こんにちは、Data&Analysis部(D&A)です。
D&Aでは週1回、機械学習の勉強会を開催しており、本記事は、勉強会の内容を生成AIを活用して記事にまとめたものものです。
※勉強会内容公開の経緯はこちら
※過去の勉強会は「社内勉強会」タグからもご覧いただけます。
概要
今回の勉強会ではAlibaba Cloud が開発した Vision-Language Model (VLM) である Qwen シリーズ、特に Qwen2-VL の特徴、性能、関連モデルについて話しました。
調査した動機は、Qwenシリーズは日本語の性能が高いとされており、そのマルチモーダルモデルが画像解析を扱う我々の事業領域にマッチしていることです。またDeepSeek R1の蒸留モデルの中にQwenシリーズがあることが調査の更なる動機です。
具体的にはQwen2-VL の技術的な詳細、ベンチマーク結果、多言語対応、そして最新の Qwen 2.5 VL についてです。
また検索エンジンモデルへの応用事例や、今話題のdeepseekの開発したVLMの簡単な紹介も行います
Qwen2-VL の概要
Alibabaが開発しているQwen シリーズには複数のモデルが存在します。今回はその中でマルチモーダルモデルのQwen2-VL に焦点を当てました。
Qwen2-VL は、静止画像だけでなく、ビデオや UI 操作など、多様な視覚モダリティに対応することを目指しています。
モデルサイズには複数のバリエーションがあり、最大で 720億パラメータ、最小で 20億パラメータ程度のものがあります。
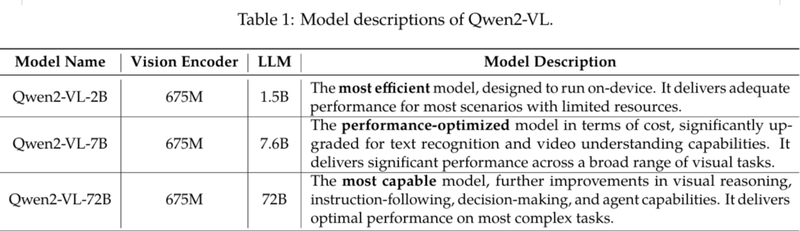
技術的な特徴
ここではQwen2-VLで紹介されている特徴の中で特に興味深いものを挙げます。
任意の解像度への対応: 後に解説するRoPEの2次元拡張である2D-RoPEで画像と位置情報をエンコードすることで様々な画像サイズに対応できます。論文中で「Naive Dynamic Resolution」というキーワードで紹介されています。
M-RoPE: RoPE (Rotary Position Embedding) を拡張した Multimodal Rotary Position Embedding (M-RoPE) を導入し、文字列から動画までのモダリティを扱えるようになっています。これにより、1D (文字列)、2D (画像)、そして3D(動画)のエンコードが可能になっています。
主なベンチマーク結果と性能
ここではQwen2-VLで紹介されているベンチマークの結果のうち興味深いものを挙げます。
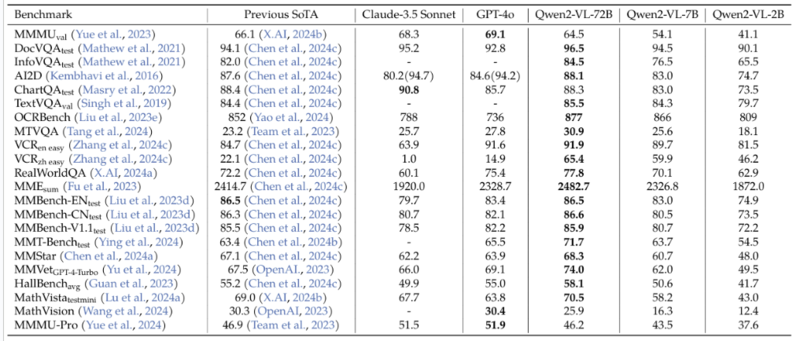
主要なベンチマークで、GPT-4V(ision) や Gemini Pro などの競合モデルと比較して、遜色ない、あるいは一部で上回る性能を示しています。 特に、ドキュメント理解 (VQ) やチャート理解 (UA) のタスクにおいて、良好な結果が得られています。
また複数の言語でのベンチマーク結果で、日本語においても一定の性能を発揮することが示されています。
特にマルチリンガル OCR ベンチマークの結果として、Qwen2-VL が日本語にも比較的良く対応しており、日本語を扱う用途での利用が期待されます。

関連モデル
- Janus-Pro: DeepSeek が開発したマルチモーダルモデルで、エンコーダーに SigLIP-L を採用しています。SigLIPは固定解像度での入力で、文書画像のような高密度なタスクにおいては Qwen2-VL の方が優位性があるかもしれません。
- ColQwen2: Qwen2-VL-2B-Instruct をベースに、画像検索 (Visual Retriever) 用に ColBERT strategy を用いて訓練されたモデルです。 Google の PaliGemma を用いた場合と比較して、Qwen2-VL を用いることで日本語文書検索の性能向上が期待されます。
- Qwen 2.5 VL: 最新のバージョンとして言及されており、言語モデルのデコーダーに Qwen 2.5 の言語モデルを使用し、ビジョンエンコーダーの一部を効率化したものが採用されています。既存の API 提供モデルと比較しても遜色ない性能を発揮するようです。
モデルの利用とライセンス
Qwen シリーズのモデルは Hugging Face で公開されており、容易に試すことができます。
ただしモデルのライセンスについては注意が必要で、ソースコードのライセンスとモデル自体のライセンスが異なる場合があります。特に商用利用を検討する場合は、ライセンス契約の詳細を確認する必要があります。
具体的には、Qwen2VL-72BはQwenライセンスであり、商用利用かつユーザー数が一定以上いるサービスに利用する場合にはライセンス契約が必要です。Qwen2-VL-2B, やQwen2-VL-7Bであればapache-2.0なので、もう少し気軽に利用できます。
結論と感想
Qwen2-VL は、画像から動画までの推論や任意の解像度での推論を可能にする Vision-Language Model であり、高いベンチマーク性能と多言語対応能力を持っています。 日本語のベンチマークで高い性能を持った公開モデルは嬉しいですね。
Qwen2.5-VLの動向から今後は言語モデルの進化による推論能力の向上や学習の効率化が見込めそうです。また画像や動画に限らず他のモダリティの拡張もあり得るのではないでしょうか。公開されてるモデルなので今後も動向を伺いたいと思います。
参考リンク
リンク一覧はこちらをクリック
- [2409.12191] Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
- Qwen2-VL
- [2410.07073] Pixtral 12B
- [2104.09864] RoFormer: Enhanced Transformer with Rotary Position Embedding
- [2307.06304] Patch n' Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution
- Qwen2.5 Technical Reportの中に潜る - ABEJA Tech Blog
- Large Vision Language Model (LVLM) に関する最新知見まとめ (Part 1) - Speaker Deck
- 【Qwen2-VL】画像や動画を異なる解像度で処理できる最新VLM | AI-SCHOLAR | AI:(人工知能)論文・技術情報メディア
- Qwen2-VL : ローカルで動作するVision Language Model | by Kazuki Kyakuno | axinc | Medium
- vidore/colqwen2-v0.1 · Hugging Face
- [2412.15115] Qwen2.5 Technical Report
- [2501.15383] Qwen2.5-1M Technical Report
- deepseek-ai/Janus-Pro-1B · Hugging Face
- deepseek-ai/deepseek-llm-7b-base · Hugging Face
- GitHub - deepseek-ai/Janus: Janus-Series: Unified Multimodal Understanding and Generation Models
https://zenn.dev/yumefuku/articles/pdf-search-colqwen2