こんにちは、Drawer Growthグループ ソフトウェアエンジニアの内田(id:usadamasa, @usadamasa)です。弊社ではApache Icebergの活用*1とともに、一部のアプリケーションにJavaを導入しています。今回は、システムアーキテクチャから一段レイヤを下げてアプリケーションレベルのお話しをしたいと思います。
アプリケーションアーキテクチャの設計と運用課題
アプリケーション開発において、私たちエンジニアは通常、パッケージ構成やレイヤの依存関係、ロギングなどの観点からアーキテクチャを設計します。
しかし、実装との不整合やチーム内での共通認識が不十分なまま進むと、品質課題として潜在化し、やがて本番障害や開発者の疲弊といった形で問題に発展します。また、DevinやClineなどのAIエージェントに適切に実装してもらうにはプロンプトやドキュメントで設計を伝える必要がありますが、相応の準備が求められます。
このような課題を解決する手段として、設計と実装の整合性をテスト可能にするJavaライブラリ「ArchUnit*2」があります。JUnitのフレームワーク上で動作し、設計ルールを宣言的なコードで定義してテストとして実行できるため、普段の自動テストと同様の迅速なフィードバックが得られます。
ArchUnitの導入の経緯と効果
私たちのアプリケーションは開発開始から約半年の若いコードベースで、初期はアーキテクチャらしい構造もないプロトタイプからスタートしました。開発が進む中で、パッケージとレイヤ構成を設計し、リファクタリングを重ねて整理してきました。
次の図はそのレイヤ構成です。「オブジェクト設計スタイルガイド*3」を参考に、Application層、Service層、Domain層、InfraStructure層の構成を採用しました。

実装の大部分はこの構成に従っていますが、初期のコードやレビューをすり抜けた箇所には、設計に適合しない部分が残っていました。開発が一段落し整理を試みたものの、実際にどの程度のコードが不適合かは把握できていない状況でした。
そこで、冒頭のArchUnitを導入し、不適合な実装の網羅的な検出と、今後のルール遵守を継続的にチェックできる仕組みを構築しました。
ArchUnitでは、パッケージやクラス間のアクセス、継承、循環参照など様々なルール検査が可能です*4。今回はその中でも「Layer Checks*5」を用い、定義したレイヤ構造への準拠を確認しました。以降で、その具体的なルールと実装の一例を紹介します。
初期バージョン
「DAO層にアクセスできるのはRepositoryImpl層のみである」という設計をコード化しましょう。
DAO(persist.dao パッケージ)層はRDBなどのMWと直接通信をする層です。Service層(service パッケージ)はRepository層(domain.repositoryパッケージ)をインタフェイスとし、RepositoryImpl(persist.implパッケージ)がDAO層に直接アクセスします。つまり、DAO層に直接アクセスできるのはRepositoryImpl層のみという設計です。この設計をArchUnitで記述すると、次のようになります。*6
@AnalyzeClasses(packages = "com.example.sample") public class LayeredArchitectureTest { @ArchTest static ArchRule test_DaoMustBeAccessedOnlyFromRepositoryImpl = // DAO <- only repository impl layeredArchitecture().consideringAllDependencies() // <persist> DAO .layer("DAO").definedBy("com.example.sample.persist.dao..") // <persist> Repository Impl .layer("RepositoryImpl").definedBy("com.example.sample.persist.impl..") // Assert .whereLayer("DAO").mayOnlyBeAccessedByLayers("RepositoryImpl"); }
@AnalyzeClassesのアノテーションと、フィールド変数としてテストケースが記述されていることに驚くかも知れませんが、これはキャッシュ化のためで、本筋からは外れるので、詳細は省きます。*7
Layer Checksは Architectures.layeredArchitectureに続いてメソッドチェインでルールを記述していきます。検査対象のレイヤ名と対応するパッケージ名のセット(LayerDefinition)は複数記述できます。LayerDefinitionに続いて、どのレイヤにどのようなルールが期待されるのかを whereLayer("DAO").mayOnlyBeAccessedByLayers()のような形で続けます。これもメソッドチェインで複数記述できます。
さて、このテストケースはJUnit5のテストスイートとして実行できます。実行は高速で数秒で完了します。

さて、検査に違反する場合を見て見ましょう。サンプルとしてわざとDAO層のクラスをService層である ExampleQueryService から直接呼び出す実装を書いてみます。
package com.example.sample.service; // ..snip.. public class ExampleQueryService { // FIXME! This dependency must be removed!! ExampleDao exampleDao; // ..snip.. }
この状態でJUnit5を実行すると、期待通りテストが失敗しました。少々見慣れないメッセージが出力されますが、読み解くことは容易です。
java.lang.AssertionError: Architecture Violation [Priority: MEDIUM] - Rule 'Layered architecture considering all dependencies, consisting of layer 'DAO' ('com.example.sample.persist.dao..') layer 'RepositoryImpl' ('com.example.sample.persist.impl..') where layer 'DAO' may only be accessed by layers ['RepositoryImpl']' was violated (1 times): Field <com.example.sample.service.ExampleQueryService.exampleDao> has type <com.example.sample.persist.dao.exampleDao> in (ExampleQueryService.java:0) (StackTrace省略)
AssertionError としてArchitectureの違反(Violation)が報告され、5行目の Field ~~ が具体的な違反コードへの指摘となります。
さてサンプルコードがやや長くなりましたが、このような形で設計意図をルールとして記述し、JUnitとして実行できることがおわかりいただけたかと思います。
チームへの共有とルールの改善
さて、このようなテストコードを書き、実際に修正に入る前に導入についてチームに共有したところ、このようなフィードバックをもらいました。

チームメンバの言うとおり、たしかに私はこの設計について把握しておらず、とても有益な情報でした。ではこの設計をArchUnitに反映させましょう。先ほどのテストケースに追加・編集します。
@AnalyzeClasses(packages = "com.example.sample") public class LayeredArchitectureTest { // [ADDED] QueryService allow to access DAO directly static DescribedPredicate<JavaClass> QUERY_SERVICE_PREDICATE = resideInAPackage("com.example.sample.service..") .and(nameEndingWith("QueryService")); @ArchTest static ArchRule test_DaoMustBeAccessedOnlyFromRepositoryAndQueryService = // DAO <- only repository impl layeredArchitecture().consideringAllDependencies() // <persist> DAO .layer("DAO").definedBy("com.example.sample.persist.dao..") // <persist> Repository Impl .layer("RepositoryImpl").definedBy("com.example.sample.persist.impl..") // [ADDED] <service> Query Service .layer("QueryService").definedBy(QUERY_SERVICE_PREDICATE) // Assert .whereLayer("DAO").mayOnlyBeAccessedByLayers( "RepositoryImpl", "QueryService" // [ADDED] ); }
DescribedPredicate が新しく登場しました。これは、独自のルールを記述するためのAPIであり、and条件、or条件や様々な評価方法を組み合わせることができます*8。ここではService層のなかでも、クラス名が QueryService で終わるもののみDAO層にアクセスできるというルールを追加しています*9。これにより先ほど違反として検出されたコードも、適合していると判定されるようになりました。あとは残った違反コードを修正すれば終わりです*10。
このような形で当初の課題であったアプリケーションアーキテクチャの継続的かつ自動的なチェックが可能になりました。
ArchUnitの所感
ここからはArchUnitの意義や所感についてやや雑多に述べようと思います。
よいところ
- 自然言語で記述した設計ルールや意図をコードとして落とし込めること
- PRのレビューで初めて知った、が防げる
- 解釈のブレも抑えられる
- フィードバックが高速かつJUnitに統合されていること
- 追加の手順が不要で実行漏れが防げる
- CIパイプラインにそのまま載せられる
- 画像のようにGitHub ActionsのJUnit Test Reportで通知も可能
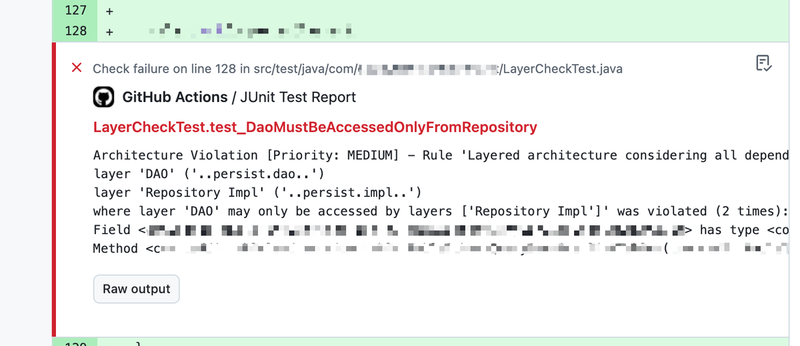
気になるところ/所感
一方で、ArchUnitにはいくつか注意すべき点もあります。特に宣言的でDSL(ドメイン特化言語)色が強いため、習得・定着には一定のコストがかかると感じました。
中でも DescribedPredicate を用いてルールをカスタムする場合には、ルールそのものの動作検証が必要になるため、実装には慎重さが求められます。
このため、ArchUnitで記述するルールは、設計意図に基づいたものに限定し、必要以上に複雑な実装は避けるべきでしょう。 一般的なコーディング規約や静的解析ルールについては、SpotBugs*11 やSonarQube*12のようなプリセットの揃ったLinterと併用するのが望ましいと感じました。
また、ArchUnitでは循環的複雑度などの構造的な指標を定量的に評価し、ルール化できます*13。 しかし、あくまで単一のコードベースに対するLinterであり、全社的な品質管理やチーム横断的な指標の可視化には向きません。 クオリティマネジメント職やマネージャー層向けには、別途横断的に可視化できるツールの導入を検討すべきでしょう。
ArchUnitに過度な期待を抱かず、その役割を正しく見極めたうえで、目的に応じて他のツールと適切に使い分けることが重要です。
結びに替えて: 生成AIとソフトウェアアーキテクチャ
ここから先はArchUnitとは直接関係のない与太話なので話半分で読んでいただけると幸いです。
ここ数ヶ月で、ソフトウェアエンジニアの開発環境に生成AIが急速に浸透しつつあります。 生成AIと協働するコーディング活動をVibe Coding*14と呼ぶようになってまだ新しいですが、 AIのコード生産量に人間が追いつけなくなるのはそう遠い未来ではないでしょう。
人間によるコードレビューが困難になったとしても、機能品質は従来の自動テストやE2Eテストでの担保や、そもそもソフトウェアエンジニアを介さずプロダクトマネージャーなどの検証で十分になるかもしれません。では非機能品質は、内部品質は、ソフトウェアアーキテクチャはどのように担保出来るでしょうか? そもそもこの先ソフトウェアアーキテクチャにその存在意義はあるでしょうか?
話が大きくなりますが、生成AIによるソフトウェア開発に即したアーキテクチャとその評価指標、つまり生成AIを前提としたアーキテクチャ適応度関数*15の発明が必要なのだと思います。
生成AI自身もソフトウェアであり、実行にはサーバのリソースや時間、つまり電力を必要とします*16。 それらは有限かつ希少な資源です。人類が無限のエネルギーを手に入れるにはまだだいぶ掛かるでしょう。 となると、AIの消費エネルギー*17を節約するアーキテクチャ*18が求められ、それを測定・評価する指標を元に開発するようになるのではないでしょうか。もしかしたらそれは、人間がいままで考え出してきたソフトウェア設計・プラクティスとそんなに変わらないのかも知れません*19。
加えて、AIへのフィードバックには網羅的、高速かつ自動的な検査が必要になります。2025年現在、一般的な開発組織ではアーキテクチャ適応度関数が十分に浸透しているとは言いがたい状況かもしれません。当然その自動化も発展の余地があります。本記事はアプリケーションアーキテクチャの検証が主題でしたが、生成AIによるソフトウェア開発がより高いレイヤに組み込まれるにつれて、それに合わせたより抽象度の高い適応度関数を用いていく必要が出てくるかもしれません。
そのようなソフトウェア設計活動は依然としてエキサイティングかつ創造的であり、ソフトウェアエンジニアという職はまだまだ面白いものであり続けるのではないかと期待しています。
さて、いい加減個人ブログに書けと言われかねないためそろそろお決まりの言葉で締めさせてください。キャディ株式会社では製造業AIデータプラットフォームとして成長していくためにエンジニアの採用を加速しております。生成AIが発展していってもソフトウェアエンジニアとしてまだまだやっていきたいという方は、ぜひご連絡ください!
ArchUnitに関する詳細な解説・先行事例
- ArchUnitでアーキテクチャの単体テストを行う
- ArchUnitでアーキテクチャをテストする - mtx2s’s blog
- ArchUnit をマルチモジュール構成に対して適用する | omuomugin
- ArchUnit使い方メモ #Java - Qiita
*1:キャディでの Apache Iceberg 活用事例, Apache IcebergとCDCによるデータレイクハウス拡張, 氷山を穿つ - Apache Icebergに大量データを投入するTopic
*2:Unit test your Java architecture - ArchUnit
*3:オブジェクト設計スタイルガイド - O'Reilly Japan
*4:ArchUnit User Guide 4. What to Check
*5:ArchUnit User Guide 4.6 Layer Checks
*6:pomやgradleの記述などはリファレンスを参考にしてください。
*7:ArchUnit User Guide 3.3. Using JUnit 4 or JUnit 5
*8:ArchUnit User Guide 7.3. Creating Custom Rules
*9:特別なルールはコメントや背景を付記すると良いでしょう。テストもコードです。
*10:実際はArchUnitの導入を先に行い、既存の違反コードはFreezing Arch Rulesでマーク、徐々に違反コードを削減していきました。
*12:Better Code & Better Software | Ultimate Security and Quality | Sonar
*13:ArchUnit User Guide 8.7. Software Architecture Metrics
*14:Vibe coding - Wikipedia ここでは広義のVibe codingを意図しています。
*15:ソフトウェアアーキテクチャメトリクス - O'Reilly Japan
*16:【提言】生成AIの普及が与える日本の電力需要への影響
*18:awslabs/mcp: AWS MCP Servers — specialized MCP servers that bring AWS best practices directly to your development workflow
*19:AI-friendly code design | Technology Radar | Thoughtworks