type": type.googleapis.com/envoy.config.cluster.v3.Cluster
name: "default/front"
connect_timeout: 5s
lb_policy: ROUND_ROBIN
type: EDS
outlier_detection:
split_external_local_origin_errors: true
consecutive_local_origin_failure: 2
- "@type": type.googleapis.com/envoy.config.cluster.v3.Cluster
name: "default/ext-authz:8000"
connect_timeout: 3s
lb_policy: ROUND_ROBIN
type: EDS
outlier_detection:
split_external_local_origin_errors: true
consecutive_local_origin_failure: 2
- "@type": type.googleapis.com/envoy.config.cluster.v3.Cluster
name: "default/ext-authz:9000"
connect_timeout: 3s
lb_policy: ROUND_ROBIN
type: EDS
typed_extension_protocol_options:
envoy.extensions.upstreams.http.v3.HttpProtocolOptions:
"@type": type.googleapis.com/envoy.extensions.upstreams.http.v3.HttpProtocolOptions
explicit_http_config:
http2_protocol_options: {}
outlier_detection:
split_external_local_origin_errors: true
consecutive_local_origin_failure: 2
front Podへの接続について、ext_authzフィルタを適用して認証チェックを追加します。 ここでのポイントは Envoyでプロキシはしないが、envoyから接続するバックエンドのサービスを backendServices に記載することです。 現時点ではbackendServicesについてはドキュメント化されておらず、ソースを見てやっとその存在がわかりました。
次のように front Podへの通信はまず ext_authz Podへ流れ、そこでOKだと backendへ、NGだと 403ステータスコードがクライアントへ返ります。

リクエストヘッダなしのリクエストは拒否されるようになります。
# curl http://front/api/hello -i
HTTP/1.1 403 Forbidden
x-ext-authz-additional-header-override:
x-ext-authz-check-received: GET front/api/hello, headers: map[Content-Length:[0] X-Envoy-Expected-Rq-Timeout-Ms:[3600000] X-Envoy-Internal:[true] X-Forwarded-For:[172.17.0.1] X-Forwarded-Proto:[http] X-Request-Id:[3200cb72-9786-49d6-a5b5-102907202116]], body: []
x-ext-authz-check-result: denied
date: Mon, 29 Aug 2022 11:51:54 GMT
content-length: 76
content-type: text/plain; charset=utf-8
x-envoy-upstream-service-time: 3
server: envoy
denied by ext_authz for not found header `x-ext-authz: allow` in the request
認証が通るリクエストヘッダ付きのリクエストはOKになります。
# curl http://front/api/hello -i -H "x-ext-authz: allow"
HTTP/1.1 200 OK
server: envoy
date: Mon, 29 Aug 2022 11:53:57 GMT
content-type: text/plain
content-length: 19
x-envoy-upstream-service-time: 2
{"message":"hello"}
これで、sidecar free service meshの機能の一部を試すことができました。
まとめ
Ciliumの機能をある程度試すことができました。 Istioなどサイドカー型のサービスメッシュはL4より上のレイヤでサイドカーによって通信をコントロールすることでサービスメッシュを構成するのに対し、 CiliumはeBPFによりセキュアなネットワークを導入することで結果としてシンプルなサービスメッシュを実現しているという印象を受けました。
Ciliumは他にも色々な機能があります。以下は興味はあるものの時間の都合上試せなかったものです。
- OpenTelemetry Integration
- gRPCの複数Podの分散
- Multi Cluster
- mTLS(参考のブログ記事 )
個人的な感想では、相当の魅力があるものの現時点ではプロダクトへの導入は以下の内容から、様子を見たいという感じです。
- Podレベルのメトリクスがサイドカーなしで取得できるのは非常に良い、というよりもびっくりした。
- Datadogなど、外部の監視サービスのサポート状況を注視したい。
- Istioでパフォーマンス的に困っていない。
- サービスメッシュの機能としてはIstioの方が揃っている
- アクセスログの取得は現時点でも使用しているが Ciliumにはない
- Istioの通信機能 と比較すると、FaultInjectionやCircuit Breaker,JWT検証などは現時点ではCiliumでは使用できないか工夫が必要
- CiliumEnvoyConfig リソースの書き方があまりにもEnvoyに寄りすぎていて、Envoyの知識が必須になっている
とはいえ 2,3年後にはこの状況が変わっていてもおかしくないのではと期待できるプロダクトであることは間違いないです。 これからもCiliumのアップデートには注目していきたいと思います。 また、Ciliumが流行ったとしてもEnvoyはそのまま使われていくと思います。サービスメッシュの主要コンポーネントやプロキシサーバーとしてEnvoyは至るところで使われています。みなさんEnvoy力を鍛えましょう。
ここまでお読みいただきありがとうございました。
CADDiでは、現在積極的に採用を行っています。 まずはカジュアルにお話を聞いてみたい!という方は、ぜひこちらより面談をお申し込みください。 また、Tech Blogや勉強会等のイベントについてはSNSで随時発信しておりますので、Twitterのフォローや、connpassのメンバー登録をぜひよろしくお願いします。