こんにちは、 Drawer Growth グループの高藤です。先日、弊社の江良が活用事例として取り上げた Apache Iceberg の活用事例にあるよう、キャディでは Apache Iceberg を採用したデータレイクハウスの構築を行っています。前回に引き続き今後計画していることについて紹介したいと思います。
先日の江良がまとめた活用事例にもある通り、現在構築しているデータレイクハウスでは、お客様が手元にある構造化データに対して、お客様自身でデータをアップロードし CADDi Drawer 内で利用できるようにしています。データレイクハウスを通じて、お客様固有のデータを CADDi Drawer 内で大量に扱うことができるようになりました。
その一方で、まだまだ解決しないといけない課題もあります。前述の記事のなかでも触れられているとおり、「全社を横断したプラットフォーム」への取り組みも必要になっています。
現在のデータレイクハウスは、お客様が手動でアップロードしたデータのみを扱っている状態です。しかし、CADDi Drawerのサービス内では、日々大量のデータが生成・更新されています。図面解析結果、受発注実績や見積りなどの業務プロセスデータなど、これらの貴重なデータはまだデータレイクハウスには統合されていません。
これらのデータが統合されていない主な理由は、CADDi Drawerのシステムアーキテクチャにあります。私たちのサービスは、複数のマイクロサービスやコンポーネントから構成されており、それぞれが独立したデータベースに情報を永続化しています。この分散アーキテクチャは柔軟性と拡張性を提供する一方で、統合的なデータ分析を難しくしています。
このような背景から、私たちは現在、これらの分散データを効率的にデータレイクハウスへ統合する方法を検討しています。その有力な解決策として、Change Data Capture (CDC) の導入を計画しています。CDCは各データベースの変更を継続的に捕捉し、それをデータレイクハウスへ伝播させる仕組みを提供します。
本記事では、Apache Iceberg ベースのデータレイクハウスに対して、CDC を用いたデータ統合アプローチを調査し、現在検討にあげている実装案を共有します。これは実装前の調査・計画段階の内容ですが、同様の課題に取り組む方々や、興味がある方にとって参考になれば幸いです。
統合すべきデータとその課題
冒頭で触れたように、CADDi Drawer内部で生成・更新される様々なデータをデータレイクハウスに統合する必要があります。ここではそれらのデータ特性と統合における課題を簡潔にまとめます。
様々なデータを統一的なデータ基盤上で分析できるようにするには、データレイクハウスに統合する必要があるのは、先日の江良がまとめた活用事例にもある通りです。 現在のデータレイクハウスでは、お客様がアップロードした構造化データを扱っていますが、サービス内で生成・更新されるデータはまだ統合されていません。これは、システムが複数のコンポーネントから構成され、それぞれが独立したデータベースに情報を永続化しているためです。
この分散アーキテクチャは開発の柔軟性と拡張性を提供する一方で、データの横断的な活用を難しくしています。そこで我々は、既存のデータベース構造を維持しながら、データレイクハウスを通じた統合的な活用基盤の構築を目指しています。
このような統合環境を実現するためには、各サービスのデータ更新を継続的かつ効率的にデータレイクハウスに反映する仕組みが必要です。そこで、Change Data Capture(CDC)技術の導入を検討しています。
CDCを活用したデータ統合アプローチ
前章で述べた課題を解決し、既存のデータベースを維持しながらデータレイクハウスでの横断的活用を実現するため、Change Data Capture(CDC)の採用を検討しています。
Change Data Capture (CDC)の基本概念
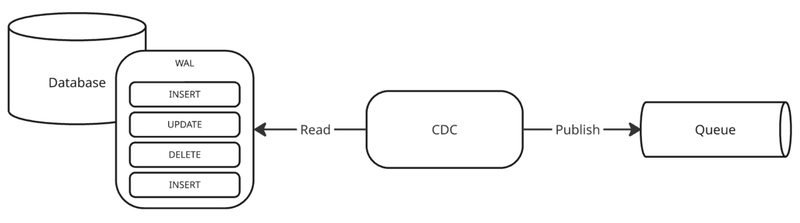
CDCとは、データベース内の変更をリアルタイムで検出し、その変更情報を他のシステムに伝播させる技術です。従来のバッチ処理による全量転送と異なり、「変更があったデータのみ」を効率的に転送します。
「変更があったデータ」とはデータベースに適用された(INSERT/UPDATE/DELETE)を補足し、変更前後の値とメタデータ(テーブルスキーマなどの情報)のことを指します。
(ボヤキ) 以前携わったシステムではこのような仕組みをデータベースのトリガーを利用して行ったりしていました。後述するように現在では様々なアプリケーションやクラウドサービスが用意されているため、このような仕組みを簡単にできるのは素敵だなと思っています。
データレイクハウスへのCDC適用のメリット
リアルタイム性の向上
CDC により、データ変更をほぼリアルタイムでデータレイクハウスに反映できます。このため、最新データに基づく分析結果の提供をデータレイクハウスにて実現することが可能です。
今回検討している CDC はデータベースのトランザクションログを読み取り、変更を抽出する構成を考えています。このため定期的なバッチ処理などによるデータ連携と比較しリアルタイムに近い状態での検知が可能です。
しかしながら今回データの反映先が Apache Iceberg となるため、データベースの1レコードごとに変更を伝搬してしまうと Iceberg の特性上、大量のファイルが作成されてしまい、パフォーマンス劣化などを招く恐れがあるため、注意して設計する必要があります。
分散システム間のデータ整合性確保
今回採用を検討している CDC はデータベースのトランザクションログを元にデータ変更を検知します。つまり、データベースの変更がコミットされたもののみを変更として検出することができます。これはバッチ処理などによるデータ連携など他の手法に比べて確定したデータを確実に伝搬させることができます。
また、CDC ではデータの変更だけでなく、テーブルスキーマの変更についても検知することができます。CDC でデータ変更を検知した時に伝搬するデータにスキーマの情報が含まれています。これにより、変更の受け手側でスキーマ変更に伴う処理を行うことができます。
この特性は Apache Iceberg のスキーマ進化 (Schema Evolution) と相性が良く、データ元となるサービス側でのテーブルスキーマ変更を柔軟に扱うことができます。
CDCツールと構成案
現在検討の候補としている構成です。スケーラビリティや耐障害性など非機能要件についての検証も行わないといけない状態です。近い将来、機能/非機能要件の検証を行った上で、最終的な構成の決定を行う予定です。
大きく分けて Google Cloud のマネージドサービスである Datastream または Debezium での構成を検討しています。
Google Cloud Datastream + Google Cloud Dataflow
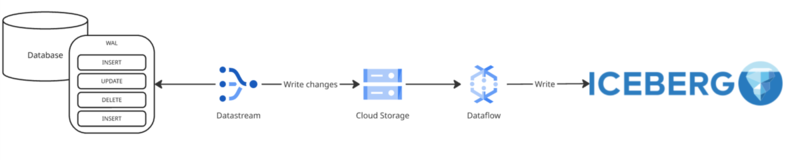
マネージドサービスである Datastream を採用した案です。 実は CADDi では BigQuery にデータを転送する手段としてすでに利用しているため、ある程度の実績がある状態です。
しかし、転送先が BigQuery の場合はかなり簡易な設定で利用することができる反面、BigQuery以外への転送手段は Google Cloud Storage (GCS) のみに限られてしまうため、 Apache Iceberg への書き込みには GCS に格納されたファイルを読み取り、データレイクハウスへ書き込む処理を用意する必要があります。
GCS からデータレイクハウスへの書き込みは、独自にアプリケーションの開発を行うか、Dataflow (Apache beam) を利用することを検討しています。
Pros
- 他案と比較し、マネージドサービスを利用するため可用性の向上を見込める
Cons
- 独自開発、Dataflowの場合もデータ元のスキーマ変更に対する対応が他案に対して多くの工数が必要になる
Debezium server iceberg

CDC として有名な Debezium を 採用した案です。Debezium には Kafka Connect 上に実装された Debezium Connect と Kafka 不要でスタンドアロンアプリとして実行可能な Debezium Server が存在します。
この案では後者の Debezium Server で Apache Iceberg への書き込みに対応した debezium-server-icebergを採用します。
Pros
- Debezium Server 単体での構成となるためシンプルな構成となる
- Apache Iceberg への書き込みもサポートされているため、独自に処理を追加する必要がない
Cons
- 大規模環境での利用には検証が必要
- 水平スケールの可否
- 障害発生時の復旧などに不明点
Debezium (Kafka connect) + iceberg-kafka-connect

前述と同様に Debezium を採用した案です。こちらは Kafka Connect 上で Debezium connect を用意し、 Apache Kafka とともに構成する案です。 この場合、 Apache Iceberg への書き込みは Debezium connect と同様に Kafka connect 上に iceberg-kafka-connectを用意し書き込みを行います。
Pros
- Apache Kafka, ならびに Kafka Connect を利用することでエコシステム上にある様々な source, sink コネクタの利用が可能
- Kafka Connect の水平スケールが可能であるため大量の CDC イベントの処理が可能
- Kafka を利用して変更イベントの永続化が行われるため耐障害性が向上できる
Cons
- Apache Kafka の導入が必要になる
- CADDi ではメッセージ基盤として Cloud Pub/Sub を利用してきているため、 Apache Kafka への運用ノウハウが乏しい
- iceberg-kafka-connect の状況が不明
- Apache/Iceberg 本体への取り込みが始まっている
- 設定がかなり煩雑で学習コストが高い
- Kafka Connect への理解が前提知識として必要になる
詳細まで落とし込めておらず恐縮ですが、この様にいくつかの構成案を元に今後の検証を進めていく予定です。
最後に
いかがでしたでしょうか? 最終的に CADDi が選択する構成まで言及することができず中途半端な内容となってしまいましたが、何かの参考にしていただければと思います。
最後にお決まりの宣伝を書かせてもらいます。キャディではエンジニアを採用しています。本記事を読んで、「製造業の AI データプラットフォーム」構想に興味を持った方、今後の課題を一緒に解決していきたいと感じた方はぜひご連絡ください。
(Apache Iceberg などデータレイクハウスに興味がある!とても詳しいという方いらっしゃればぜひカジュアル面談でも良いので声を掛けていただければと)