こんにちは、Data&Analysis部(D&A)です。
D&Aでは週1回、機械学習の勉強会を開催しており、本記事は、勉強会の内容を生成AIを活用して記事にまとめたものです。
※勉強会内容公開の経緯はこちら
※過去の勉強会は「社内勉強会」タグからもご覧いただけます。
はじめに
本記事では、以下の資料を参考にしています。
従来の異常検知モデルの異常度に関する課題
異常検知の分野において、従来の異常検出モデルが出力する異常スコアマップは、入力画像に対してピクセルレベルまたは領域レベルで異常の度合いを示します。しかし、これは実際の深刻度を反映していない可能性があるのではないか? という問題提起が本論文内でなされています。例えば、小さい変化であっても、医療分野においては見逃してはいけない初見である可能性があり、異常スコアが低いからといってその深刻度も低いとは限りません。 したがって、実際の応用においては、異常を単に「正常か異常か」として検出するだけでなく、その深刻度をレベル分けして評価する必要があると本論文内で提起されています。本論文では「レベル順に異常スコアが割り当てられるような関数を発見することがゴール」と定義されています。
MAD-Benchの構築
上記の問いと必要性に応えるため、深刻度に応じてレベル分けされた新しい異常検出データセット「MAD(Multilevel Anomaly Detection)-Bench」が構築されました。これは、従来のベンチマークでは評価が難しかった異常スコアと深刻度の整合性を評価するための基盤となります。 MAD-Benchは元々存在するデータセットを以下の条件で分割するものになります。
- 学習データをL0, L1, ..., Lnの集合に分割する
- Lはlevelを意味し、L0が正常、L1, L2, ..., Lnの順に深刻度が上昇
- L0のみで学習し、テストはL0からLnまで全てのデータを対象とする
具体的には、以下のようなデータセットが作成されました。
- Multi-Dogs-MAD
- 犬(L0)からレベルが上がるにつれて異なる犬種、猫、鳥、花へと変化します。
- MVTec-MAD
- 異常検出に特化した既存データセット(MVTec、VisA)を基に、欠陥の深刻さごとにレベルを設定しています。
- DRD-MAD (Diabetic Retinopathy Detection)
- 糖尿病性網膜症検出データセットを基に、網膜画像の所見の深刻度に合わせてレベルを設定しています。
- VisA-MAD
- 異常検知に特化したデータセットであるVisAより作成。欠陥の深刻さごとにレベルを設定しています。
- Covid19-MAD
- 胸部X線画像を基に、所見の深刻度に合わせてレベルを設定しています。
- SkinLesion-MAD
- 健康な皮膚画像と異常画像を含み、所見の深刻度に合わせてレベルを設定しています。
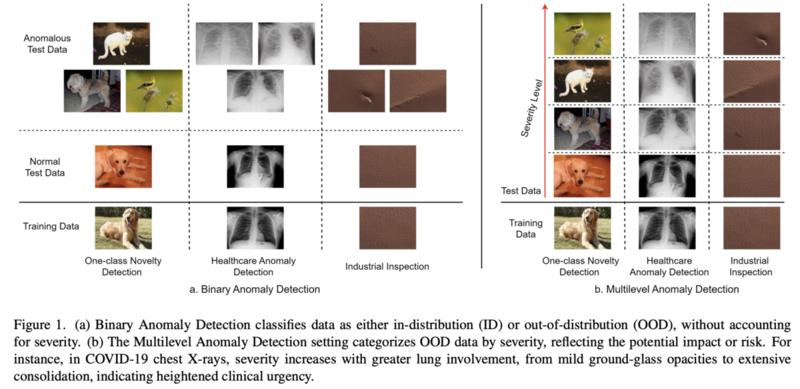
論文内ではこれらのデータセットを用いて、既存の異常検知モデル、およびMLLMベースの手法の異常検知における異常度と深刻度の関連性を調査しています。
MLLMベースの手法
3枚の正常画像とプロンプトを与えて、テスト画像を推論させます。プロンプトには以下のような情報を含みます。
- コンテキスト:画像の説明
- タスク説明:目的や潜在的な異常の説明など
- 深刻度レベル説明:こういった特徴を持った画像は深刻というような説明
- フォーマットガイドライン:0-100のスコアと理由を返して欲しいというような要望

実験内容
MAD-Benchを用いて、以下の観点で異常検出モデルを評価しています。
- RQ(Research Question)1:ベンチマークとモデルタイプ分析
- 異なる種類の異常検出モデルが、様々なアプリケーションにわたる深刻度レベルと整合した異常スコアをどの程度正確に割り当てられるか?
- RQ2:バイナリ・マルチレベル性能相関
- バイナリ異常検出(正常or異常という観点で異常を判定するタスク)でうまく機能するモデルは、マルチレベル異常検出でもうまく機能するか?
- RQ3:異常領域面積効果
- 異常領域の面積は、検出モデルによって生成される異常スコアにどのように影響するか?
- RQ4:深刻度別の検出性能
- 異常の異なる深刻度レベル間で、バイナリ検出性能はどのように変化するか?
- RQ5:正常クラス拡張
- 軽微な異常が許容され、正常クラスの一部として含まれた場合、モデルの性能はどうなるか?
- RQ6:ロバストネス分析
- データ破損の下で、異常スコアを深刻度と整合させる上で、検出モデルはどの程度ロバストか?
評価指標には以下の3つが採用されています。
- AUROC (AUC):バイナリ異常検出能力(正常か異常か)を評価する。
- C-index:異常スコアと深刻度レベルの整合性を評価する。1に近いほど整合性が高い。
- ケンドールの順位相関係数 (Ken):C-indexと同様に整合性を評価する。同じ深刻度レベル内のサンプルが完全に同じスコアを持つ場合に最大値1となる、より厳格な指標。
実験結果
ベンチマークとモデルタイプ分析 (RQ1)
VisA-MAD以外のデータセットではMLLMベースのモデルが良い性能を示すことが示されました。MultiDogs-MAD、 MVTec-MAD、 SkinLesion-MADで、より高いCおよびKenの値を持っていて、マルチレベルでの異常スコアと深刻度の整合性が高いことが示されています。つまり、深刻度が高いレベルでの異常スコアが高くなるような傾向が見られたということです。ただし、専門知識が必要なDRD-MADではMLLMベースでも性能が低くなりました。これはMLLMであっても、特定の分野においては事前知識の注入が重要であることを示していると言えます。
バイナリ・マルチレベル性能相関 (RQ2)
AUCとC-index、AUCとKenのSpearman相関係数はそれぞれ0.973、0.916と強い正の相関を持つことから、バイナリ検出性能の高いモデルは、概して異常スコアと深刻度レベルの整合性も高い傾向があるといけます。MLLMはよりその傾向があり整合性を持たせやすいようですが、バイナリ検出性能は従来のモデルに劣る場合もあります。
異常領域面積効果 (RQ3)
異常領域の面積が異常スコアに影響を及ぼすという仮説があります。つまり、深刻であるかどうかに関わらず、異常らしき部分の面積が大きいほど異常スコアが高くなってしまうという仮説です。この実験ではMAD-Benchで使用する経済的影響といった深刻度ベースと、面積ベースでの深刻度レベル(異常領域の面積に基づいて定義)で性能が比較されました。すると、従来のモデルは異常領域の面積に強いバイアスを持ち仮説通りの挙動を示します。したがって、小さいが深刻な異常を過小評価する可能性があります。ただし、MLLMベースだとこの傾向が小さく、バイアスが抑えられているようでした。
深刻度別の検出性能 (RQ4)
深刻度が高いものほど異常度とみなしたいため、期待する挙動としては、深刻度が高いほど異常スコアが高くあって欲しいものです。実験の結果から一般的に深刻度が高いものほど検出性能が上がる傾向を示しますが、一部のモデル(OCR-GAN, PNI)では隣接するレベルで逆転が見られる場合がありました。
正常クラス拡張 (RQ5)
この実験では高レベルの異常を正常データに含むほど検出性能は下がる傾向にありました。異常らしい特徴を正常として学習してしまうので当然の挙動とも言えます。しかし、MLLMを使った場合、性能を維持できるデータセットもあります。深刻度についてのコンテキストが事前に注入されていることが効いているのかもしれません。唯一DRD-MADは傾向に反し、軽微な異常を正常に含めると性能が上がりました。これは軽微な異常と正常なデータが似通っていて、軽微な異常に低い異常スコアをつけられるためと考えられます。
ロバストネス分析 (RQ6)
こちらも当然ですが、明るさ調整やノイズといったデータ破損は全てのデータセットで性能に影響を与える。特にMVTec-MADとSkinLesion-MADは影響が大きかったようです。これらのデータセットに含まれる異常の特徴とノイズが似ているからと考えられています。 MultiDogs-MADに関しては影響を受けにくいという結果になりました。これは細かい特徴よりも、より抽象度の高い特徴に依存するためと考えられます。
まとめ
MAD-Benchのような実用的な展開を見据えたデータセット作成が、現実世界を踏まえたモデルの性能評価につながるというのは面白い取り組みでした。発表者は以前外観検査に取り組んでいたこともあり、異常スコアと深刻度が一致しないことによる見逃しや過検知と言った課題は認識していましたが、MLLMを使ったアプローチでその課題を解決できそうであるというのは非常に興味深かったです。しかし、発表内では以下のような懸念も参加者から挙げられました。
- 既存の有名なデータセット(MVTecなど)がベンチマークとして使用されている場合、MLLMなどがこれらのデータセットで学習済みである可能性(データリーク)が懸念されます。
- MAD-Benchにおける深刻度レベルの具体的なアノテーション基準(例えば「経済的影響に応じて」といった記述の詳細)が不明瞭な場合があります。基準が明確でないと、結果の解釈や再現性に影響が出る可能性がある。
この手法を実業務に取り込む場合は、データセットは公開されていないもので評価することや、アノテーション基準を明確にしておくことが重要ですね。