こんにちは、キャディで Quote というアプリケーションを開発している plant こと石田 (@plant_ja) です。
この記事は キャディ株式会社のアドベントカレンダーの20日目の記事です。
今回は AI コーディングを図で表現しつつ、我々が期待する成果物を出力してもらうための様々なアプローチに思いを馳せてみようと思います。
- ゴール設定
- コーディングエージェントへの期待と現実
- AI が書くコードを「確率密度関数」として考えてみる
- アプローチ1: 解空間の確率密度を上げる
- アプローチ2: 解空間外の出力を抑制する
- 2つのアプローチの比較
- 終わりに
ゴール設定
まず、解きたい問題があります。例えば「新規ユーザー登録用の API を作成する」などです。説明を容易にするために、ここではもう少し細分化して「ユーザーエンティティを DB と firebase に保存する」というタスクを進めていると仮定しましょう。
細分化したとはいえ、実際の問題はもっと複雑です。着手する人が置かれた状況(= コンテキスト)によって上記の課題は様々な制約を持つこととなります。
- 言語的・形式的なコーディング規約に準拠していること
- Lint エラーがなく、フォーマッターが適用されている
- 命名規則などがチームの標準に従っている
- プロジェクト固有のアーキテクチャ・設計思想と整合していること
- モジュール間の依存関係の方向が正しいこと
- 既存の共通処理を正しく再利用している
- 本番運用に耐えうる非機能要件を満たしていること
- 適切なロギングや例外処理が実装されている
- パフォーマンスやセキュリティ上の懸念がない
実際のプロダクト開発では、明示的もしくは暗黙的にさらにさらに細粒度かつ多数の制約を持つこととなります。逆に、これらの制約条件を全て満たすようなコードは、main branch にマージできる受入可能なコードであると言えます。
「制約条件を全て満たす main branch にマージできるコード」は長いので、この記事では「解空間」と呼ぶことにしましょう。
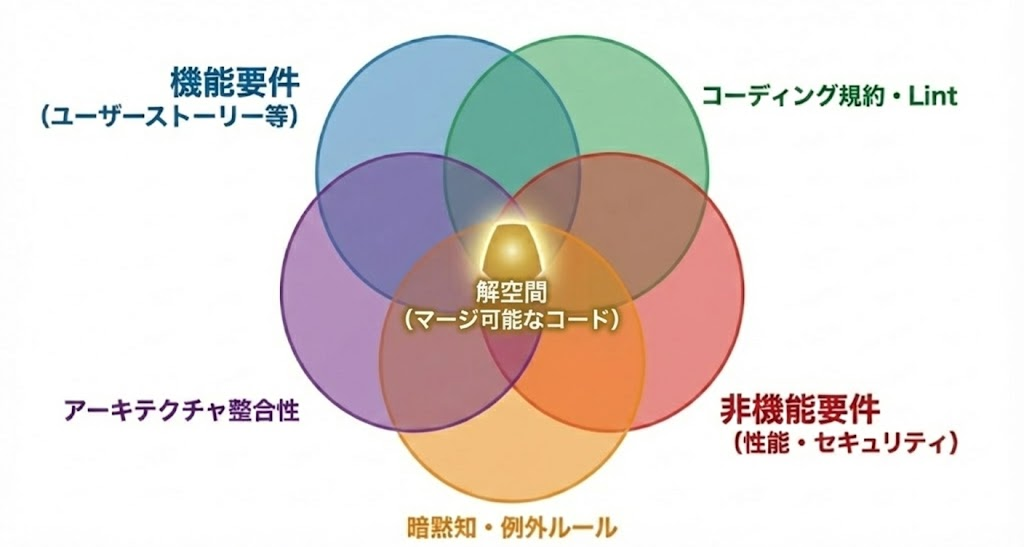
この記事では、上記のような解空間に該当するコードを、コーディングエージェントに1回の指示で出力してもらうことをゴールと設定します。
コーディングエージェントへの期待と現実
さて、ではコーディングエージェントに「ユーザーエンティティを DB と firebase に保存して」と指示すれば、作業が全て完了して私たちは退勤できるのでしょうか?
よほど成熟したコンテキストエンジニアリングが実践されていない限りは No でしょう。以下のような出力が考えられます。
- 機能要件は満たしているが、アーキテクチャルールに違反している
- 機能要件は満たしておりアーキテクチャルールも遵守しているが、ログなどの非機能要件が不足している
- そもそも機能要件を満たしていない
5回ほど、それぞれ異なるセッションで「ユーザーエンティティを DB と firebase に保存して」という指示を試してみたとしたら、次のように色々なコードが出力されるでしょう。 (図内の詳細なコード内容は重要ではなく、前述の制約条件を全て満たす出力の難しさが伝われば十分です)
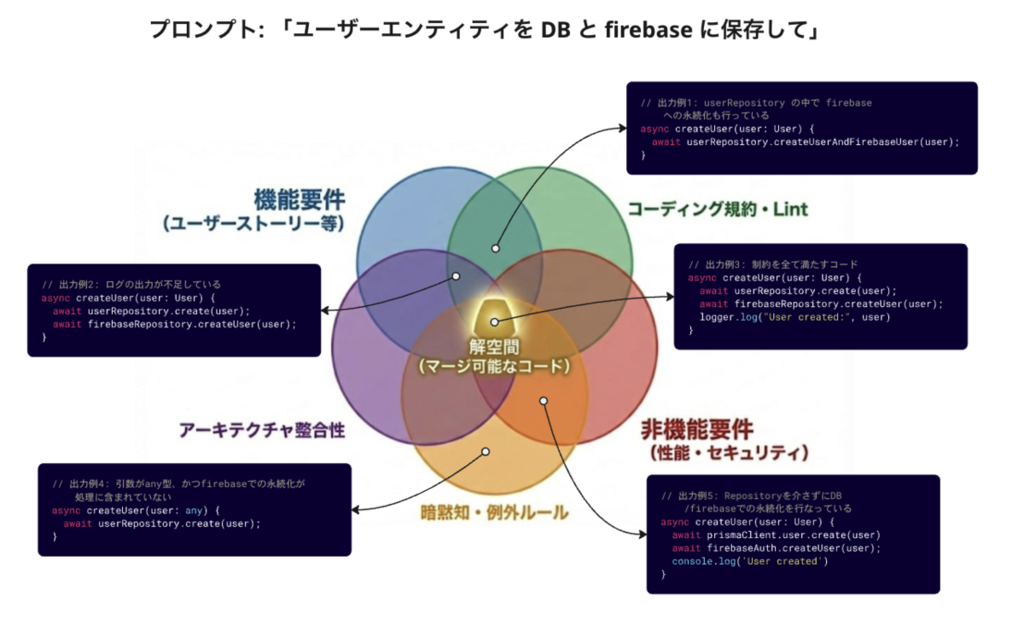
このような実験を10回、100回、1000回と繰り返すことを想像してみましょう。
解空間に相当するコードが生成されることもあれば、全ての円の外に位置するような、全ての制約を守れていないようなコードが生成されることもあるでしょう。このように、コーディングエージェントが生成する可能性がある全てのコード群を「探索空間」と呼ぶことにしましょう。
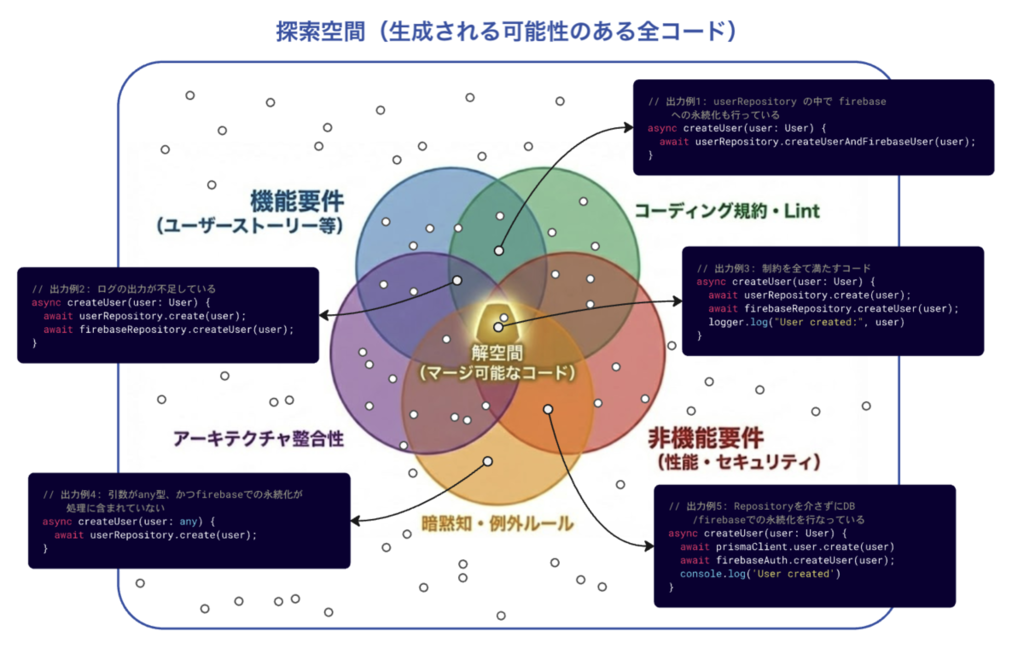
解空間の外に出力されるコードは全て、再度修正指示をしたり、手直しが必要ということになります。
LLM は確率的な回答を返すので、コーディングエージェントが生成するコードも同様に確率的な結果になります。では、少しこの確率について考えてみましょう。
AI が書くコードを「確率密度関数」として考えてみる
コーディングエージェントを使った AI コーディングは、指示をインプットとして受け取って、コードをアウトプットとして出力する確率的な関数と考えることができます。
では、例として釣鐘型のグラフを考えてみましょう。尚、ここでの目的は確率自体の厳密性ではなく、AI コーディングを最適化するためのアイデアを得ることです。
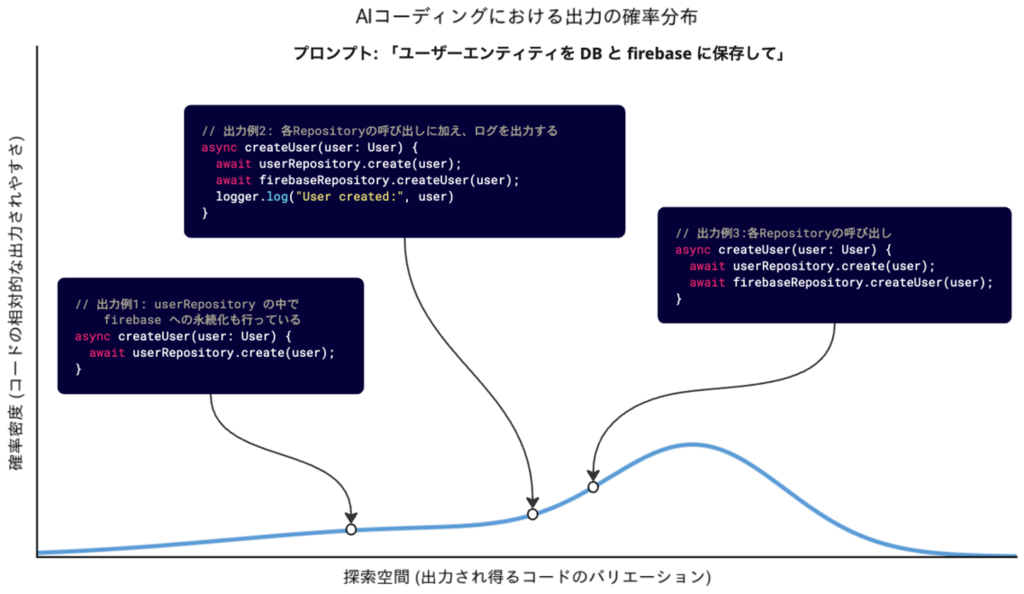
グラフの横幅が探索空間で、高さが確率密度を表しています。
- 探索空間: コーディングエージェントが生成する可能性がある全てのコード群
- 確率密度: 同じ指示を与えた時における、それぞれのバリエーションのコードの相対的な出力されやすさ
このグラフに、先ほどの解空間をマッピングしてみましょう。
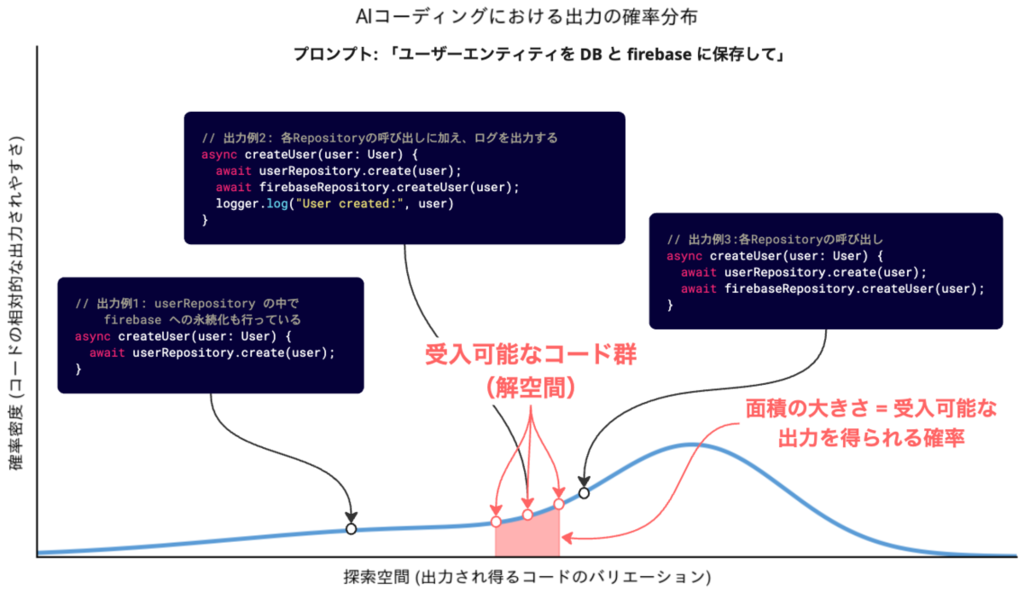
グラフ上での点の高さは確率密度(コードの相対的な出力されやすさ)を表すため、次のようなことが言えそうです。
全て制約を満たすコードが出力される確率 = 赤くハイライトされている面積 / グラフ全体の面積
今回は、一回の指示でこの解空間に該当するコードが生成されることをゴールと設定していますが、上記のグラフでは、全ての制約を満たす受入可能なコードが出力される確率はおおよそ 10% 程度しかありません。これでは、おおよそ10回に1回しか受入可能なコードを1発で生成してくれず、他の9回は修正指示が必要になります。うーん、これでは人間によるフィードバックが多く必要そうなので、作業の並列化などは難しそうです。逆に、これが8~9割ほどあれば、人間の関与はほとんど不要になりそうです。
グラフの例から、AI コーディングの最適化を「グラフ全体に対しての赤い面積の割合を増やしていくゲーム」だと考えてみましょう。赤い面積の割合が増えれば増えるほど、AI コーディングの精度や効率が上がって、修正指示に追われることがなくなるというです。
ここからは、どのようなアプローチによって赤い面積の割合を増やしていけそうかを考えていきます。
- 解空間の確率密度を上げる(赤い面積を増やす)
- 解空間外の出力を抑制する(赤くない部分の面積を減らす)
アプローチ1: 解空間の確率密度を上げる
まず最初に、解空間の確率密度を上げるというアプローチが考えられます。
これは、コーディングエージェントが出力するコードの精度を上げることを意味しており、グラフでいうところの赤い面積を増やすような考え方になります。
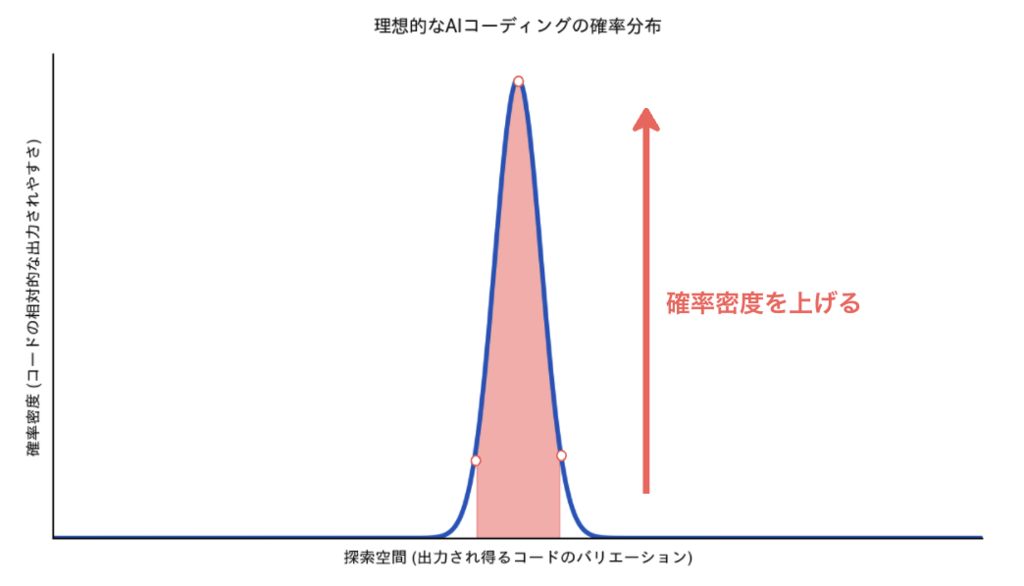
このアプローチは、指示の出し方を工夫するプロンプトエンジニアリングに始まり、エージェントにコンテキストを注入するコンテキストエンジニアリングなど幅広い手法で実現することができます。あまりにも多数の手法があるため、ここでは詳細には触れませんが、web で検索するなり Deep Research にかけるなりするとその時々のベストプラクティスが得られるでしょう。
手法は色々あれど、重要なのは「解空間の定義(= 出力すべきコードが満たすべき制約条件)を明確にして、必要最低限の情報を必要な時にコーディングエージェントに伝える」ということです。解空間の定義が曖昧だと、そもそもコーディングエージェントに正解を伝えることができませんし、情報が多すぎたりしても矛盾が発生したりコンテキストの逼迫による性能劣化が生じてしまいます。
解空間の定義
解空間の定義の重要性は AI コーディングに始まった話ではありません。コードを書くのが人間だろうが AI だろうが、品質基準は変わりません。「どういったコードを書くことを求められているのか」を細部まで説明できる、または必要になった時に参照できる状態ではないと、チームでの品質基準を満たしたコードを書くことは難しいでしょう。
それをそのまま指示に落とし込むことで、解空間の確率密度を上げることができます。
- BAD:「ユーザーエンティティを DB と firebase に保存して」
- GOOD:「User 型の引数を受け取ってユーザーエンティティを保存するメソッドを作成して。永続化は repository を介して DB と firebase に保存して。 firebase は外部サービスなので、UserRepository とは別に FirebaseRepository を作って。firebase でのユーザー作成はトランザクション境界の外になるので、共通モジュールとして提供されている logger を使ってリクエストが成功したログを残して。」
これの延長線にあるのが「仕様駆動開発」という手法だと私は理解しています。「何をどう作るか」を最初に定義することは、解空間の定義を明確にすることと考えることができます。
解空間のインプットコストとどう向き合うか
一方で、上記の例を見れば分かる通り、解空間が明示的になればなるほど、それをコーディングエージェントにインプットするコストが上がっていきます。毎回毎回こんな長文で指示をするのは億劫です。 そこで、よく知られているようにドキュメントやカスタムプロンプトの整備などを進めることによってコストを抑えることができます。ドキュメントをコーディングエージェントに渡したり、プロンプトを再利用可能にすることで文章を書くコストを下げることができます。
また、名付けを適切に行うことで文字数あたりの情報量を増やすという手段もあります。
先のプロンプトの例だと「Repository」という概念を DB への永続化にも firebase へのリクエストにも使ってしまっていますが、これだと「外部サービスとの通信の場合は〜」という if 文が指示もしくはドキュメントの中に必要になってしまいます。そこで、Ports & Adapters パターンに倣って、外部サービスとの接続には Repository ではなく Adapter という概念を用いるようにすると、if 文が1つ減ります。ドキュメントが増えれば増えるほど、この1つの違いは大きな差になります。また、ここでの名付けは、一般的であればあるほどモデルが学習しているため良いです。これを仮に Adapter ではなく独自に Gaiser(Gai-bu ser-vice)と名付けてしまうと、Gaiser の責務や概念を1つ1つインプットする必要性が生じてしまいます。*1
コンテキストの増大
インプットするコストとは別に、コーディングエージェントが作業を進めるにつれてコンテキストが増大していくため、指示への注意が弱まってしまうという問題もあります。この問題への対応策として、コーディングエージェントが自律的に情報を収集・判断できるようにインデックスとなるドキュメントを用意しておいたり、必要なタイミングで情報を取得しにいくという段階的開示 (Progressive Disclosure) という手法が Claude Code では skill *2 という概念として実装されていたりします。
上記のような様々な取り組みによって、解空間の確率密度を上げることができます。次に、もう1つのアプローチについて考えてみましょう。
アプローチ2: 解空間外の出力を抑制する
「解空間の確率密度を上げる」というアプローチが、グラフでいうところの赤い面積を増やすという営みだったのに対して、こちらのアプローチは「赤くない部分の面積を減らす」という対照的な営みになります。

コーディングエージェントが作業完了した時に、機械的もしくは自己的なフィードバックを促すことで、基準に満たないコードだった場合に自律的に修正をしてもらおうというアプローチになります。確率的に生成されたコードを、linter などの静的解析や単体テストなどの決定的な処理によって検証することで、解空間外のコードを機械的に抑制することが可能です。
linter による抑制
例えば、linter で「ドメイン層からはインフラ層を参照してはならない」というルールを記述しておけば、コーディングエージェントがアーキテクチャ違反のコードを書いた瞬間にエラーとして弾くことができます。また、AST ベースでのルールを定義すれば 要素に alt text がついていることを強制したり、switch 文の中の case ラベルをアルファベット順に強制 したりと色々なことができます。
タスクの分解によるコード出力バリエーションの絞り込み
また、タスクの分解というのも1つの手でしょう。1回の指示で出力するコードの量が少なければ少ないほど出力されるコードのバリエーションは限られるため、1回の指示で解空間に位置するコードを出力することが容易になるでしょう。
2つのアプローチの比較
では、上記の2つのアプローチをどのように使い分けるべきなのでしょうか?pros/cons を整理してみましょう。
- アプローチ1: 解空間の確率密度を上げる
- 概要
- 指示やコンテキストを工夫し、最初から正解が出やすいようにする
- pros
- 直接的に出力精度が上がる
- 低コストで検証できる
- cons
- 確率的な出力を行う LLM の性質上、出力結果に一定のブレが生じることは許容する必要がある
- コンテキストの増大による性能劣化に弱い
- 概要
- アプローチ2: 解空間外の出力を抑制する
- 概要
- Linterやテストで出力を検証し、不正解を弾いて修正させる
- pros
- 決定的な処理によるフィードバックなので、確率に左右されない
- ただし、コーディングエージェントがコードを出力した後に lint や単体テストを実行させる仕組み作りが必要
- 個別のコーディングエージェントに依存しない
- 決定的な処理によるフィードバックなので、確率に左右されない
- cons
- 指示してから結果が得られるまでの時間がかかる
- コード出力 → 決定的な処理によるフィードバック → エージェントが自律的に判断して修正
- 複雑なルールについては実装が必要
- 指示してから結果が得られるまでの時間がかかる
- 概要
それぞれで強みが異なるため、片方だけを使うというよりかは両方を組み合わせて活用していくのが良さそうですね。
終わりに
ということで、今回は図を用いて AI コーディングの最適化について考えてみました。最適化が進んで、コーディングエージェントに1回の指示で受入可能なコードを出力してもらえる確率が上がると、複数のセッションを使った並行開発だったり Devin のようなフィードバックサイクルが長いエージェントをより効率的に利用することができるようになります。
コーディングエージェントが出てきてしばらくの時間が経ちました。人によって AI コーディングとの向き合い方は様々だと思いますが、ぜひ皆さんも年末というこのタイミングで改めて AI コーディングの可能性を探究してみてください。この記事が少しでも気づきや発見に繋がると幸いです。
また、キャディでは一緒に働く仲間を大募集中です。 どうやら最近 company deck が update されたようなので、興味があれば是非見てみてください。
CADDi Careers - 採用総合サイト careers.caddi.com
CADDi Careers - エンジニア向け採用情報 careers.caddi.com
*1:尚、Gaiser というアーティストの方がいらっしゃるようです
*2:https://platform.claude.com/docs/ja/agents-and-tools/agent-skills/best-practices#