こんにちは。Drawer Growth グループの江良です。
キャディが「製造業 AI データプラットフォーム」の構想を打ち出してから半年ほどが経ちました。
このコンセプトの実現にあたっては、「AI」の部分だけでなく、「データ」の部分を支える仕組みづくりも重要になってきます。今回は、私が携わっているプロジェクトで導入した Apache Iceberg とその使いどころについて紹介したいと思います。
製造業におけるデータ活用の難しさ
本題に入る前に、まずは背景について少し補足します。
(Iceberg の話だけを読みたい人は「採用したアーキテクチャ」のところまでスキップしてください。)
モノづくり産業における会社には多種多様なデータが存在する
製造業の世界で登場するデータにはさまざまなものがあります。
詳しくは キャディ、製造業AIデータプラットフォームとしての、第二章。|加藤/キャディCEO でも紹介されていますが、具体例を挙げると以下の通りです。
| 分類 | 具体例 |
|---|---|
| 構造化データ | ・実績データ(見積実績、受注実績、発注実績、製造実績、検査実績、出荷実績、請求実績、在庫実績など) ・マスタデータ(顧客情報、製品、仕入れ先、工程、設備情報、検査器具、チャージなど) |
| 半構造化データ | ・CAD |
| 非構造化データ | ・図面 ・写真 ・文書(仕様書、不具合報告書、議事録など) |
(会社の規模にもよりますが)少なくとも十数種類 〜 百数種類のデータが企業内に存在することがイメージできるかなと思います。
当然ながら、それぞれのデータのスキーマは異なります。データのサイズや更新頻度も様々です。実績データに関しては、一億件近くの規模のデータが存在するケースもあります。
データのフォーマットは会社ごとに異なる
図面は、書き手の意図を確実に読み手に伝達するため、JIS 規格に基づいて標準化されています。一方で、表題欄と呼ばれる図面のメタデータ(図面番号、尺度、部品名称、設計者名、承認者名、使用する材質など)を記載する欄の様式は各社が自由に設定できます。
CAD に関しても、どのソフトウェアを使用しているかは各社でバラバラです。
実績データやマスタデータの管理方法は当然各社で異なります。PLM/PDM や ERP といったソフトウェアで管理されていることが多いですが、製造業全体で「標準」と言えるような規格はありません。
データの「活用」に向けたハードル
こういった多種多様なデータを活用するためには、まず、非構造化データや半構造化データをなんらかの方法で構造化する必要があります。その上で、データ同士をなんらかの方法で紐づけて、データ同士の連関がわかるようにする必要があります。
データのフォーマットは会社ごとに異なり、さまざまなバリエーションがあります。そのため、「データ同士がどうすれば紐づくか」も一意には決まりません。
ここまでの話をまとめると、
- さまざまなスキーマのデータを柔軟に取り扱うことができ、
- データ同士をどのカラムで紐づけるべきかを柔軟に選択でき、
- 大規模なデータセットを取り扱える
こういった要件を満たすことが、製造業におけるデータの「活用」を実現する上では求められます(製造業に限った話ではないかもしれませんが)。
データを活用するための一般的な解決策
さて、ここまで説明してきたような課題を解決するためにはどうすればいいでしょうか?一般的には、データエンジニアリングによるアプローチが考えられるかなと思います。
三行くらいで簡単にまとめるとこんな感じ。
- データエンジニアリングを専門とするチームを組成し、
- データレイクに生データを集め、
- ETL パイプライン等を通じてデータを活用可能にする
Snowflake 等の登場により、企業がデータ分析を始める際のハードルは大きく下がってきている印象があります。しかしながら、こうしたことを実現するためには、依然としてデータエンジニアリングを専門とするエンジニアが手を動かす必要があります。
改めて、先ほどまとめた課題を再掲します。
- さまざまなスキーマのデータを柔軟に取り扱うことができ、
- データ同士をどのカラムで紐づけるべきかを柔軟に選択でき、
- 大規模なデータセットを取り扱える
- (加えて、製造業に特有のユースケースに特化した機能を提供できる)
上記のような機能を SaaS として提供することで、データをよりかんたんに活用できる状態にしたい、そのための方法を考えてほしい、というのが、ぼくの所属するチームのここ半年のミッションでした。
データレイクハウスの登場
先ほど、データを活用するための一般的な解決策としてデータレイクについて触れました。大規模なデータセットを活用していく上で、データレイクのアーキテクチャは有効ですが、一方で課題もあります。
代表的な課題としては、データの一貫性に関する課題があります。データはあくまで GCS 等のストレージに配置されているだけの状態にあるため、RDBMS でいうところのトランザクションのような概念はありません。そのため、複数のプロセスから同時に書き込みをするとデータが壊れてしまう可能がありますし、中途半端に書き込みがされた状態のデータが予期せず参照されてしまう可能性もあります。
こうした課題から、近年、データレイクハウスと呼ばれるアーキテクチャが注目されてきています。
データレイクハウスアーキテクチャは、データを保存するストレージのレイヤと、データに対して SQL を実行するクエリのレイヤを分離し、その間にメタデータのレイヤを設けているのが大きな特徴です。メタデータのレイヤを設けることで、ストレージ上のデータをテーブルであるかのように抽象化したり、ACID トランザクションを実現したりすることができます。
それぞれのレイヤで採用できる代表的なツールは以下の通りです。

メタデータのレイヤでは、Open Table Format と呼ばれる仕様に従ってデータが管理されます。この仕様に従ってデータを保存することで、トランザクションなどの便利な機能が使えるほか、クエリのレイヤでどのツールを使うか(Spark、Hive、Flink、Trino など)がユースケースに応じて選択可能になります。
採用したアーキテクチャ
前置きが長くなりました。キャディでの Iceberg の使いどころについての話に移ります。
キャディでは、CADDi Drawer が扱うデータのうち、構造化データを扱うサービスにて Iceberg を使用しています。構造化データのうち、特に実績にまつわるデータはレコード件数が多い傾向にあります。スキーマが不定だったり、紐付け項目が一意に定まらなかったりするという特徴も相まって、RDBMS を素朴に利用してアプリケーションを設計すると、中長期的に期待するパフォーマンスが出せないのではないか、という懸念がありました。
一方で、データの更新頻度は少なく、データの追加操作がメインのユースケースであることから、「RDBMS 以外の選択肢は本当にないのか?」を検討し、紆余曲折を経て Iceberg に辿り着きました。
各レイヤで何を採用したか
先ほど、データレイクハウスアーキテクチャはクエリ、メタデータ、ストレージの 3 つのレイヤで構成される、ということについて説明しました。それぞれのレイヤで採用できるツールにはいくつか選択肢がありますが、CADDi Drawer では Trino、Iceberg、GCS(Google Cloud Storage)を採用しました。

Open Table Format が掲げるテーマとして代表的なものに「バッチとストリーミングの統合」があります。ストリーミングのユースケースを満たすなら、Apache Spark を採用し、Structured Streaming 機能を活用するといった選択肢も考えられます。
ですが、SQL のインタフェースを通じてデータをクエリできれば十分であり、検討時点ではストリーミングのユースケースが見当たらなかったため、比較的導入コストの小さい Trino を採用しています。(リリースまでのスケジュールが非常にタイトであったこと、今回ユーザに提供する機能はあくまでベータ版であったこと、といった事情もあったりします。)
Iceberg に関しては AWS など BigTech 各社が力を入れていることから興味を持ち、採用を決めました。
データレイヤーに関しては、キャディでは Google Cloud を全面的に採用していることから GCS を採用することに決めました。
「ベータ版としての提供なのであれば BigQuery でもいいのでは…?」という考えも頭をよぎりましたが、不特定多数のユーザーに BigQuery を用いた機能を解放するとクエリコストのコントロールが難しくなりそうなため、候補からは外しました。
アーキテクチャの詳細
アーキテクチャ図は以下の通りです。
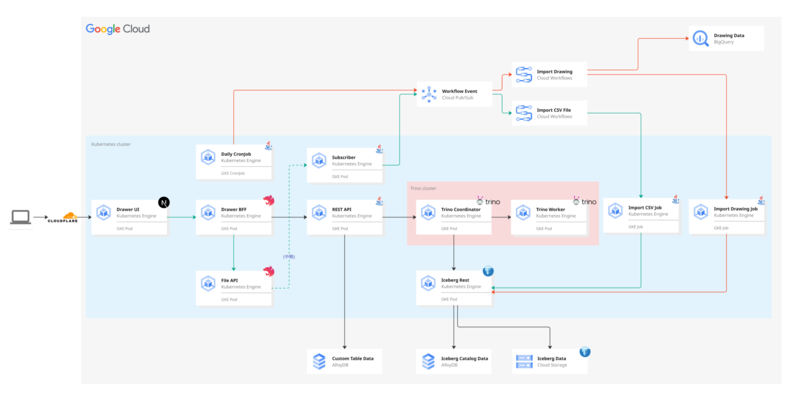
構造化データを扱うマイクロサービスは、キャディの中では珍しく Java を採用しています。静的型付けのある言語で開発したかったのと、Trino や Iceberg などのライブラリとの親和性の高さから採用を決めています。
処理の大まかな流れは以下の通りです。
- ユーザがアップロードした CSV をパースして Iceberg に保存する
- 図面の解析結果を一定間隔のバッチで受け取り Iceberg に保存する
- Iceberg のデータを用いてデータの紐付けを解決し、「図面に紐づく構造化データ」を UI に表示できるようにする
緑色の線が「ユーザが CSV をアップロードしてから Iceberg に登録されるまで」の流れを表し、赤色の線が「図面の解析結果が Iceberg に登録されるまで」の流れを表しています。別のジョブを通じてデータ同士の紐付けを解決して Iceberg に書き戻し、この「解決済み」のデータを REST API から返却して、ユーザ向けの画面に表示しています。
Trino は GKE クラスタ上に用意した専用のノードにデプロイして稼働させています。コーディネータがクエリを受信し、実行計画を立てて、ワーカに対して指示を送ります。ワーカはコーディネータからタスクを受け取り、データを実際に処理します。
Iceberg Catalog としては Databricks 社の iceberg-rest-image を利用しており、こちらも GKE クラスタ上にデプロイして稼働させています。カタログの情報は AlloyDB に永続化し、ファイルの実態は GCS に保存しています。
Iceberg Catalog にも選択肢がいくつかあります。詳しく知りたい方は下記の記事を参照ください。
大量のデータの INSERT 操作は、パフォーマンスの観点から Iceberg Java API を通じて実施しています。
所感
Iceberg および Trino を採用したことにより、
- テナントごとに異なる、さまざまなスキーマのデータを柔軟に取り扱うことができる
- データ同士をどのカラムで紐づけるべきかを柔軟に選択できる
- 大規模なデータセットを取り扱える
といった、当初目的としていたアーキテクチャ特性を満たすサービスを構築できました。
データの書き込み性能のスループットに関しては、1000 万件規模のデータの登録が 15min 程度で完了し、読み込み性能に関しても一般的な Web アプリケーションとして違和感のないレスポンスタイムで安定して結果を返すことを確認できました。
今後の課題
ここまで、Iceberg 導入の背景と使いどころについて説明してきました。
直近のゴールは達成できたものの、今後取り組みたいこと、改善したいポイントはたくさんあります。
全社を横断したプラットフォームへの進化
Iceberg を使った仕組みは、現在、あくまで CADDi Drawer の中の一機能という立ち位置です。将来的には CADDi Drawer のデータだけではなくCADDi Quote のデータも横断して取り扱えるよう、アプリケーションとプラットフォームに分割し、アプリケーションを横断して利用できるようにしていく必要があります。
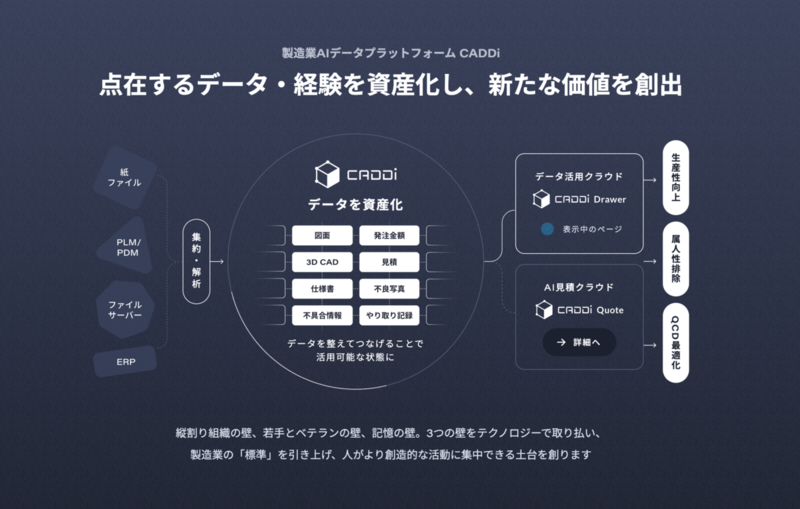
また、こちらのインタビューでも語られている通り、製造業 AI データプラットフォーム CADDi には、今後も新規アプリケーションを追加していくことを想定しています。
「3 年で数十個」 という目標を達成する上で、Iceberg を使った基盤を全社を横断したプラットフォームに進化させていく取り組みは急務といえます。
Iceberg の機能をもっと使い倒したい
Iceberg にはトランザクション管理に関する仕様が定義されています。この仕様に従って実装されたクエリエンジンを利用することで、更新データの競合が疑われる場合に該当の操作を abort し、データの一貫性を保証することができます。
現時点ではデータの追記(AppendFiles)しか利用していないため、下記の資料で解説されているような同時書き込み時における課題には直面していません。
また、Iceberg には in-place table evolution という仕様が定義されています。これはテーブルのスキーマを ALTER TABLE 文を発行して変更したり、テーブルのパーティションを行うキーを後から変更したりすることができる、という機能です。
現時点では、一度定義したテーブルのスキーマを変更するような機能を提供していないため、この課題には直面していませんが、早晩対応が必要になりそうな予感がしています。
また、Iceberg を全社を横断したプラットフォームに進化させていく上では、各アプリケーションのデータベースに永続化されているデータを、ストリーミング処理を通じてニアリアルタイムに連携できるようにしていく必要も出てきそうです。
やることがたくさんあって大変なわけですが、これはこれで「Iceberg の真価を発揮できるチャンスがたくさんある」と言い換えることもできそうです。
マルチテナント SaaS におけるテナント分離の課題
書籍『マルチテナント SaaS アーキテクチャの構築』でも語られている通り、SaaS を提供する事業者としては、異なるテナントのデータが誤って参照されてしまうことのないよう、テナントの分離を強制する仕組みの構築が重要となります。
CADDi Drawer では、Iceberg のスキーマをテナントごとに作成し、テナントごとのテーブルをスキーマ内に作成することでデータを物理的に分離しています。異なるテナントのデータを参照できないようにする仕組みはアプリケーションのレイヤに実装しています。
こういった仕組みはアプリケーションのレイヤだけでなく、インフラのレイヤにも導入し、多層的なテナント分離を実現したいところです。ですが、現在採用している Iceberg Catalog にはそういったアクセスコントロールに関する機能はないため、やむなく断念しています。
Apache Polaris では、RBAC モデルをベースとした柔軟なアクセスコントロールの仕組みが提供されるようです。現時点では Incubation のステータスにあるため採用を見送ったのですが、正式版がリリースされた際には載せ替えを検討しています。
Iceberg の利用を検討している方は動向をウォッチしてみると良いかもしれません。
おわりに
いかがだったでしょうか。
Iceberg の採用を検討している方の参考になれば幸いです。
最後に宣伝で、キャディではエンジニアを採用しています。本記事を読んで、「製造業の AI データプラットフォーム」構想に興味を持った方、今後の課題を一緒に解決していきたいと感じた方はぜひご連絡ください。