こんにちは、柴犬がかわいい。Tech本部の前多です。
先日、弊社でApache IcebergとTrinoによる活用事例についての記事を上げました。
記事では、Icebergへのデータ投入について次の記述がありました。
- ユーザがアップロードしたCSVファイルをパースしてIcebergに保存する
- 図面の解析結果を一定間隔のバッチで受け取りIcebergに保存する
実際のところ、ファイルからIcebergへのデータ投入はサイズによっては困難なことがありました。 今回はIcebergへのデータ投入に関するTopicをお伝えします。
データ投入で発生した課題
私たちは、クエリエンジンとしてTrinoを採用しています。 データ投入の経路はCSVファイルしかないので、CSVファイルを解析して一行ごとにTrinoのInsert文を発行すれば十分だろうと考えていました。 また、TrinoのInsert分は以下のような複数行の一括投入も可能なので、それである程度効率よく処理ができるだろうと踏んでいました。
INSERT INTO iceberg.some_schema.some_table VALUES (1, 'test1'), (2, 'test2'),,,,,;
少量のデータでは、この方法でも問題はありませんでした。 しかし性能テストのために1000万件程度のデータを投入しようとし始めた時から、次の問題がでてきました。
1. 時間がかかりすぎる
テストデータの投入を前述のtrinoの複数行INSERTを使って、10行から200行の範囲でまとめて挿入する方法で当初行っていました。 10万件程度の投入はおおよそ15分程度で終わっていたので許容範囲だと思っていましたが、 100万件の投入を超えたあたりからどんどん一度のINSERTにかかる時間が伸びていくようになりました。 Icebergのメタデータファイルの増加、GCSの負荷増加、Trinoクラスタの負荷増加などさまざまな理由が考えられますが、Trinoで連続したデータ投入を行うのは難しいのではと思い始めました。
Trinoクラスタのスケールアップなどにより改善した可能性はありますが当時は後述する別の手段を採用しています。
2. Iceberg メタデータが増え続ける
Icebergはテーブル単位のレコード操作についてトランザクションのサポートがあり、トランザクションごとにデータファイルやメタデータ、マニフェストファイルが作成されます。 これは、細かいトランザクションを何度も行うとメタデータファイルが肥大化していきます。
Icebergには、古いメタデータファイルをコミット時に破棄する write.metadata.delete-after-commit.enabled というオプションがあるのですが、
これは現時点ではTrinoでサポートされていません。Issueはありますが、まだ進行中です。
数百万件のレコードを投入した時点で、メタデータファイルは何度もInsertを繰り返した結果100MBを超える状態となっているものもあり、 これがデータ投入が遅くなった要因の1つであったと考えます。 なるべく一度のトランザクションでデータをまとめて投入する、メタデータファイルをメンテナンスするなどの必要性がわかりました。
3. ファイル単位のトランザクション制御ができない
Trinoはトランザクションに関するSQLはありますがほとんどのコネクタではサポートされていません。
SQL statement support — Trino 474 Documentation
Trino Iceberg connectorも同様で、原則的にauto commitで動作します。auto commit以外を設定するとエラーになりました。 そのため、Icebergに対する複数のSQL実行に対するトランザクションはなく、Trinoでは1回のINSERTでIcebergのトランザクションとなります。
よって、ファイルの各行を分割してINSERT文を発行すると、細かいコミットが詰まれていくので、ファイルデータの途中にエラーがあって処理を停止した場合、Icebergには中途半端なデータが残ったままになります。
ただしこの仕様は事前に把握していました。 そこで、今回は投入するデータに投入元のファイルIDを持たせて、中途半端なデータは後から削除できる仕様としています。 そのため、大きな問題にはなりませんが、できるならファイル単位でIcebergへのデータ投入が成功したか失敗したかのどちらかになっているのが望ましいです。
このように、私たちのケースのようなそこそこのサイズのファイルをIcebergに投入するにあたって、Trino経由のデータ投入では扱いづらいことがわかってきました。
Trino以外の手段ではApache Sparkを使うのが王道だったと思いますが、当時Trinoに加えてSparkクラスタも構築するのは現実的ではありませんでしたし、上記全ての問題が解決するのかはわかっていませんでした。 そこで、IcebergのJava APIを使用して直接Icebergにデータを書き込むことにしました。
なお、余談ですがその時に Apache Beam® (Google Cloudのマネージドサービス、Dataflowの中身)も使えないかを見ていました。 確認したところApache BeamのIcebergサポートはバッチモードではレコード1件につき1コミットとなるようで、今回の要件にはマッチしないと判断しました。基本的にはApache Beamはストリームで扱った方が良さそうです。
Iceberg Java APIについて
Iceberg Java APIはIcebergテーブルフォーマットに従ったデータファイル、メタデータ、マニフェストファイルを作成し、Catalogと連携してファイルのコミットを行ってくれるライブラリです。 あまり解説されているサイトは少ないのですが公式や、Tarbularのブログのほか日本での事例解説があり、参考にさせていただきました。
今回解説するソースコードの全量は こちら にあります。 Docker compose, テストコードもあるので手元で試せます。
Catalogの取得、テーブルの作成
まずは、Catalogを取得します。 今回はREST Catalogを使用し、CatalogのURIやオブジェクトストレージの認証情報を設定して初期化します。
public static RESTCatalog getCatalog(String catalogUri) { var catalog = new RESTCatalog(); Map<String, String> catalogConfig = new HashMap<>(); catalogConfig.put("type", "rest"); catalogConfig.put("uri", catalogUri); //TODO, 実際の環境に合わせて設定内容を変えること catalogConfig.put("io-impl", "org.apache.iceberg.aws.s3.S3FileIO"); catalogConfig.put("s3.endpoint", "http://localhost:9000"); catalogConfig.put("s3.path-style-access", "true"); catalogConfig.put("s3.region", "us-east-2"); catalogConfig.put("s3.access-key-id", "admin"); catalogConfig.put("s3.secret-access-key", "password"); catalog.initialize("rest", catalogConfig); return catalog; }
Catalog経由でIcebergテーブルを操作します。 テーブルの取得や作成、スキーマ変更などができます。
テーブルを作る場合はスキーマやパーティションなどの定義が必要で、今回は4項目を持つスキーマを用意します。
/** 4項目を持つテーブルのスキーマの例 */ public static final Schema SCHEMA_SAMPLE = new Schema( List.of( Types.NestedField.required(1, "id", Types.UUIDType.get()), Types.NestedField.required(2, "name", Types.StringType.get()), Types.NestedField.required(3, "price", Types.IntegerType.get()), Types.NestedField.required(4, "registered_at", Types.TimestampType.withZone()))); /** name属性のハッシュ値によるパーティションの例 */ public static final PartitionSpec SAMPLE_PARTITION = PartitionSpec.builderFor(SCHEMA_SAMPLE) .bucket("name", 16).build();
Catalogにスキーマ、パーティション、テーブルプロパティなどを設定してテーブルを作成します。 テーブルのオブジェクトストレージ上のパスも自分で決めます。論理的なテーブル名と同じにしてしまうとリネームや名前の衝突などで困るため、ハッシュ値などを含めた方が良いでしょう。
// namespaceの取得 var ns = catalog.loadNamespaceMetadata(Namespace.of(namespace)); // オブジェクトストレージのテーブルのパス var location = ns.get("location") + "/" + table + "-" + UUID.randomUUID().toString().replaceAll("-", ""); var table = catalog // ネームスペース、テーブル名、スキーマの指定 .buildTable(TableIdentifier.of(Namespace.of(namespace), table), schema) .withLocation(location) // パーティション、ソートオーダーなどの指定 .withPartitionSpec(partitionSpec) .withSortOrder(sortOrder) // テーブルプロパティの指定 .withProperties( Map.of( "write.metadata.delete-after-commit.enabled", "true", "write.metadata.previous-versions-max", "100", "write.object-storage.enabled", "true")) .create();
ここまでが下準備です。次から実際にIcebergテーブルにデータを書き込んでいきます。
シンプルなデータ投入手順
Icebergテーブルはデータファイルやメタデータファイル、マニフェストテーブルから構成されています。 Java APIを使ったプログラムでは、主にデータファイルを作成します。 データファイルに連なるマニフェスファイルやコミットで生成するメタデータファイルについてはAPIやCatalogの内部で隠蔽されているので、あまり意識する必要はありません。
まずはパーティションがないテーブルのようなシンプルな実装例を紹介します。
Catalog, tableがある前提で、トランザクションを開始してAppendオペレーションを開始し、データファイルを作成するためのDataWriterを取得します。
var catalog = TableUtil.getCatalog(restCatalogUri); var tbl = TableUtil.getOrCreateTableAndNamespace( catalog, namespace, table, SampleDefinition.SCHEMA_SAMPLE, PartitionSpec.unpartitioned(), SortOrder.unsorted()); // トランザクションを開始して、Appendオペレーションを開始する。 var transaction = tbl.newTransaction(); var append = transaction.newAppend(); // データファイルのパスは自分で決める。ハッシュ、日時などを入れて衝突しないようにする。 var fileId = OffsetDateTime.now().format(DateTimeFormatter.ofPattern("yyyy-MM-dd_HHmmss")) + "_" + UUID.randomUUID(); // メタデータ類とは異なるパスに配置されるように /data を含める String filepath = tbl.location() + "/data/" + fileId + ".parquet"; // DataWriterの取得 var file = tbl.io().newOutputFile(filepath); var dataWriter = Parquet.writeData(file) .schema(tbl.schema()) .createWriterFunc(GenericParquetWriter::buildWriter) .overwrite() .withSpec(PartitionSpec.unpartitioned()) .build();
上記では、テーブルからnewTransactionでトランザクションを開始して、次にトランザクションから newAppendでAppendオペレーションを開始していますが、
オペレーションが1つだけならtableから直接Appendオペレーションを作成できます。
オペレーションの種類は こちら にあります。 Appendはデータを追加するだけの単純なオペレーションで、トランザクション競合も起きません。そのほかに削除、データ更新など複数のオペレーションがありますが、今回のケースはデータ追加だけを行いますので触れません。
興味がある方は以下の記事を参考にしてください。
データファイルのパスも自分で決める必要があります。ハッシュ値、タイムスタンプを含めて衝突を避けたり、オブジェクトストレージのパスを分散させて効率を高めたりするなどの工夫は自分で行います。
DataWriterへ、ファイルの一行ごとにParquet形式のデータに変換して書き込んでいきます。 最初に定義したテーブルスキーマのフィールドと型を一致させる必要があります。型変換についてはGitHubのコードを参照してください。
var record = GenericRecord.create(tbl.schema()); try (var lines = new JsonlReader(input)) { // data add to parquetWriter while (lines.hasNext()) { var r = lines.next(); var row = record.copy(TableUtil.convertRecord(tbl.schema(), r)); dataWriter.write(row); } }
レコードの追加が終わったら、書き込みをcloseで終了させ、その後データファイルに変換した後Appendオペレーションにデータファイルを登録します。
もし、レコードの件数やサイズに応じて複数のデータファイルを生成したい場合は、繰り返しデータファイルの生成を行なってオペレーションに登録します。
最後にAppendオペレーションのcommit、トランザクションのcommitを行うと、Catalogで競合状態を確認します。
問題なければ各種マニフェストファイルが生成、コミットされます。
これで、Icebergのデータ投入は完了です。
// writing finish, then commit data file. dataWriter.close(); var dataFile = dataWriter.toDataFile(); append.appendFile(dataFile); // commit append.commit(); transaction.commitTransaction();
データの取得、確認
ユニットテストでIcebergからデータを取得してみます。
データ取得はScanで行います。データファイル単位で取得する方法とレコード単位で取得する方法があり、ここでは後者の方法を採用します。
以下のように、IcebergGenerics.read(table) からselect, whereを指定してScanオブジェクトを取得し、Scanから1件ずつレコードを取得していきます。
var result = new ArrayList<Map<String, Object>>(); var scan = IcebergGenerics.read(table) // select, where の指定ができる //.select("id", "name") //.where(Expressions.lessThan("price", 100)) .build(); for (var i = scan.iterator(); i.hasNext(); ) { var data = i.next(); var map = new HashMap<String, Object>(); for (int k = 0; k < data.size(); k++) { var field = SampleDefinition.SCHEMA_SAMPLE.findField(k + 1); map.put(field.name(), data.get(k)); } result.add(map); }
余談ですが、通常のSQLと異なり、集計、関数、ソートといった操作や結合はサポートされていませんので、こういった操作はクエリエンジン側で行います。これらの操作がコストが高くなる理由がわかります。
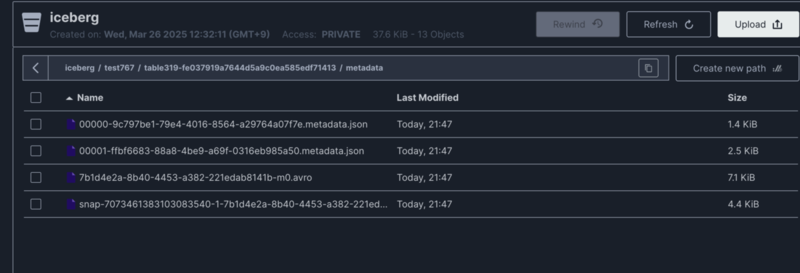
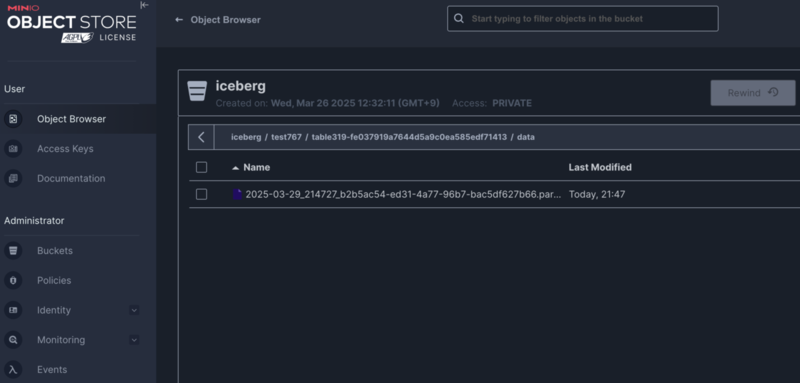
テストを実行すると、Icebergへのデータ投入とその確認が検証できます。 また、以下のようにMinioコンソールで作成されたファイルを確認できます。
メタデータファイルと、1件のデータファイルが確認できます。
また、このデータはTrinoからクエリすることももちろん可能です。
Partitionに対応したデータファイルの書き込み
前述の方法は単純で件数が少ないテーブルであれば十分ですが、一方でJava APIが提供する機能はプリミティブなものだと私は感じました。 例えば、パーティションキーごとにデータファイルを分けたり、サイズに応じてデータファイルを分割するのは自分で行う必要があります。
そういった時に役立つのが org.apache.iceberg.ioパッケージの便利クラスです。
Partitionに対応したデータファイルを作成可能な PartitionedFanoutWriter がありますのでこれを使ってみます。
以下のように、appenderFactory, outputFileFactoryを生成してこれをPartitionedFanoutWriterに渡します。
outputFileFactoryはファイルを作成する情報となるpartitionId,taskId,ファイルフォーマットを受け取り、パーティションごとに分割したデータファイルのパスに含めます。
もし対象テーブルにパーティションがない場合は、UnpartitionedWriter を代わりに使います。
ファイルサイズを指定でき、UnpartitionedWriter を使う場合でもファイルサイズでデータファイルが分割できるので便利です。
Writerを作った後のレコード挿入はこれまで通りです。
var appenderFactory = new GenericAppenderFactory(tbl.schema()); // 複数プロセスで同時に挿入する場合は、partitionId, taskIdをプロセスごとに分けないと、同名のファイルを作ってしまう。 int partitionId = 1; int taskId = 1; var outputFileFactory = OutputFileFactory.builderFor(tbl, partitionId, taskId).format(FileFormat.PARQUET).build(); final PartitionKey partitionKey = new PartitionKey(tbl.spec(), tbl.spec().schema()); // partitionの有無に応じて、 Writerの実装を分ける。 // writerはサイズを加味してデータファイルを分割し、 // さらにPartitionedFanoutWriterは、パーティションの値でデータファイルを分割する。 var writer = partitioned ? new PartitionedFanoutWriter<Record>( tbl.spec(), FileFormat.PARQUET, appenderFactory, outputFileFactory, tbl.io(), DATAFILE_MAX_SIZE) { @Override protected PartitionKey partition(Record record) { partitionKey.partition(record); return partitionKey; } } : new UnpartitionedWriter<Record>( tbl.spec(), FileFormat.PARQUET, appenderFactory, outputFileFactory, tbl.io(), DATAFILE_MAX_SIZE); var record = GenericRecord.create(tbl.schema()); try (var lines = new JsonlReader(input)) { // data add to parquetWriter while (lines.hasNext()) { var r = lines.next(); var row = record.copy(TableUtil.convertRecord(tbl.schema(), r)); writer.write(row); } }
レコードの挿入が終わったら、writerが作ったデータファイル一覧をappendオペレーションに追加してコミットします。
for (var dataFile : writer.dataFiles()) { append.appendFile(dataFile); } LOG.info("insert complete. append commit"); append.commit(); transaction.commitTransaction();
テストを実行し生成されたファイルを見ると、 /data/nnnn/nnnn/nnnn/nnnnnnnn/<field>_bucket=[hash]/ というパスでデータファイルが分割されていることがわかります。
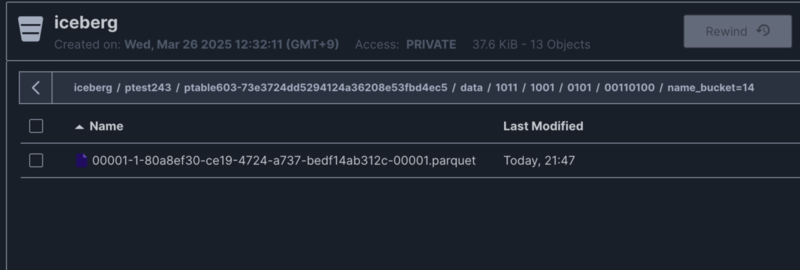
マニフェストリストファイル(avro形式)にはデータファイルの情報が含まれています。これを確認すると、4つのデータファイルに分割されていることがわかります。
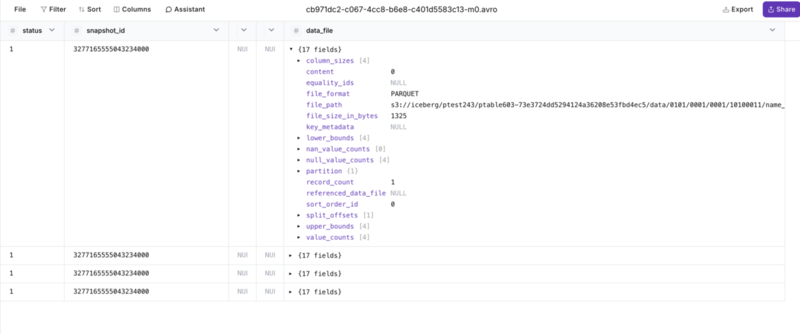
このスナップショットは、Web上でAvroを解析してくれるhttps://konbert.com/の表示内容です。
これで、Java APIを使用したPartitionありのテーブルのデータ投入もできました。
まとめ
Java APIを直接利用することで、私たちの場合以下のような改善ができました。
- 1000万件のデータ投入が、全く終わらない状況から15分に短縮できた
- 性能テストのデータ投入のための改善だったが、ユーザーファイル取り込みや他システムのデータ取り込みの高速化に流用できた
- 1ファイルのデータ投入がIceberg上の1トランザクションで実行できるようになった
一方で、Java APIの利用は、データ追記、あるいは洗い替えのための全データ削除といった単純なオペレーションで高速化が必要な場合のみに留めています。
その理由は、Java APIはデータファイル単位での操作に特化しているためです。
例えば、データの更新は、更新対象のレコードを含むデータファイルを特定し、更新後のレコードを含むデータファイルを作成し直して上書きするか無効化するといった操作が必要です。
org.apache.iceberg.ioパッケージ には変更操作をまとめてくれるような機能がありそうですが、それでも難しい操作であることには変わりはなく、このような場合はSparkやTrinoで抽象化された仕組みを使った方が良いでしょう。
以上です、クエリエンジンの仕組みと気持ちがちょっとわかるようになりました。