こんにちは、Data&Analysis部(D&A)です。
D&Aでは週1回、機械学習の勉強会を開催しており、本記事は、勉強会の内容を生成AIを活用して記事にまとめたものです。
※勉強会内容公開の経緯はこちら
※過去の勉強会は「社内勉強会」タグからもご覧いただけます。
概要
今回の勉強会では、ナレッジグラフ(後述)とRAG(Retrieval-Augmented Generation)を組み合わせた技術であるGraphRAGについて調査しました。
調査の動機は、社内でRAGを用いたソリューションの検討が進められており、さらなるソリューションの創出に向けた一案としてGraphRAGが挙げられていたためです。
本記事では、GraphRAGのユースケース、アルゴリズムの概要、評価方法、そして課題について紹介します。
GraphRAGの概要
RAGの概要と課題
従来のRAGは、質問と意味的に類似する内容(コンテキスト)をベクトル検索によって抽出し、質問とコンテキストをプロンプトとしてLLM(Large Language Model)に入力することで回答を生成します。
しかし、ドメイン知識が関与する質問、特に物事間の関係性が重要な質問に対しては、関連性の低い内容を出力してしまうことがあります。
原因は回答を生成する過程で行う文章のチャンク化の際、ドメイン知識を表す文章が含まれていない可能性があるためとされています。
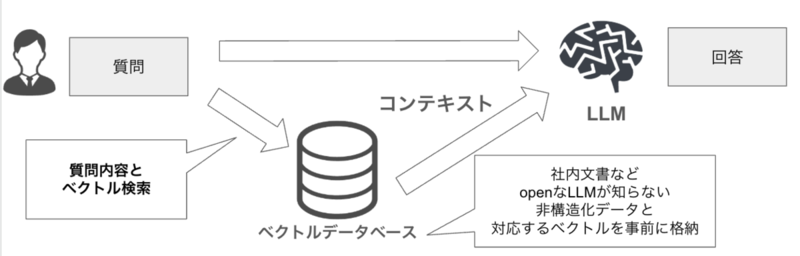
GraphRAGの基本的な考え方
GraphRAGは、RAGの課題を解決するために、ナレッジグラフを利用します。
質問のドメイン知識と合致する回答をナレッジグラフから出力し、それをコンテキストとすることで、質問により関連した内容を見つけ出せることが期待できます。
実務においては、強みと弱みを補い合うためにGraphRAGを全文検索やRAGと併用することが効果的です。
GraphRAGの基本的な流れは、自然言語である質問をグラフデータベース用のクエリ言語に変換し、データベースに問い合わせることでコンテキストを取得し、質問とコンテキストをLLMに入力して回答を得るというものです。
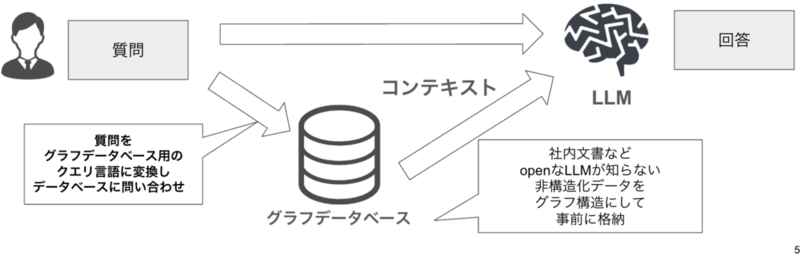
ナレッジグラフとは
ナレッジグラフとは、エンティティ(ノード)同士をリレーション(エッジ)で繋いだグラフの集合のことです。
情報の関係性をグラフという繋がりで表現するため、RAGよりもドメイン知識を加味した回答を出しやすくなります。
例えば、「日本の首都は東京」という関係性は、"日本"と"東京"というエンティティが"首都"というリレーションで繋がったグラフとして表現されます。エンティティにはプロパティ(属性)を持たせることも可能です。

アルゴリズムの概要
GraphRAGのアルゴリズムは、大きく分けて下図の標準的なGraphRAGとMicrosoftによるGraphRAGの2種類があります。
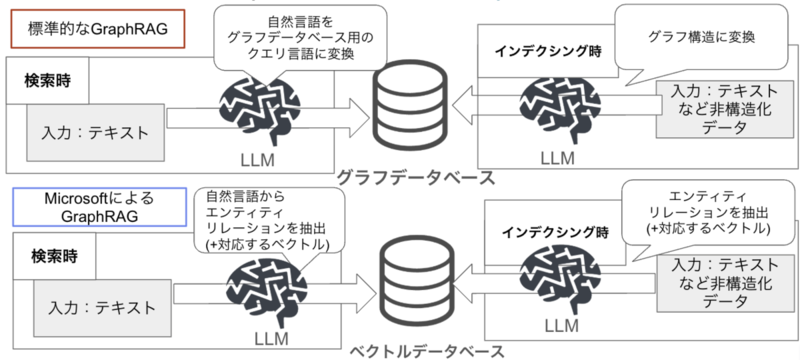
標準的なGraphRAG
インデクシング時: テキストなどの非構造化データからLLMを用いてエンティティとリレーションを抽出し、グラフ構造に変換してグラフデータベースに格納します。
検索時: 質問をLLMによってグラフデータベース用のクエリ言語(一般的にはCypher、他にGremlinやSPARQLなど)に変換し、グラフデータベースに問い合わせを行います。 グラフデータベースとしては、Neo4jやAmazon Neptuneなどが例として挙げられます。LangChainなどのフレームワークを利用して実装することも可能です。
MicrosoftによるGraphRAG
MicrosoftによるGraphRAGは、標準的なGraphRAGとは異なり、検索時にクエリ言語への変換を行いません。
インデクシング時: LLMを用いてテキストからエンティティとリレーションを抽出し、それらに紐づく文章の要約対応するベクトルをデータベースに格納します。 さらに、コミュニティ検出アルゴリズムを用いて内容が類似するエンティティをグループ化(このグループのことをコミュニティと呼ぶ)し、コミュニティ内のエンティティに紐づく文章を要約したコミュニティレポートと呼ばれるものを作成します。
検索時: 広い範囲の話題について概要を知ることをを目的としたグローバル検索(例:LLMについて教えて下さい)と、特定の話題に関して詳しく知ることをを目的としたローカル検索(例:OpenAIが提供しているLLM別に、その特徴と得意・苦手なタスク、活用事例を教えて下さい)の2つの方法質問に答えます。
グローバル検索では、各コミュニティレポートと質問に対する回答と重要度を出力し、重要度の高い回答をLLMのコンテキストにして回答を生成します。
ローカル検索では、エンティティの文章と質問文とのベクトル検索で意味が近いエンティティを抽出し、類似したエンティティに関連する情報をLLMが要約して回答します。
GraphRAGの評価
ナレッジグラフの評価
評価方法の例として以下のようなものがあります[6]。
- GNN(Graph Neural Network)を用いてナレッジグラフをベクトル化し、下流タスク(分類、ベクトル検索など)の精度で評価する。
- 正解データから重要な単語やエンティティを抽出し、その単語に関する内容がナレッジグラフにどれだけ含まれているかを評価する。
- あるエンティティのサブカテゴリになるものがどれだけ含まれているか(=エンティティの多様性)を評価する。
- 例:人というエンティティに対して、友人、親子などの関連性のあるエンティティがナレッジグラフにどれだけ存在するか。
GraphRAGの評価
GraphRAGの評価方法としては、主に以下の2つがあります。
- 人手で作成した質問・回答と、GraphRAGが出力する内容との関連性を人手評価する。
- LLMの評価手法を利用する(例:ragas、LLM as a judgeなど)。
- MicrosoftのGraphRAGでは、LLMによって回答を評価する手法が用いられています。
ナレッジグラフ / GraphRAGの課題
ナレッジグラフの課題
- 同一内容のエンティティの統合: 表記揺れやデータソースの重複などにより、同一内容のエンティティが複数存在してしまうため、それらを統合する必要があります。
- 取り組みの例として、何らかのルールに基づいて統合する手法や、エンティティに関する情報を特徴量とし、エンティティの分類タスクを解き、同じ分類結果ならばエンティティを統合するという試みもあります。
- 情報の正確性の担保: 信頼できる情報源からデータを取得すること以外に、ナレッジグラフの情報の正確性をどのように担保するかが課題となります。
- グラフの更新の難しさ: 既存のデータソースに含まれない情報(例:バズワード)、知識の変化(例:製品名が変わった)を既存のグラフとの整合性や既存のグラフ同士の関係性を保ったうえで更新させるのが難しいという課題があります。
GraphRAGの課題
- トークン料の増大: エンティティ・リレーション抽出など、様々な処理でLLMを使用するため、トークン料が膨大になる可能性があります。
- 対策として、Triplexなどのエンティティ・リレーション抽出を効率化するツールも存在します。
- その他の課題: 上記のナレッジグラフ自体の課題も、GraphRAGの品質に影響を与えるため、GraphRAGの課題と言えます。特に、同一内容のエンティティの統合については、MicrosoftのGraphRAGに該当のフラグを設定する機能が計画されていますが、本記事執筆時点(2025年4月)では未実装です。
参考文献
[1] GraphRAGをわかりやすく解説
[2] 話題のGraphRAG、その可能性と課題を理解する
[3] 話題のGraphRAGとは - 内部構造の解析と実用性の考察
[4] From Local to Global: A Graph RAG Approach to Query-Focused Summarization
[5] Welcome to GraphRAG
[6] Structural Quality Metrics to Evaluate Knowledge Graphs