こんにちは、Data&Analysis部(D&A)です。
D&Aでは週1回、機械学習の勉強会を開催しており、本記事は、勉強会の内容を生成AIを活用して記事にまとめたものです。
※勉強会内容公開の経緯はこちら
※過去の勉強会は「社内勉強会」タグからもご覧いただけます。
はじめに
今回は、マルチテナントSasSにおけるLLMシステムアーキテクチャの方針と考慮事項について調査しました。調査の経緯は以下のとおりです。
キャディでは様々なデータに対してLLMを活用した技術検証が進んでおり、近い将来CADDi Drawerを始めとしたマルチテナントSaaSにLLMソリューションを何個も提供する可能性があるため。
その将来の実現のために、本記事での紹介内容をあらかじめ考慮したシステムを考えておく必要があると感じたため。
本記事では、以下の資料を参考にしています。
- マルチテナントSaaSアーキテクチャの構築 16章 生成AIとマルチテナント
- re:Invent 2024: AWSのマルチテナントSaaSにおけるLLM活用アーキテクチャ
LLMシステムアーキテクチャの概要
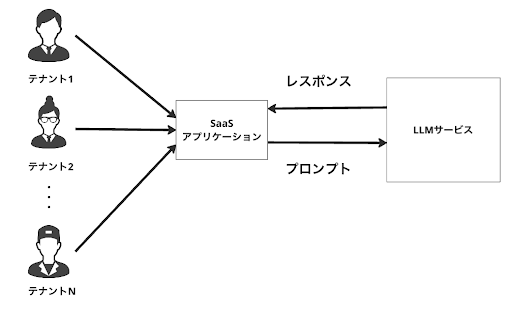
LLMシステムをマルチテナントSaaSで展開する場合、シンプルな構成として下図のようなものが考えられます。
この場合、同じプロンプトを送信した場合同じレスポンスしか得られません。そのため、個社(以降、テナント)ごとの体験(例:社内資料に関する質問への回答など)を提供することで顧客体験の改善をさせたい需要が出てくる場合、その需要に対応できません。
そのため、テナントごとにカスタマイズされたLLMシステムの構築が重要となります。
テナントごとの体験を提供するLLMシステム
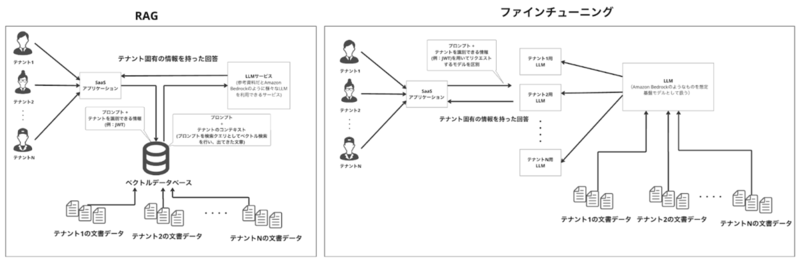
テナントごとの体験を提供するためのアプローチとして、下図のようなRAG(Retrieval-Augmented Generation)とファインチューニングがあげられます。
RAG
RAGを利用する場合は、リクエストの度に外部のデータソースから関連情報を検索し、その情報をプロンプトに含めてLLMに送信することで、テナント固有の情報を持ったレスポンスを生成することができます。
手順としては以下のようなステップを踏みます。
- テナント識別: JWT(JSON Web Tokens)などを用いてリクエストがどのテナントからのものかを識別します。
- データ検索: JWTから抽出できるテナントIDを基に、該当するテナントのデータに対してベクトル検索を実行します。
- コンテキストの追加: 検索結果として得られたテナント固有の情報は、プロンプトに追加されLLMに送信されます。
ただし、以下のような課題もあります。
- コスト: RAGではリクエストごとにプロンプトとコンテキストを結合してLLMにを送信する必要があるため、トークン数のコストが増加する可能性があります。
- 精度: プロンプトとコンテキスト全体のトークン数がLLMの許容上限を超えることで、チャンク化する際の文章の切れ目が悪くなり回答の精度が劣化する可能性があります。
- アクセス制御:別の顧客の情報が流出してしまうのを防ぐために、適切なテナントのデータにアクセスするように制御しなければなりません。
ファインチューニング
テナント固有のデータを用いて既存のLLMモデルを再学習させることで、そのテナント特有の知識をモデルに埋め込むことができます。 ファインチューニングを利用すると、RAGを使わずともテナント固有の情報を提供できるのてRAGのデメリットを低減できるというメリットがあります。
しかし、個社ごとにLLMモデルを作成、デプロイ、運用する必要があるため、管理が煩雑になってしまうというデメリットがあります。
RAGとファインチューニングの併用
RAGとファインチューニングは決して排他的なものではなく、プロダクト要求や顧客のTier(例:料金プラン)に応じて併用するという考え方もあります。資料では、以下の通り、Tierに応じてRAGとファインチューニングを併用する方針が紹介されていたので、共有します。
- Basic Tier(例:料金プランが低めの顧客): RAGを活用した共通のLLMモデルを提供
- Premium Tier(例:料金プランが高めの顧客): ファインチューニングを施した個別のLLMモデルを提供
余談:Tierに応じて共通のモデルを使うか個別のモデルを使うか決めるというこの方針は、LLMのみならず機械学習モデルにおいても適用できる考え方であるとともに、次節のサイロとプールのメリットをうまく享受し、デメリットもうまく制御できるのでとても参考になりました。
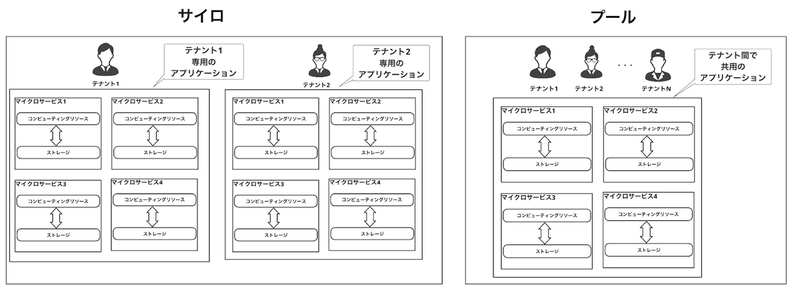
サイロとプール
全テナントで共通のモデル、または個別のモデルを提供するための基本的な概念として、下図で表されるサイロとプールというアーキテクチャパターンがあります。
サイロ
各マイクロサービスを一つのテナントが占有するパターンです。
- メリット:
- データとテナントを明確に分離できるので、情報漏洩のリスクが低いです。
- 顧客のアプリケーションの利用状況が把握しやすいため、クラウドサービスを通してアプリケーションを提供している場合、利用コストの管理が容易です。
- 他テナントによるノイジーネイバー(後述)の影響を受けません。
- デメリット: テナント数が増加すると、個別のシステム変更や運用が必要となり、管理コストが増加します。
プール
各マイクロサービスを全テナントで共有するパターンです。
- メリット: 特に多数のテナントが存在する場合、管理コストを抑えられます。
- デメリット:
- テナントごとにデータが分離していることの保証が難しく、テナントごとのコスト把握が困難です。
- 一部のテナントによる過剰なリソース利用(ノイジーネイバー)が発生し、他テナントのサービス品質に影響を与える可能性があります。
これらのパターンは排他的なものではなく、プロダクト要求や技術要件などに従いマイクロサービスごと、その中のコンピューティングリソースとストレージごとに織り交ぜるといった使い分けが現実的です。
LLMシステムを構築する際の考慮事項
個社向け、または共通のLLMを提供する際には、以下の点が重要な考慮事項となります。
テナント分離
プール(共通LLM)で提供する場合、各テナントが適切なデータのみを参照していることを保証する必要があります。
例えばRAGの場合、テナントごとにトークンを取得し、そのトークンに基づいて検索インデックスへのアクセス権限を制御するなどの仕組みを実装する必要があります(参考資料:RAG における検索システムの権限分離と評価)。
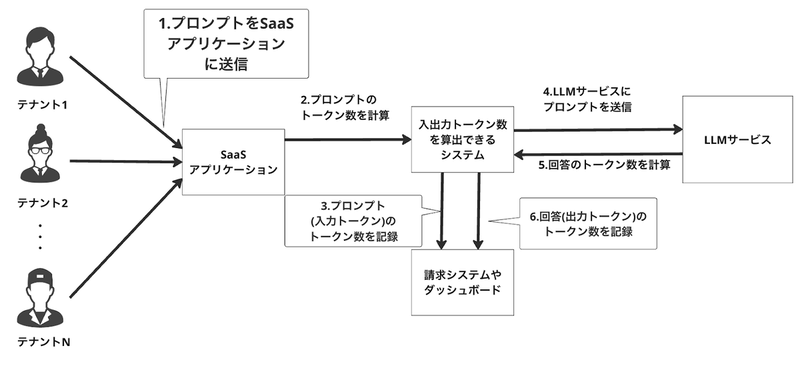
コスト計算
テナントごとのLLM利用コスト(主に入出力トークン数)を把握することは、ビジネスとエンジニアリングの両面で重要です。
- ビジネス視点: トークン利用料がSaaS利用料を上回っていないかを確認し、収益性を評価するために必要です。
- エンジニアリング視点: どのテナントが多くの負荷をかけているかを把握するために重要です。
プール構成の場合、テナントごとのコスト把握は困難であり、利用トークン数を記録する以下のような専用のシステムを構築する必要があるかもしれません。
一方、サイロ構成の場合、クラウドサービスのコンソールやダッシュボードからテナントIDを指定するといったことにより、比較的容易にコストを把握できます。
ノイジーネイバー
マルチテナントSaaSにおけるノイジーネイバーとは、少数のテナントがシステム全体のリソースを過剰に利用することで、他多数のテナントが正常にサービスを利用できなくなる現象です。
LLMにおいて、共通モデルを利用するテナントで発生しやすい傾向があります。
対策としてはスロットリング(例:テナントごとやTierごとにトークン利用量の上限を設定する)が有効になります。
まとめ
マルチテナントSaaSにおけるLLMシステムアーキテクチャの設計においては、共通のLLMモデルと個別のLLMモデルの使い分けが重要です。使い分けの基準の一つとしてSaaSの料金プランといったTierに応じた使い分けがあります。
- 共通のLLMモデル:
- 料金プランが低めのテナントに対して、RAGを利用することで個別の体験を提供できます。
- 考慮事項は、各テナントに対して適切なデータを参照しているか保証するためのアクセスコントロール、コスト把握のための専用システムの構築、ノイジーネイバー対策です。
- 個別のLLMモデル: 料金プランが高めのテナントに対して、ファインチューニングしたLLMを利用することで、個別の体験を提供できます。
- 考慮事項は、顧客ごとにモデルを作成、デプロイ、運用する必要があるため、管理が煩雑になるのを防ぐ手立てを用意しておくことです。