※本記事は、技術評論社「Software Design」(2023年6月号)に寄稿した連載記事「Google Cloudで実践するSREプラクティス」からの転載です。発行元からの許可を得て掲載しております。
はじめに
前回はIaCの考え方や必要性と、筆者らが採用しているTerraformの特徴について紹介しました。今回は今後紹介するプラクティスの前提となるTerraformに触れたことのない方のために、その基本を簡単に紹介します1。 ここで紹介できない事項やTerraformのインストール方法については、HashiCorp 社やGoogleCloudのチュートリアル2を参考にしてください。ぜひそちらも併せてご覧ください。
Terraformの基本コンセプト
Terraformの基本コンセプトは図1のようになっています。
▼図1 Terraformのコンセプト
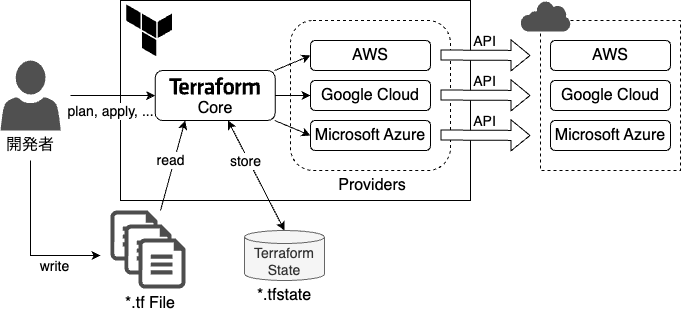
コードとして表現するインフラの状態は、Terraform Languageと呼ばれる独自の設定言語で記述し、拡張子*.tf のファイルとして保存します。
なおドキュメント3によると、「Terraform Language は、HCL(HashCorp Configuration Language)と呼ばれるHashiCorp社の独自の言語がベースになっている」と説明されています。
しかし、Terraformの設定言語を一般化してHashiCorp社のほかの製品でも使えるようにしたものがHCLですので、「Terraform Language≒HCL」ととらえても差し支えはないでしょう。
Terraformの実体は単一のバイナリファイルで、terraform plan、terraform applyなどのさまざまな機能がサブコマンドとして提供されています。前回も触れたように、クラウドサービスごとの処理はプロバイダ(Provider)と呼ばれるプラグインに分離されています。どのプロバイダを利用するかは、tfファイル内に記述します4。
Terraformがtfファイルの記述に従ってプロバイダを自動ダウンロードするので、利用者がプロバイダのインストールを意識する必要はありません。
ステート
Terraformを理解するうえで重要なのが、ステート(State)です。tfファイルには、Terraformで管理したいクラウドサービス上のリソースたとえばVPC(Virtual Private Cloud)やVM(Virtual Machine)インスタンスなどを記述します。これらリソースの実際の状態と、tfファイル上の記述との対応を保持しているのがステートです。
ステートの実体は*.tfstateという拡張子のJSONファイルで、Terraformが処理を実行するたびに更新されます。本連載では、このファイルを「tfstateファイル」と呼びます。
バックエンド
Terraformにおけるバックエンドとは、tfstateファイルの保存先のことです。バックエンドを切り替えることで、さまざまな方法でtfstateファイルを管理できます。
デフォルトのバックエンドはlocalで、tfstateファイルをローカルストレージに保存します。
Terraformの学習時や個人で使用するときは、これで十分でしょう。
チームでインフラを管理するときは、tfstateファイルを共有しなければなりません。このためgcs やs3といったバックエンド5を使って、オブジェクトストレージ上に配置することが一般的です。筆者らもgcsバックエンドを使ってGCS(Google Cloud Storage)のバケット上でtfstateファイルを管理しています。
Terraform Languageの基本
ブロック
Terraform Languageでは、クラウド上のリソースをブロックと呼ばれる固まりで記述します。ブロックの文法はリスト1のようになっています。たとえば、Google Cloud上でmy-networkという名前のVPCネットワークを作成するにはリスト2のように記述します。
▼リスト1 ブロックの文法
resource "google_compute_network" "my_network" {
name = "my-network"
}
▼リスト2 my-networkというVPCネットワークを作成
resource "google_compute_network" "my_network" {
name = "my-network"
}
ブロックタイプには、表1に示すようなものがあります。 今回は、主要なブロックタイプについてTerraformの使い方の流れに沿って紹介します6。
▼表1 おもなブロックタイプ
| ブロックタイプ | 説明 |
|---|---|
| provider | プロバイダの設定を記述する |
| resource | クラウドサービス上のリソースを定義する |
| locals | リソース内で使用する変数を定義する |
| variable | 外部から設定可能な変数を定義する |
| output | リソースやモジュールの出力を定義する |
| module | 他のモジュールの読み込みを指示する |
| data | Terraformが管理しないリソースの参照を定義する |
resource ブロック
resourceブロックはTerraformの主役とも言えるブロックで、クラウド上のリソース定義を表します。resourceブロックでは2つのブロックラベルを指定し、1つめがリソースの種類(リソースタイプ)、2つめがTerraform内でのリソースの識別名を表します。リソースタイプは、プロバイダによってあらかじめ定義されているもので、プロバイダのドキュメントに記載されています7。
リスト3の例は、GoogleCloudのプロバイダが提供するgoogle_compute_networkというリソースを使ってVPCネットワークを定義しています。
▼リスト3 google_compute_networkを使ってVPCネットワークを定義
resource "google_compute_network" "vpc_network" {
name = "terraform-network"
}
vpc_network がTerraform上の識別名で、互いのリソースを参照するときなどはこの名前を使用します。識別名は開発者が自由に決めてかまいません。
ブロック内の引数は、プロバイダが提供するリソースの仕様にしたがって指定します。google_compute_networkでは、nameが必須となっており、これでGoogle Cloud上における実際のVPCの名前を指定します。
ドキュメント8を参照するとほかにもオプショナルな引数があり、たとえばルーティング・モードや、MTUといったパラメータも指定できることがわかります。
TerraformによるIaCの流れ
Terraformを利用するときの流れは図2のとおりです。initなどはそれぞれTerraformコマンドのサブコマンドで、terraform initのように実行します。
▼図2 Terraform利用の流れ

ここからは、簡単なサンプルを使って操作の流れを説明しましょう。 ここで作成するインフラ構成を図3に示します。Google CloudのVPC(Virtual Private Cloud)の中にサブネットを1つ作成するというものです。
▼図3 サンプルのインフラ構成

まずサンプルコードの内容を解説してから、Terraform実行の流れを説明します。
サンプルコードの解説
図3のインフラを構築するTerraformのコード(main.tf9)をリスト4に示します。
▼リスト4 main.tf
provider "google" { ❶
project = "<<プロジェクトID>>"
region = "asia-northeast1"
}
resource "google_compute_network" "my_network" { ❷
name = "my-network"
auto_create_subnetworks = false
}
resource "google_compute_subnetwork" "my_subnetwork" { ❸
name = "my-subnetwork"
ip_cidr_range = "10.2.0.0/16"
network = google_compute_network.my_network.id ❹
}
tfファイルの構成
リスト4は次の3つのブロックで構成されています。
- Google Providerへの指示を記述する provider ブロック (❶)
- VPCを作る resource ブロック (❷)
- サブネットを作る resource ブロック (❸)
❶のproviderブロックは、表1で紹介した7つのブロックタイプの1つで、プロバイダ共通の情報を定義しています。
たとえば、Google Cloudのプロバイダでは、Terraformの適用先プロジェクトIDなどを指定します。なお、手元で実行してみたい方は、プロジェクトID の部分をご自分のGoogleCloudのプロジェクトIDに変更してください。
リソース間の参照
リスト4❹では、ほかのリソースの属性を参照しています。たとえば、リスト4❸のサブネットワークは、❷で定義したVPC内に作成します。
google_compute_subnetworkリソースでは、network引数でサブネットの所属するVPCを指定します。VPCはリスト4❷のmy_networkリソースで定義しているので、これを参照します。
Terraformでは、リソースタイプ.識別子.リソースの属性という形式で参照できるのでgoogle_compute_network.my_network.idと記述しています。なお、ここでidという属性はmy_networkに記述されていませんが、これはプロバイダが内部で自動生成する属性です。
ブロックの記述順は自由
Terraform Languageは宣言的ですので、各ブロックの記述順は自由です。リスト4におけるVPCとサブネットのようにリソース間の依存関係がある場合、Terraformは依存関係を自動解析して適用順を決定します。
また、ここでは説明を割愛しますがdepends_on10で依存関係の明示もできます。
init
Terraformの初回実行時には、tfファイルのあるディレクトリ11上でterraform initを実行して初期化します。Terraformはtfファイルの内容をチェックし、必要なプロバイダやモジュールのダウンロード、バックエンドの初期化などを行います。
「モジュール」の詳細は今回割愛しますが、Terraformにおけるコードのカプセル化や再利用の単位です。関連するリソースをまとめてモジュール化し、variableやoutputブロックで入出を定義できます。自身のコードをモジュールで分割したり、インターネットに公開されたモジュールを利用したりできます。
なお、Google Cloudのプロバイダを使用する際 、Terraform は Application Default Credential(ADC)12を使って認証をするので、次のようにgcloudコマンドで事前にログインしておく必要があります。
$ gcloud auth application-default login
$ terraform init
TerraformがダウンロードしたProviderやモジュールは、ワーキングディレクトリの.terraform という隠しディレクトリに保存されます。
plan
Terraformを使ううえで最も重要なのがplanと次項で解説するapplyです。
planでは、applyでtfファイルの記述内容をターゲットに適用するときの実行計画を表示します。追加、変更、削除されるリソースや、具体的な変更内容が表示されるので、applyの実行時に、インフラが受ける影響を事前に確認できます。
リソース追加の例
具体例で確認してみましょう。たとえば、新規リソースを作成するときは、図4のように新しく作成される項目が +記号で示されます(図4は、先ほどのサンプルで新しいVPCが作られるときのplan出力例です)。
▼図4 新しいVPCが作られるときのplan出力例
Terraform will perform the following actions:
# google_compute_network.my_network will be created
+ resource "google_compute_network" "my_network" {
(…省略…)
+ name = "my-network"
+ project = (known after apply)
(…省略…)
Plan: 2 to add, 0 to change, 0 to destroy.
リソース変更の例
次に、一度作成したサブネットのオプションを変更するケースを考えます。main.tfにリスト5の❶の部分を追加してから、planを実行してみます(出力例は図5)。
▼図5 変更後のplan出力例
# google_compute_subnetwork.my_subnetwork will be updated in-place
~ resource "google_compute_subnetwork" "my_subnetwork" { ❶
id = "projects/xxxx/regions/asia-northeast1/subnetworks/my-subnetwork"
name = "my-subnetwork"
~ private_ip_google_access = false -> true ❷
# (11 unchanged attributes hidden)
}
Plan: 0 to add, 1 to change, 0 to destroy.
今回はすでに存在するリソース(my_subnetworkというサブネット)に対して変更が加わるため、2のように変更箇所~記号で示されます。
▼リスト5 main.tfへの追加部分
resource "google_compute_subnetwork" "my_subnetwork" {
name = "my-subnetwork"
(…省略…)
private_ip_google_access = true ❶
}
ここでの例示は割愛しますが、リソースの削除や作りなおしを伴う変更の場合も、同様にplanで表示されます。
また、planはクラウド上のリソースの状態とステートの比較も行います。このため、Terraform以外の手段でインフラの状態を変更した結果、ステートとの食い違いが発生したときも、planによって検知できます。
さらに、planはTerraformのコードをリファクタリングしたときや、プロバイダのバージョンを更新したときなど、既存のインフラに影響が出ないことを確認する手段としても重要です。
リファクタリングの内容によっては、クラウド上のリソースが一度削除されてから再作成されたり、プロバイダの仕様変更によって既存のリソースが影響を受けたりすることもあります。
このようなことでインフラに意図しない影響を与えないためにも、planによる差分チェックはとても重要です。
apply
applyは、tfファイルの記述に従って、クラウド上のリソースを実際に変更します。前述のplanを実行しなくてもapplyは可能ですが、運用中のシステムに対してapplyをかける前には、planによる影響のチェックがほぼ必須となるでしょう。キャディでは、GitHub上でPull requestが作られたときにplanを自動実行して差分を確認できるようにしています(次回詳しく紹介します)。
destroy
destroyは、Terraformが管理するすべてのリソースを実際のインフラから削除します。tfファイル上で一部のリソースを削除した場合はapplyで削除されますので、運用中のインフラに対してdestroyを使用することはほとんどありません。検証時や開発環境などで「Terraformから作成したリソースをすべて削除したい」といった場面で使用することがほとんどでしょう。
ステートの裏側
最後に、Terraformを利用するうえで注意すべきステートについて解説します。ステートはTerraformの特徴的な概念であり、実運用中のクラウドインフラをTerafformで管理する際には、そのしくみをしっかり理解しておく必要があります。そうしないと、apply時に予期せぬ影響を与える危険があり、インフラの安定性を損ねるリスクがあるためです。
冒頭でも説明したとおり、ステートはTerraformの管理対象リソースの状態を保持するJSON形式のファイルです。terraformコマンドには、ステートを参照する機能もあります。
たとえば、前述のmain.cfをapplyしたあとのステートを表示するには、state listコマンドを実行します13。
図6のようにmain.tfに記述した3つのリソースが表示されました。
▼図6 state listの実行結果
$ terraform state list
google_compute_instance.terraform_test
google_compute_network.my_network
google_compute_subnetwork.my_subnetwork
リソースの詳細を表示するには、state show
コマンドを実行します(図7)。出力を見ると、purposeなどtfファイルには書かれていない情報もありますね。これは、Terraformがクラウド上のリソースから読み取った状態です。
▼図7 satate showの実行結果
$ terraform state show google_compute_network.my_network
# google_compute_subnetwork.my_subnetwork:
resource "google_compute_subnetwork" "my_subnetwork" {
name = "my-subnetwork"
gateway_address = "10.2.0.1"
ip_cidr_range = "10.2.0.0/16"
purpose = "PRIVATE"
(…省略…)
}
importによるドリフトの調整
ここで、ステートを意識すべき運用の実例を紹介します。 何らかの原因で発生するtfファイルとステート、クラウド上のリソース実体にズレが発生してしまうことをドリフトと呼びます。たとえば、tfファイル上の変更がapplyされていない状態もドリフトですが、このようなケースはapplyで解消できます。
一方で、Terraformで自動解決できないドリフトもあり、これはステートを意識した手作業の修正が必要です。その一例を紹介しましょう。たとえば、何らかの事情でクラウド上のリソースを先に手作業で作成してしまい、後追いでTerraformで定義したいようなケースです(図8)。
▼図8 ドリフトの発生例
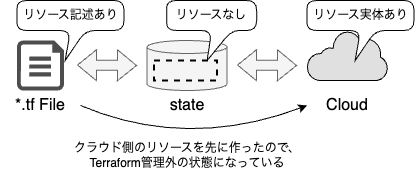
手作業で作ったリソースはTerraformの管理外であるため、このままapplyすると名前が衝突して作成できず、実体を削除しなければapplyできません。実体を削除せずに、コードと一致させるにはどうしたらよいでしょうか。
具体例で考えてみましょう。たとえば、図3とリスト4の状態に対して、手作業で新しいサブネットmy-subnetwork2を作成し、その後tfファイルにリスト6のような定義を追加したとします。
▼リスト6 新しいサブネット作成後にtfファイルへ追加
resource "google_compute_subnetwork" "my_subnetwork2" {
name = "my-subnetwork2"
ip_cidr_range = "10.3.0.0/16"
network = google_compute_network.my_network.id
}
この状態でplanを実行すると、createの差分が表示されます。tfファイル上のリソース記述はステートに反映されておらず、クラウド上に作成したサブネットはTerraform管理外であるためです(図8)。このままapplyすると、同じ名前のサブネットがすでに存在しているのでエラーになります(図9)。
▼図9 applyでエラーになった
google_compute_subnetwork.my_subnetwork2: Creating...
╷
│ Error: Error creating Subnetwork: googleapi: Error 409: The resource 'projects/xxxx/regions/asia-northeast1/subnetworks/my-subnetwork2' already exists, alreadyExists
(…省略…)
この状態を解消するために、terraform importコマンドを使用します。図10の例では、クラウド上のmy-subnetwork2の状態を、ステート上のgoogle_compute_subnetwork.my_subnetwork2として取りこみます。
▼図10 terraform importを実行
$ terraform import google_compute_subnetwork.my_subnetwork2 my-subnetwork2
これでtfファイル、ステート、実体がすべて一致するためplanを実行しても差分が発生しなくなります。手作業で作成したサブネットは、無事Terraformの管理下となりました。 Terraformには、これ以外にもステートの状態を編集するコマンドがいくつかあり、それらを活用することで柔軟な運用が可能です14。
セキュリティ上の注意
tfstateファイルには、リソースの設定値が含まれるので、取り扱いに注意が必要です。たとえば、TerraformでCloudSQL(GoogleCloudにおけるリレーショナルデータベース)のアカウントを設定するようなケースでは、アカウントのパスワードがtfstateファイルに保存されます。 リモートバックエンドでステート管理する場合は、関係者以外が参照できないようにアクセス権限を適切に設定してください。
また、Terraformにはtfstateファイルを暗号化する機能もあり、これを利用するのが最も確実です。筆者らも暗号化を進めているところです。
まとめ
今回は、Terraformの概念と基本的な使い方、また実運用時に注意すべきステートの扱い方法を中心に紹介しました。次回はGitHub ctions上でTerraformを実行し、Google Cloud上のインフラを自動デプロイするCI/CDパイプラインの構築事例を紹介予定です。
- Terraformについては、本誌2022年1月号「TerraformではじめるAWS構成管理」や、『WEB+DBPRESS』Vol.128の「ゼロから学ぶTerraformでも詳しく紹介されています。 ↩︎
- HashiCorp 社 https://developer.hashicorp.com/terraform/tutorials Google Cloud https://cloud.google.com/docs/terraform?hl=ja ↩︎
- https://developer.hashicorp.com/terraform/language ↩︎
- 明示しなくてもTerraformが自動判別してくれますが、プロバイダのバージョンを指定する場合は記述する必要があります。 ↩︎
- Terraformがサポートするバックエンドは次のページで紹介されています。https://developer.hashicorp.com/terraform/language/settings/backends/configuration#available-backends ↩︎
- 各ブロックタイプの説明は次のページで紹介されています。https://developer.hashicorp.com/terraform/language ↩︎
- GoogleCloudPlatformProviderであれば次のページに記載されています。https://registry.terraform.io/providers/hashicorp/google/latest/docs ↩︎
- https://registry.terraform.io/providers/hashicorp/google/latest/docs/resources/compute_network ↩︎
-
ここでは
main.tfという名前にしていますが、拡張子を.tfとする以外の決まりはありません。ファイルの分割も自由で、実行時のカレントディレクトリ配下のtfファイルがすべて処理対象になります。 ↩︎ - https://developer.hashicorp.com/terraform/language/meta-arguments/depends_on ↩︎
- ワーキングディレクトリと呼びます。 ↩︎
- ADCは、アプリケーションがGoogleCloudへアクセスするときに利用する標準的な認証のしくみです。https://cloud.google.com/docs/authentication/application-default-credentials?hl=ja ↩︎
-
リスト4ではバックエンドを指定していないので、一度applyを実行するとローカルに
terraform.tfstateという名前でtfstateファイルができているはずです。 ↩︎ -
statemv、statermなど。詳細は次のページで解説されています。https://developer.hashicorp.com/terraform/cli/state ↩︎